问题提出:
人脸验证在LFW数据集上做的很好,但是在存在大量视角、分辨率、图像质量变化和遮挡时,验证效果并没有那么理想。主要是两个原因造成的:
数据质量不均衡:目前常用的人脸识别公开训练集图像大都是高清、正脸人脸图像,很少包含无限制条件下的难以识别的人脸图像。现在大多数的DCNN模型,使用softmax loss做分类,使用前面提到的训练集训练出来的模型,对高质量的图像过拟合,但对难以识别的图像欠拟合。
softmax loss不适合做人脸验证任务:softmax loss只是保证学习到的特征不用做任何matric learning的时候,能够使得人脸特征可分。但是softmax loss并没有保证positive pairs学到的特征足够近而negative pairs学到的特征足够远,因此不是很适合去做人脸验证任务。另外一点是,softmax loss是要最大化给定的mini-batch中所有样本的条件概率。但是,由于高质量的人脸图像的特征范数较大,低质量人脸图像的特征范数较小,如果直接让容易验证的样本的范数比较大,让难以验证的样本的范数较小,则可以得到最小化的softmax loss。因此,如果直接使用softmax loss只关注了mini-batch中高质量的人脸图像,而忽略了该mini-batch中较少的低质量的人脸图像。
实验验证:
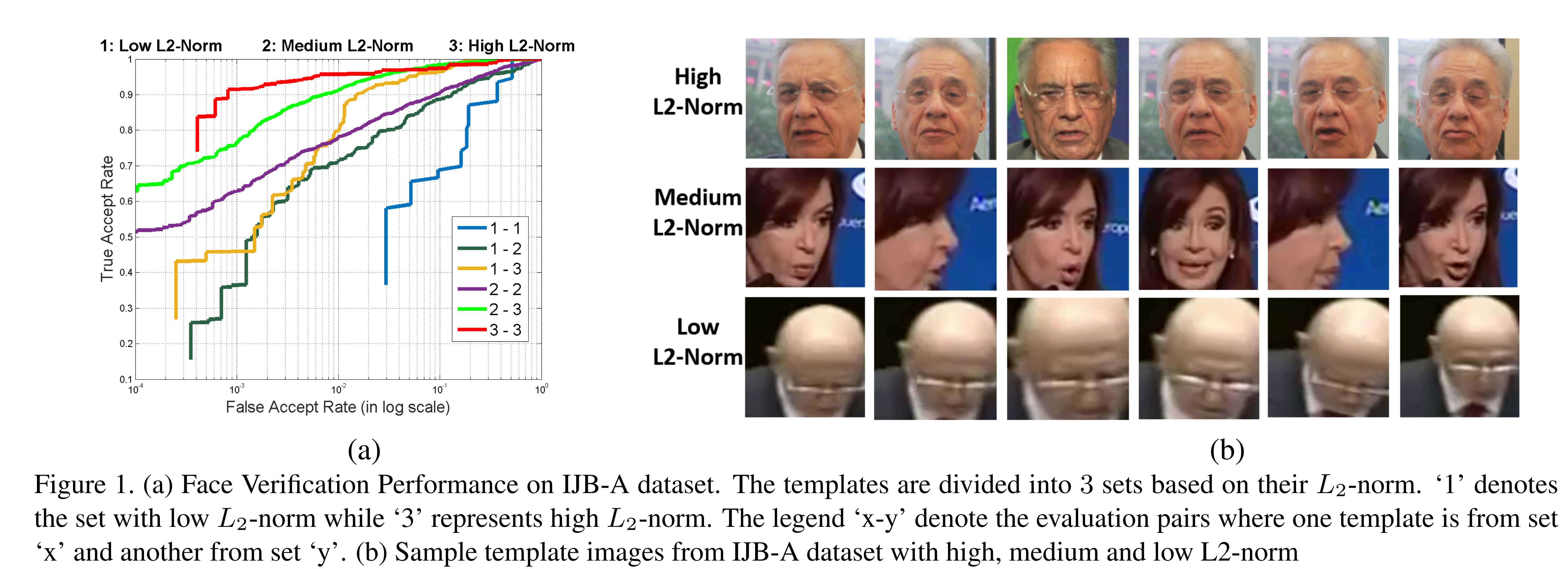
由于模型使用常用的包含大量高质量、少量低质量的人脸图像集进行训练,因此只关注了高质量的训练图像,忽略了低质量训练图像。在验证时,如上图左侧小图所示,低质量的图像对验证准确率最差,而高质量的图像对验证准确率最高。证明了作者上述观点。
解决办法:
提出L2-Softmax损失函数,限制训练过程中各图像提取的特征的范数为常数。

好处:
由于损失函数使得所有人脸图像的特征的范数大小相同,所以softmax loss不会只偏重于对easy samples的学习,也会对diffcult samples进行学习;
还是由于特征的范数大小一致,所以所有的特征样本的特征都分布于一个固定半径的超球面上,此时最小化softmax loss等价于最大化positive pairs之间的余弦相似度,同时最小化negative pairs之间的余弦相似度。
