MapReduce v1的不足
- Jobtraker受内存限制,导致扩展性受限。因为其需要存储每个作业的信息。另一方面,其采用粗粒度的锁导致心跳时间边长。
- 中心化架构的通病,一旦Jobtraker崩溃,会导致整个集群崩溃。
- 以mapreduce为中心,MapReduce不支持其他的编程模型,如机器学习,图算法
- tasktraker的Map 槽和Reduce槽是固定的,不是动态分配的资源。
Yarn(yet another resource negotiator)
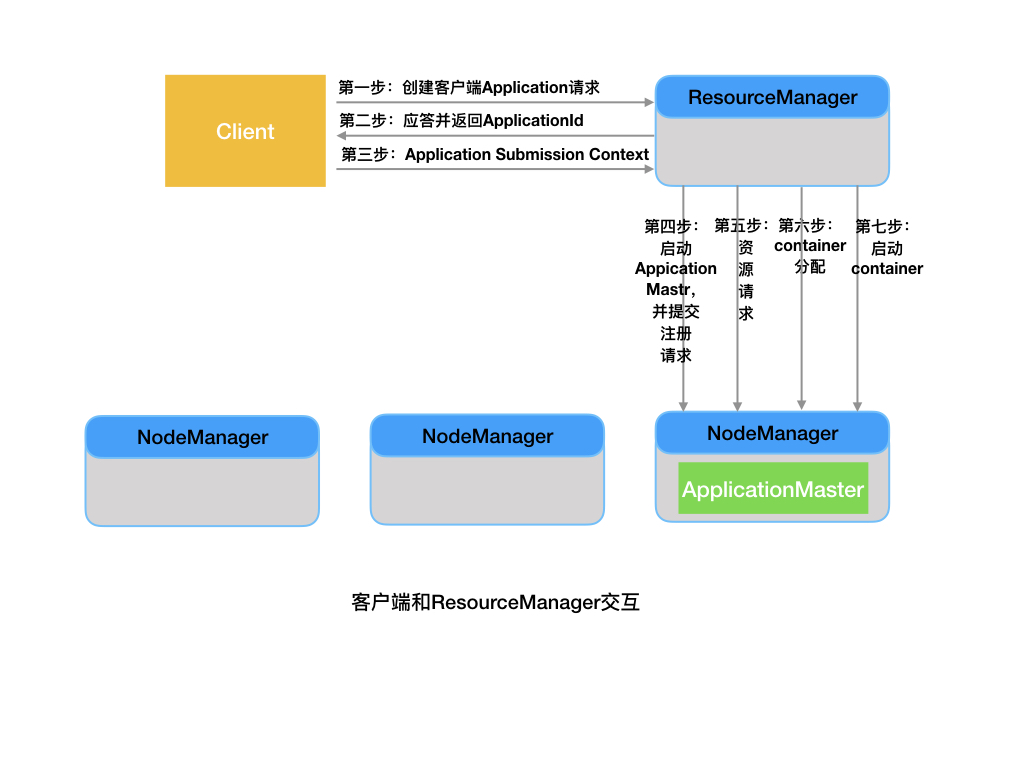
ResurceManager(RM):
- 一个纯粹的调度器,专门负责集群中可用资源的分配和管理;
- 根据应用程序要求分配可用资源;
- 有可拔插的调度器(公平调度还是容量调度等)。
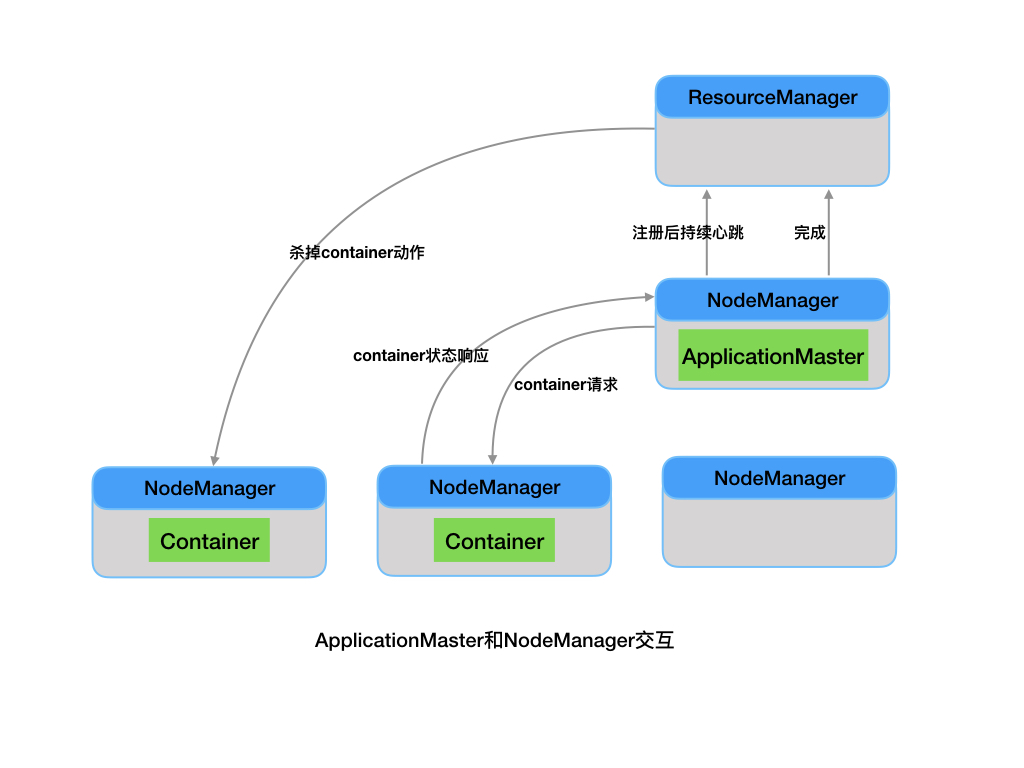
