对于探索性数据分析来说,做数据分析前需要先看一下数据的总体概况,pandas_profiling工具可以快速预览数据。
1、pandas-profiling安装与调用
pip install pandas-profiling
import pandas as pd
import pandas_profiling2、导入数据
data=pd.read_csv("model.csv")3、直接查看
pandas_profiling.ProfileReport(data)4、数据概览
4.1总体数据
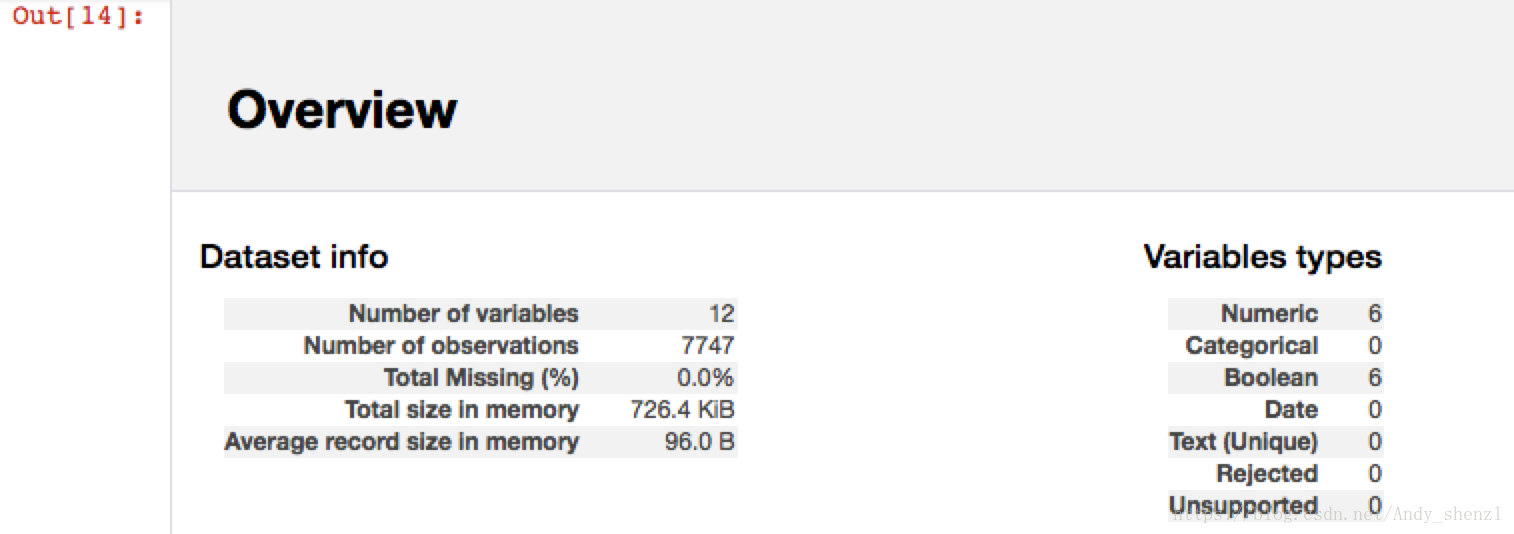
首先是数据集信息:
变量数(列)、观察数(行)、数据缺失率、内存;
数据类型的分布情况
4.2警告信息
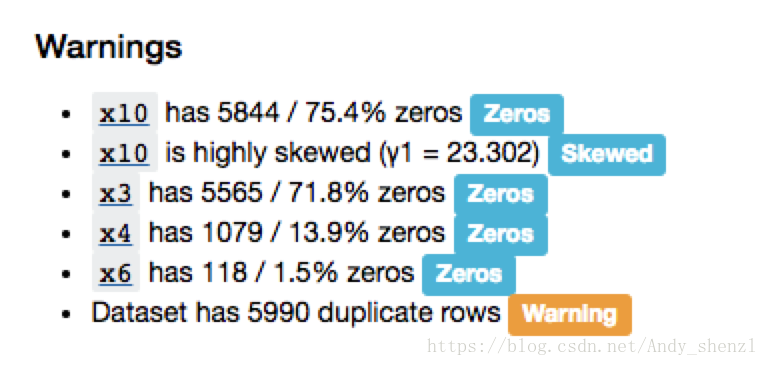
主要包括以下信息:
- 要点:类型,唯一值,缺失值
- 分位数统计量,如最小值,Q1,中位数,Q3,最大值,范围,四分位数范围
- 描述性统计数据,如均值,模式,标准差,总和,中位数绝对偏差,变异系数,峰度,偏度
4.3单变量描述
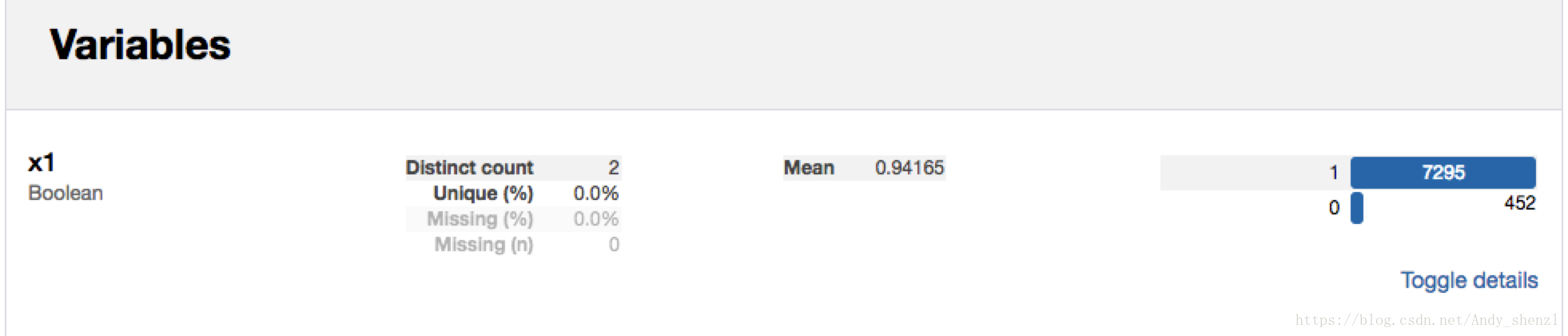