在MNIST数据集上验证L2-softmax:
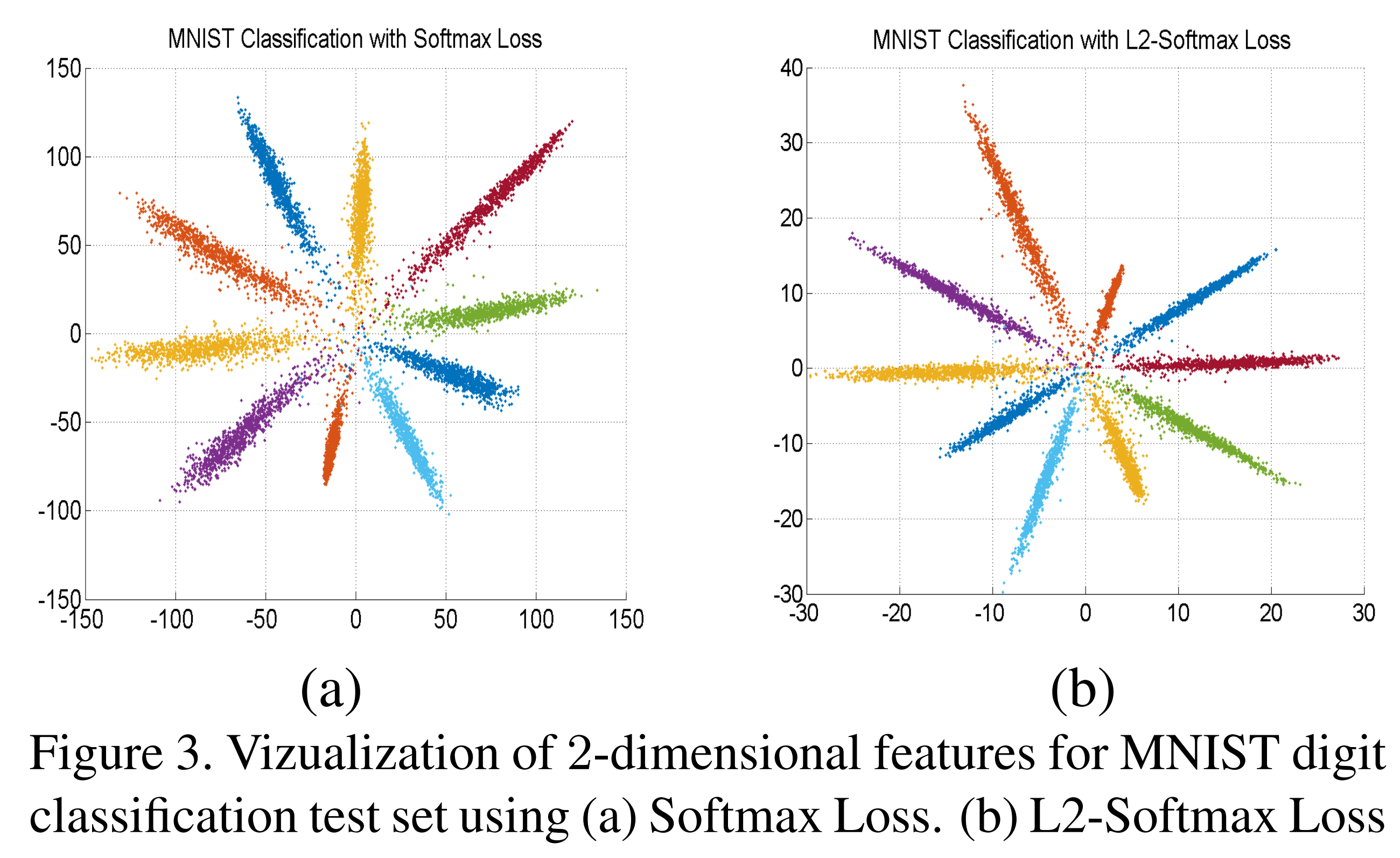
上图所示为普通softmax和L2-Softmax在mnist数据集上学到的特征分布情况对比,限制最后一个隐藏层的输出为2方便特征可视化。上图右侧小图显示的进行L2-normalization之前的特征。

实现细节:
训练时:
测试时:
测试时,不需要添加L2-Normalize和Scale层,因此本来测试时输出的特征都归一化到了单位长度。
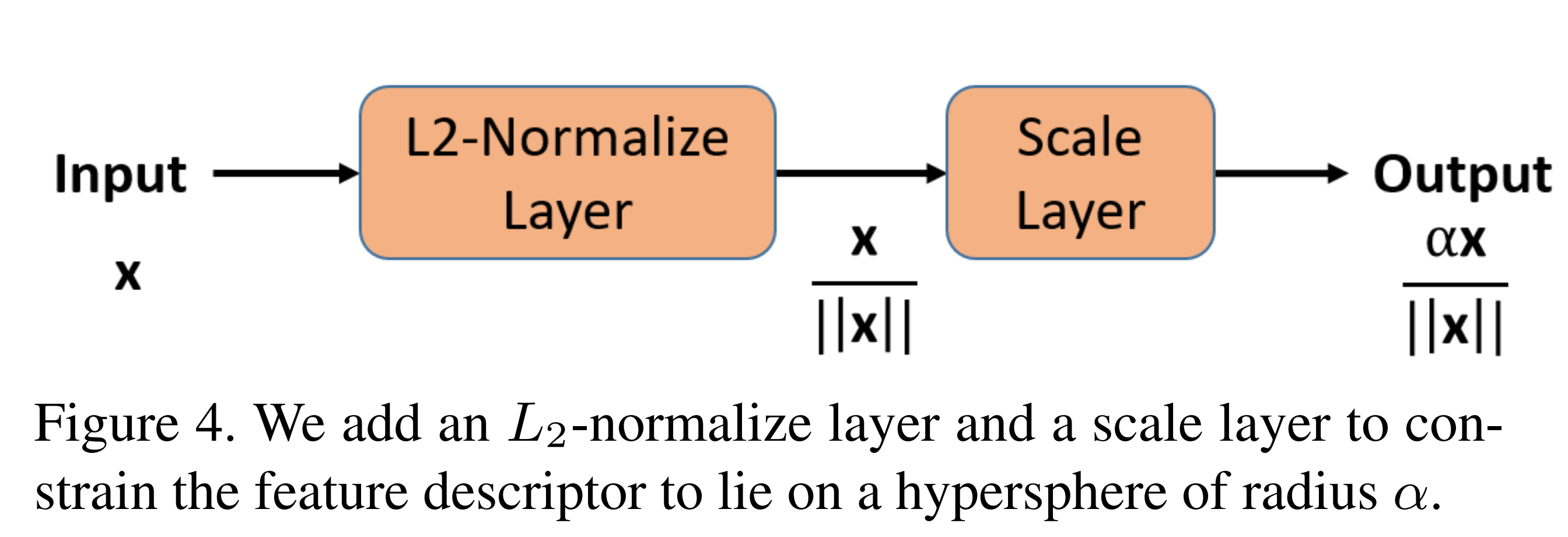
参数的限制:
参数有两种设置方式,一是在训练过程中设置为固定值,二是通过训练获得。但是第二种方式得到的会得到比较大的值,添加的限制太过宽松。作者建议设置为一个比较小的固定值。
但是作者也观察到的值设置太小的时候,超球面的表面积太小,特征分布不开,最后验证准确率也不高。
作者的设置策略是基于以下观察:当学习到的特征维数为时,如果此时的分类类别数,那么任何两类特征的中心在超球面上的距离都至少为。.
