原理:
MHA(Master High Availability)是现在解决mysql高可用的一个相对成熟的方案
它是由两部分组成,管理端(master manager)和节点端(node manager),管理端可以单独布置在一台机器上,整个mysql主从集群就是它的各个节点,
管理端对所有节点进行监控,当master宕机之后,管理端会根据自己配置文件里的设定,将某一个从节点升为主节点,(如果没有设置,它会自己比 对,将最新数据的节点升为主节点),然后将其他节点自动指向提升上来的新的主节点,在提升的过程中,所有结点之间必须可以无密码ssh连接,管理端可以对 所有的节点ssh无密码连接.
在MHA自动故障切换的过程中,如果宕掉的 master 无法ssh连接上,则无法同步最新的二进制日志,也就无法获得最新的数据,造成数据丢失,因此,为了避免这中情况发生,MHA一般配合半同步复制.可以最大程度的保存数据.
为了避免在更换主节点时同步日志出错(pos模式下更换节点,日志同步会出错),我们开启GTID模式
目前MHA支持一主多从,整个MHA架构最少有三个节点,一台master 一台slave做备用master 一台slave只做同步,当然,为了充分利用资源,集群可以做读写分离(master做写操作,slave做读操作)
节点:
server1: 172.25.6.1 master master-node
server2: 172.25.6.2 slave master-node
server3: 172.25.6.3 slave master-node
server4: 172.25.6.4 master-manager
Mysql 安装(server1,2,3)
1、安装mysql
tar xf mysql-5.7.17-1.el6.x86_64.rpm-bundle.tar
yum install -y mysql-community-client-5.7.17-1.el6.x86_64.rpm mysql-community-common-5.7.17-1.el6.x86_64.rpm
mysql-community-libs-compat-5.7.17-1.el6.x86_64.rpm mysql-community-libs-5.7.17-1.el6.x86_64.rpm mysql-community-server-5.7.17-1.el6.x86_64.rpm
/etc/init.d/mysqld restart
grep "temporary password" /var/log/mysqld.log ###临时密码 localhost:后面就是密码
mysql_secure_installation ###初始化,密码必须8位数以上,而且大小写字母数字及特殊符号 2、设置server-id(server1,2,3)
vim /etc/my.cnf
server-id=2 ###2的32次方减 1,唯一标识符,3 个都不一样(随意)
log-bin=mysql-bin
gtid_mode=ON
enforce-gtid-consistency=true
/etc/init.d/mysqld restart ###3 台都重启
半同步复制安装
1、在1,2,3中授权
mysql> grant REPLICATION SLAVE on *.* to repl@'172.25.6.%' identified by 'Guodong+0306';
mysql> show master status;2、在1,2,3启动二个线程(在1中将2,3设置为master,在2中将1,3设置为master,在3中将1,2设置为master)
mysql> change master to master_host='172.25.6.1',master_user='repl',master_password='Guodong+0306',master_log_file='mysql-bin.000001',master_log_pos=446; ###master_log_pos:为 master 的 position
mysql> start slave;
mysql> show slave status\G; ###查询的信息这 2 个为 yes
Slave_IO_Running: Yes
Slave_SQL_Running: Yes 
3、开启master(1,2,3都做)
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
mysql> show status like 'Rpl_semi_sync_master_status'; ###查询主是否开启成功
+-----------------------------+-------+
| Variable_name
| Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_status | ON
|
+-----------------------------+-------+4、开启slave(1,2,3都做)
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> SET GLOBAL rpl_semi_sync_slave_enabled = 1;
mysql> STOP SLAVE IO_THREAD;
mysql> START SLAVE IO_THREAD;
mysql> show status like 'Rpl_semi_sync_slave_status'; ###查询从是否开启成功
+----------------------------+-------+
| Variable_name
| Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON
|
+----------------------------+-------+
