本篇文章将会介绍用Python分析银行定期存款产品目标客户的确定详细建模细节,业务框架分析以及模型的选择与评估分析参见上一篇文章:
银行定期存款产品目标客户的确定——基于逻辑回归(建模前分析)
1.导入各种模块并读取数据:
2.数据预处理:
维规约:在之前的分析中基于业务知识最终选定了8个协变量,1个目标变量,3072个样本用于分析,分别是:
Age:年龄;job:工作类型(行政人员,管理人员,保姆,企业家,学生,蓝领,个体户,技师,退休,服务人员,失业,未知);marital:婚姻状况(已婚,离婚,单身);education:教育水平(初等,中等,高等,未知);default:信用违约(是,否);balance:平均年收支余额;housing:住房贷款(是,否);loan:个人贷款(是,否);response:客户是否投资定期存款(是,否)。
经分析发现数据没有重复,现处理缺失值和异常值,用可视化技术进行探索性分析(此处连续变量只有两个):
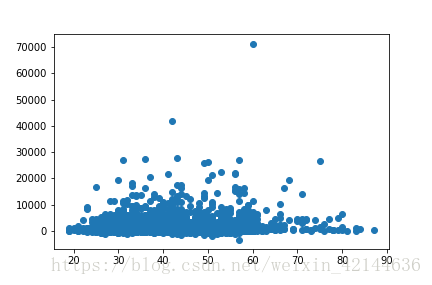
可以看出对于变量age不存在异常值,对于变量balance有少数异常值,而这样的异常值是有价值的,将这两个异常值取出另存,不能删除。

在逻辑回归模型建立过程中,需要将分类变量变为哑变量,这会增加变量的数量,注意到变量job取值过多,将其进行分类,减少取值个数。并填补缺失值,过滤出需要的客户。分析的代码如下:

3.针对各个变量进行探索性分析:







从上面的可视化分析中可以看出,比较响应与否两个群体的各个特征,可以看出信用违约与否对于产品的购买区分度不大,年龄较大的客户倾向于购买定期存款产品,除此之外,购买定期存款产品的客户教育水平较高,大部分没有房贷,白领工作者多于蓝领工作者,离异或丧偶的多于结婚的。
4.建立模型:
探索性分析结束,现在开始建立模型,需要将分类变量转换为哑变量,Python里面有专门的语句进行处理,代码如下:


得到模型结果如下:

可以看到里面多了一列,pred_logit_prob,这就是用建立的模型对每个样本预测的响应的概率。
接下来进行划分概率截止点,用混淆矩阵和提升图辅助划分。

由上可以看出客户最大响应概率为32.34%,这是普遍的广告投放效果的特性,也就是客户响应率不高,以0.3为概率截止点,分类的准确率可达到90.90%,但是却只捕获了一个客户,所以不能以分类准确率作为概率截断点的标准。
将样本按概率从大到小排序,等频率将样本分箱,计算每个箱中概率平均值,计算相对于随机分类器,逻辑回归分类器分类效果。这里分10个箱,每个箱中由大概185个客户,找到提升率大于1的客户分箱,相对应的概率就可以作为截止点。

可以看出,第四个分箱对应的概率就是所需的概率截止点,由下图得出概率截止点大概为11.08%,

计算混淆矩阵:

分类正确率达到71.34%,还挺高的,嘻嘻......
将逻辑回归及提升值的代码给出如下:
filter_offer = bankwork['response'].map(lambda d: d == 1)
#做出响应的客户占总客户的比例(随机分类器)
random_classifier = len(bankwork[filter_offer]) / len(bankwork)
print('\nBaseline proportion of clients responding to offer: ',\
round(random_classifier,5), '\n')
print('\n Logistic Regression Performance (0.10 cutoff)\n',\
'Percentage of Targets Correctly Classified:',\
100 * round(eval.evaluate_classifier(bankwork['pred_logit_10'],\
bankwork['response'])[4], 3),'\n')
decile_label = []
for i in range(10):
decile_label.append('Decile_'+str(10 - i))
prediction_deciles = pd.qcut(bankwork.pred_logit_prob, 10, labels = decile_label)
decile_groups = bankwork.response.groupby(prediction_deciles)
print(decile_groups.mean().sort_index(ascending=False))
#计算提升值
lift_values = decile_groups.mean().sort_index(ascending=False) / random_classifier
print('\nLift Chart Values by Decile:\n', lift_values, '\n')
ax=lift_values.plot()
plt.grid()
# 设置11.08%的概率截止点,在bankwork中加入一列,用0,1代表是否概率>11.08%
bankwork['pred_logit_11.08'] =bankwork['pred_logit_prob'].apply(lambda d: prob_to_pred(d, cutoff = 0.10))
print('\nConfusion matrix for 0.1108 cutoff\n',\
pd.crosstab(bankwork.pred_logit_11.08, bankwork.response, margins = True)) 5.反思与总结:
逻辑回归模型的使用注意点如下:
(1)逻辑回归是一种广义线性模型,线性模型的鲁棒性很差,易受异常值的影响;
(2)需要考虑特征之间的相关性,处理多重共线性的问题;
(3)Python中的逻辑回归模型不能自主处理缺失值,需要对缺失值进行处理;
(4)由于逻辑回归是对概率进行建模,所以对样本容量要求比较严格;
(5)大部分人对于分类任务会直接使用逻辑回归,不仅可以预测类别,还能得到样本属于某类别的概率,但是逻辑回归的原理使用线性模型去逼近概率比值的对数,但是这个对数与属性值之间就一定呈现线性关系?也有可能呈现非线性关系。(在数学上有一个定理:任何连续的非线性函数都能用多项式函数去逼近)。
本项目的分析到此为止,有什么不足的地方请大家在文章下方评论补充。