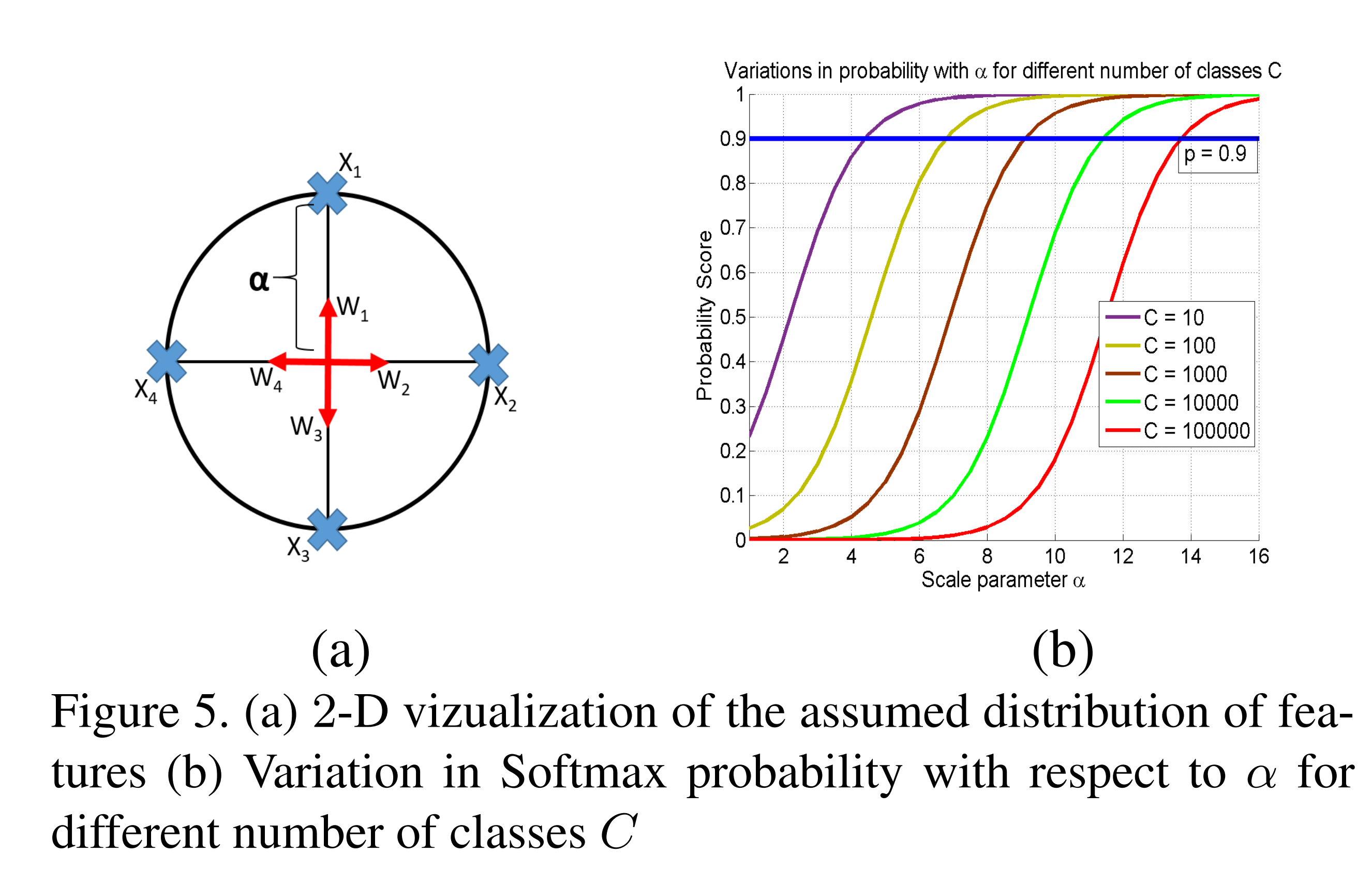
上图(a)是分为4类,特征为2维。上图(b)表示以验证准确率p=0.9时,类别数C越大,需要值越大。
作者给出的值为:
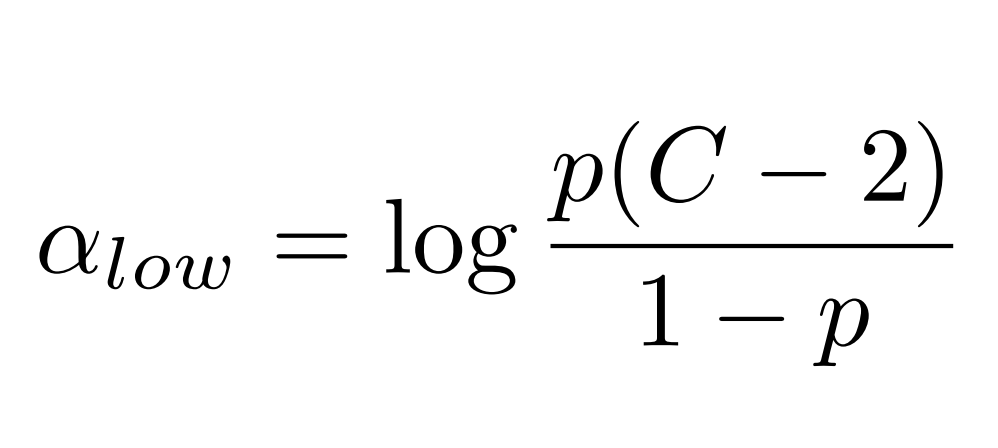
实验结果证明了的有限性和先进性。