App Master (ApplicationMaster(AM)):
- 与RM协调资源与NA来协同工作来共同执行和监控container以其他们的资源消耗
- 与RM协商获取合适资源的container,并获取其状态,监控其进程。
- 可以为一个用于提供一个AppMaster,也可以为一组提供AppMaster,如pig, hive.
Container :
- 分配给具体应用的资源抽象表现形式,包括内存、cpu、disk
NodeManager(NM)
- 负责节点本地资源的管理,包括启动应用程序的Container,监控它们的资源使用情况,并报告给RM
客户端(Client)
- 是集群中一个能向RM提交应用的实例,并且指定了执行应用所需要的AM类型
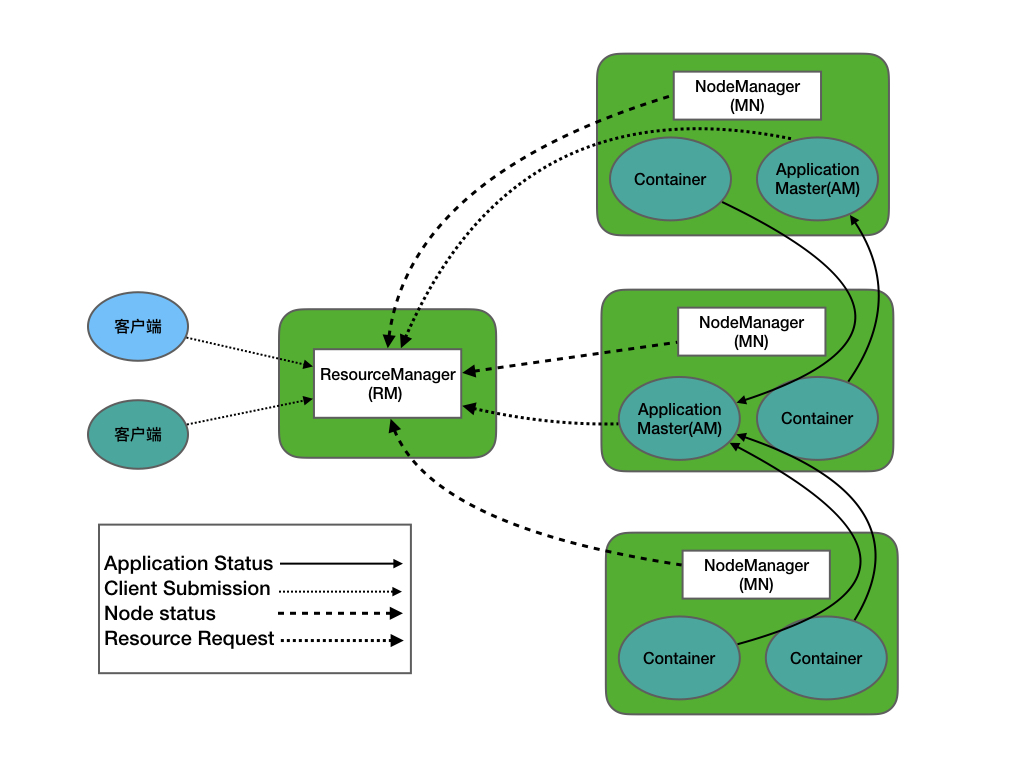
数据本地化的实现
数据节点和节点管理器NM运行在同一节点,保证数据块在本地。
客户端与资源管理器交互
应用管理器与节点管理器交互