In [42]: df = pd.DataFrame({'data1': np.random.randn(5),
...: 'data2': np.random.randn(5)})
In [43]: df
Out[43]:
data1 data2
0 -2.332263 0.477812
1 -0.715245 0.294528
2 -0.933356 -0.396173
3 0.757402 1.571117
4 2.710012 0.959990apply()
apply()会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
用DataFrame的apply方法,可以将函数应用到由各列或行所形成的一维数组中。
In [44]: f = lambda x : x.max()-x.min()
In [45]: df.apply(f)
Out[45]:
data1 5.042275
data2 1.967290
dtype: float64
In [46]: df.apply(f,axis=1)
Out[46]:
0 2.810074
1 1.009774
2 0.537183
3 0.813714
4 1.750022
dtype: float64applymap()
用DataFrame的applymap方法,可以将函数应用到元素级的数据上。
In [47]: f = lambda x : x+1
In [48]: df.applymap(f)
Out[48]:
data1 data2
0 -1.332263 1.477812
1 0.284755 1.294528
2 0.066644 0.603827
3 1.757402 2.571117
4 3.710012 1.959990Series也有一个元素级函数应用的方法map
In [49]: df['data1']
Out[49]:
0 -2.332263
1 -0.715245
2 -0.933356
3 0.757402
4 2.710012
Name: data1, dtype: float64
In [50]: df['data1'].map(f)
Out[50]:
0 -1.332263
1 0.284755
2 0.066644
3 1.757402
4 3.710012
Name: data1, dtype: float64agg()
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。内置函数名需要用引号。
In [52]: df.agg(['mean','sum'])
Out[52]:
data1 data2
mean -0.102690 0.581455
sum -0.513449 2.907274| 函数 | 说明 |
|---|---|
| count | 分组中非Nan值的数量 |
| sum | 非Nan值的和 |
| mean | 非Nan值的平均值 |
| median | 非Nan值的算术中间数 |
| std,var | 标准差、方差 |
| min,max | 非Nan值的最小值和最大值 |
| prob | 非Nan值的积 |
| first,last | 第一个和最后一个非Nan值 |
transform()
transform会将一个函数应用到各个分组,然后将结果放在适当的位置. 如果各分组产生的标量值,则该标量值会被广播出去。
people=pd.DataFrame(np.random.randn(5,5),
columns=list('abcde'),
index=['Joe','Steve','Wes','Jim','Travis'])
people
key=['one','two','one','two','one']
people.groupby(key).mean()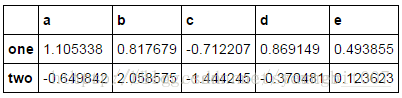
people.groupby(key).transform(np.mean)