以此对每个变量进行描述解析
4.4相关性分析
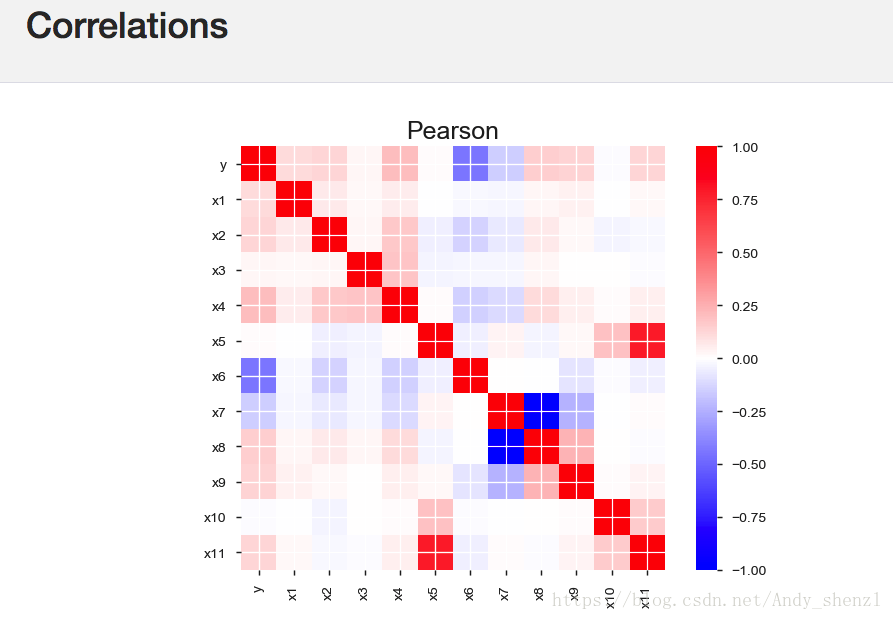
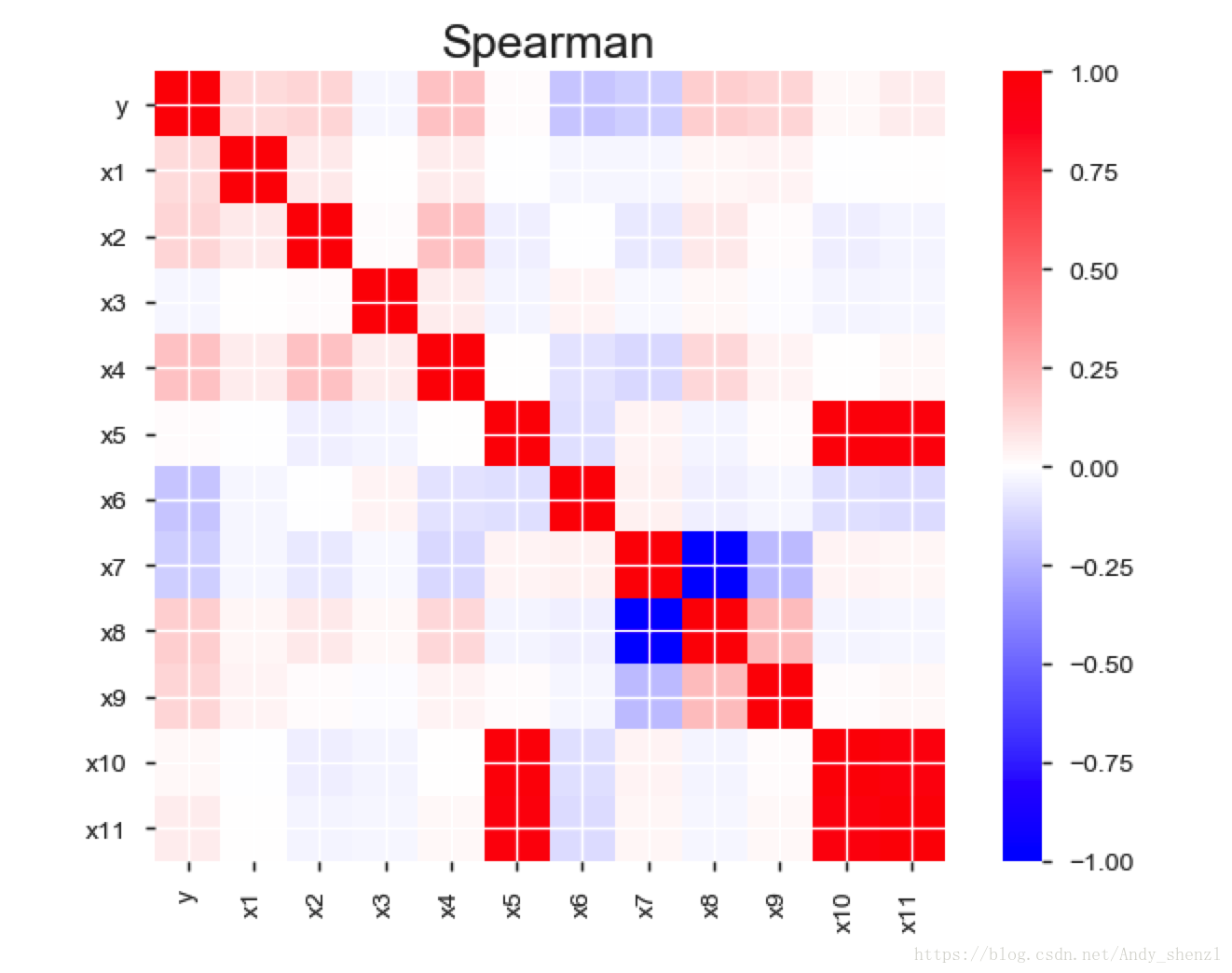
- 相关性突出高度相关变量,Spearman和Pearson矩阵
5、生成HTML报告文件
profile = pandas_profiling.ProfileReport(data)
profile.to_file(outputfile = "output_file.html")
保存在默认文件夹,也可以自己指定路径。