1. 什么是MapReduce?
简言之,mapreduce 一种可用于数据处理的以数据为中心(数据本地化)分布式编程模型,采用的是一种分而治之的思想,分为map和reduce两个阶段。
Map: 将一个Job分解为若干个task
Recude: 完成分解的task,并且汇总结果。
eg: 图书馆以书架进行图书清点。这里“以书架为单位”,就是map的过程,分配任务。而每个书架安排人来清点并且汇总最后的清点结果就是Reduce的过程。
2.为什么要使用MapReduce(相对于关系型数据库)?
a) 目前的发展趋势是硬盘寻址效率的提升(关系型数据库)的发展要远远逊色与网络传输速率的发展(分布式的MapReduce).
b) MapReduce 相较于传统的关系型数据库 更适合处理不规范的半结构化数据或者非结构话数据。
下表为关系型数据库与MapReduce的对比, 目前两者界限趋近模糊
| 传统关系型数据库 | MapReduce | |
| 数据大小 | GB | PB |
| 访问 | 交互式、批式处理 | 批式处理 |
| 更新 | 多次读写 | 一次写入多次读取 |
| 结构 | 静态模式 | 动态模式 |
| 完整性 | 高 | 低 |
| 横向扩展 | 非线性 | 线性 |
3.MapReduce的体系结构
MapReduce与hdfs一样使用master/slave结构。
*master/slave结构:一个基于分而治之思想设计模式,将一个任务(原始任务)分解为若干个语义等同的子任务,
并由专门的工作者线程来并行执行这些任务,原始任务的结果是通过整合各个子任务的处理结果形成的。
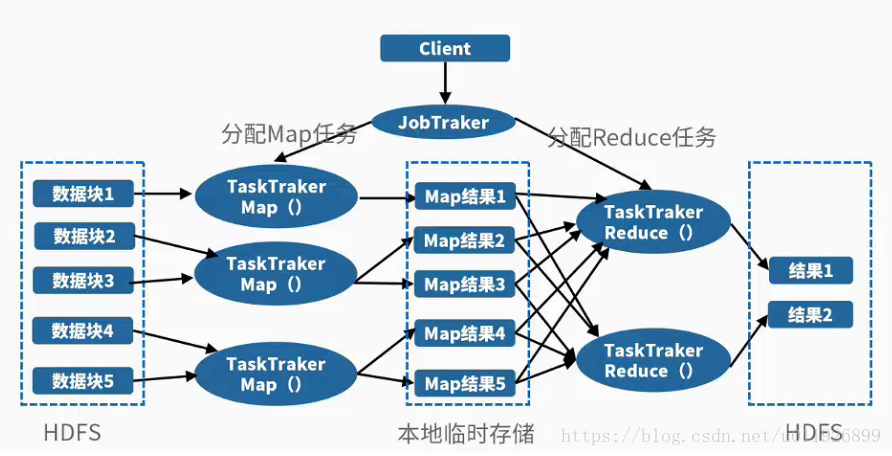
a). 客户端: 提交mapreduce作业
b). jobtracker: 协调作业的运行,负责任务的分配
c). tasktracker: 运行划分后的任务
d). hdfs分布式文件系统,用于不同实体间共享作业
-> submitJob()-向jobtraker提交作业
- 向jobtracker请求一个任务id
- 作业输出路径以及输入分片正确性检查,如发现异常则不提交任务
- 拷贝作业所需资源(jar、配置文件)到jobtracker的文件系统,并且以作业号命名。可以存在多个副本,供tasktraker访问。
-> 作业初始化
- jobtraker将接受到的job交由作业调度器(默认fifo调度,公平调度,容量调度器)进行初始化。
- 作业调度器读取jobtraker计算的分片信息,并未每一个分片建立一个map以及设定的reduce任务。
-> 任务分配
- tasktraker会定期发送“心跳”,告诉jobtraker其状态(是否存活,是否空闲等),心跳是两者见的一种通信机制。
- tasktraker有固定的任务槽,可以放置n个map, m个reduce(由机器本身的计算能力以及内存决定),并且会优先处理map任务槽, 保证在处理reduce前, map任务槽是满载的。
- 对于reduce任务,jobtraker会直接从任务队列中取一个进行执行,不考虑数据本地化问题。对于map任务,jobtraker则会尽可能将map分配到与输入分片(数据)较为接近的地方,即数据本地化。
-> 运行作业
- tasktraker通过hdfs实现jar本地化,并解压到新建的任务文件夹
- tasktraker为taskrunner,启动一个新的jvm,避免主进程中的tasktraker崩溃。(存在jvm重用)
- 子进程会定时通知父进程任务进度。
-> 任务进度更新
- Map进度,即所处理输入所占百分比。
- Reduce进度,较复杂,但是还会考虑所处理输入所占百分比。
- tasktraker会没三秒检查作业进度标志,并每5秒(最小)发送给jobtraker. 最后由jobtraker汇总并生成全局视图。
-> 任务结束
- 任务结束后jobtraker将作业状态设置为成功,并且最后清空作业状态中间文件等。
-> 失败处理
- 任务失败:释放任务槽运行其他任务
- tasktraker失败:若tasktracker崩溃则从等待任务的tasktraker池中移除。对于未完成的任务,则让其重新运行map,进行中的reduce会被重新调度。若tasktraker失败的任务数大于阈值,则拉入黑名单(重启脱离黑名单)。
- jobtraker失败:最严重的失败,无处理机制,概率比较低