最近在看李航的统计学习方法,边看边做点笔记。本文,包括后续写作纯属个人浅见。
模型学习目标是选择期望风险最小的模型,但期望风险最小模型需要用到联合分布概率 P(X,Y)求取条件概率分布 P(Y|X),从而获取预测结果,计算损失。然而,联合概率分布未知,导致监督学习成为一个病态问题。
在训练集, 假设空间以及损失函数已知的情况下,期望风险为训练样本损失均值。根据大数定理,当样本容量足够大的时候,经验风险趋近于期望风险(这是前提条件)。既然两个趋近,那是不是可以用经验风险来表示期望风险呢? 原理上是可行的,只需要满足前提条件(前提条件如何满足完全是未知的)就基本可行。但现实中样本数量是有限的,直接用经验风险代表期望风险就不太合适,经验风险逼近期望风险的效果不是特别好。因此需要对经验风险进行矫正,这就引入今天要说的监督学习两大策略:经验风险最小化和结构风险最小化。
经验风险最小化策略认为:经验风险最小的模型就是最优模型,求解最优化问题:

注意了,敲黑板!!!
现实问题中,绝大多数经验风险最小化问题都是极大似然估计(Maximum Likelihood Estimate,MEL)问题。若模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化等价于极大似然估计。
极大似然估计(在此参考:点击打开链接)是一种参数估计的方法,即已知样本估计出模型参数。极大似然估计是频率学派的一种方法(与贝叶斯学派的极大后验估计对应),频率学派认为模型的参数是确定的,只是不知道而已,所以可以通过样本推断出模型参数。似然函数P(X|θ)就是假设已知参数θ的情况下得到观察样本X的概率,而MLE的初衷就是选择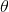

定义了似然函数,再由最大似然估计法,从给定 X,挑选合适的θ使似然函数值最大。当样本数量小的时候,获知的参数θ 只适用于当前分布数据集。而预测的数据集分布未知,利用模型学习获取的θ 往往不能完全表达未知分布的测试集,这样就造成模型对训练集拟合效果很好,而测试集拟合效果差的现象,我们就称该现象为过拟合现象。
样本量小,不仅容易使极大似然估计过拟合,而且不满足经验风险逼近期望风险的前提条件。因此, 在现实问题中,引入结构风险最小化问题来对经验风险最小化进行约束。结构风险最小化相当于一个正则项,用来表示模型复杂度的正则项或者惩罚项(结构风险最小化可以很好的防止模型过拟合)。风险最小化函数:

求解最优化问题,即可实现模型寻优。