MHA manager 通过 SSH 访问所有的 node 节点,各个 node 节点也同样需要通过 SSH 来相互发送不同的 relay log文件,所以有必要在每一个node和manager上配置SSH无密码登陆。MHAmanager可通过 masterha_check_ssh 脚本检测 SSH 连接是否配置正常。
SSH 无密码连接
1、生成rsa key pair
ssh-keygen

2、server1中把公钥和私钥发送给 server1,2,3
scp /root/.ssh/id_rsa /root/.ssh/id_rsa.pub [email protected]|2|3:/root/.ssh/3、server1,2,3 执行
ssh-copy-id -i /root/.ssh/id_rsa.pub root@自身IP4、成功安装后,会在/usr/bin 目录下生成如下一系列命令工具
ll /usr/bin/masterha_*安装 MHA
1、安装节点(1,2,3,4 都要安装):
yum install -y mha4mysql-node-0.56-0.el6.noarch.rpm2、依赖性—需要安装的包
perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
perl-Email-Date-Format-1.002-5.el6.noarch.rpm
perl-Log-Dispatch-2.27-1.el6.noarch.rpm
perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
perl-MailTools-2.04-4.el6.noarch.rpm
perl-MIME-Lite-3.027-2.el6.noarch.rpm
perl-MIME-Lite-HTML-1.23-2.el6.noarch.rpm
perl-MIME-Types-1.28-2.el6.noarch.rpm
perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
perl-Params-Validate-0.92-3.el6.x86_64.rpm
perl-TimeDate-1.16-13.el6.noarch.rpm3、安装manager
yum install -y mha4mysql-manager-0.56-0.el6.noarch.rpm配置 MHA
创建配置文件及其目录:
mkdir /etc/mha
vim /etc/mha/mha.conf
配置文件如下:
[server default]
manager_workdir=/usr/local/mha
#设置manager的工作目录
manager_log=/usr/local/mha/mha.log
#设置manager的日志
master_binlog_dir=/var/lib/mysql
#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
user=root
#设置监控用户root,这个用户在mysql里存在
password=Guodong+0306
#设置mysql中监控用户的那个密码
ping_interval=1
#设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp
#设置远端mysql在发生切换时binlog的保存位置
repl_user=repl
#设置同步用户mha
repl_password=Guodong+0306
#设置mha的密码
ssh_user=root
#设置ssh的登录用户名
[server1]
hostname=172.25.6.1
port=3306
[server2]
hostname=172.25.6.2
port=3306
candidate_master=1
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=172.25.6.3
port=3306
#no_master=1 #一定不会是master


验证 ssh 通讯:
masterha_check_ssh --conf=/etc/mha/mha.conf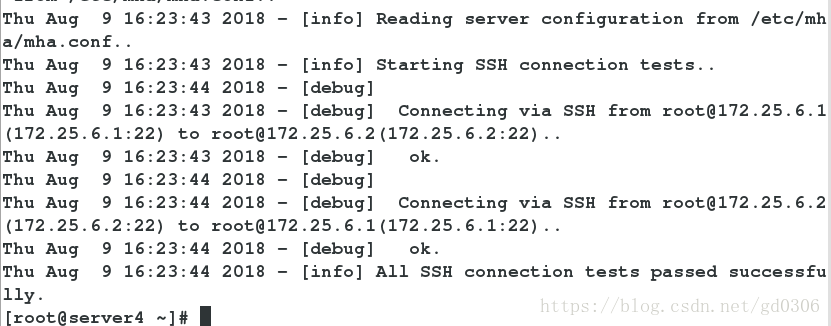
报错解决()
(1)报错权限不对
[root@server1 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
[error][/usr/share/perl5/vendor_perl/MHA/Server.pm, ln393] server3(172.25.6.4:3306)(2)解决方案:开启 root 和 repl 用户的权限 (1,2,3里面都做)
mysql> grant all privileges on *.* to 'root'@'%' identified by 'Guodong+0306' with grant option;
mysql> grant all privileges on *.* to 'repl'@'%' identified by 'Guodong+0306' with grant option;
mysql> flush privileges;
server4:开启MHA Manager监控
[root@server1 server4]# nohup masterha_manager --conf=/etc/mha/mha.conf --remove_dead_master_conf --ignore_last_failover < /dev/null > /use/local/mha/mha.log 2>&1 &
[1] 1628
[root@server1 server4]# masterha_check_status --conf=/etc/mha/mha.conf
server4 (pid:1628) isrunning(0:PING_OK), master:server1
5、测试
(1)master(server1) down 掉
/etc/init.d/mysqld stop(2)在 server3查看slave状态
在manager里面查看:
