最近研究XGBOOST,发现看完大篇理论推导之后根本不知道训练完一棵树后,下一棵树的输入是什么。
我想到了提升树(Boosting Tree),以平方误差损失函数为例,训练完一棵树后,只需要计算训练值和实际值
的残差,再对残差进行拟合就可以了。也就是说,加入我需要生成三棵树,第一棵树的拟合目标是
预测输出
第二棵树的拟合目标是
第三课树的拟合目标是
最终的预测值就是
而梯度提升树(GDBT),则是拟合损失函数的负梯度在当前模型的值,假设也是三棵树,损失函数为
第一棵树的拟合目标是
预测输出
此时需要计算第一棵树的损失函数,即,损失函数是关于
的函数,计算该损失函数对
的导数的相反数(负梯度)在Tree1上的值。
假设某一损失函数,某一样本输入
的标签
,那么此时该样本的损失函数为
,其负梯度为
,它就是下一轮样本
的输入
综上所述,第二棵树的拟合目标是
预测输出
第三棵树的拟合目标
预测输出
最终的预测值就是
接下来就是XGBOOST了,
第一棵树的拟合目标是
预测输出
那么最关键的,第二棵树的拟合目标是什么?是残差?还是一阶导数?还是二阶导数?其实我也不知道。我先把陈博士的图放上来
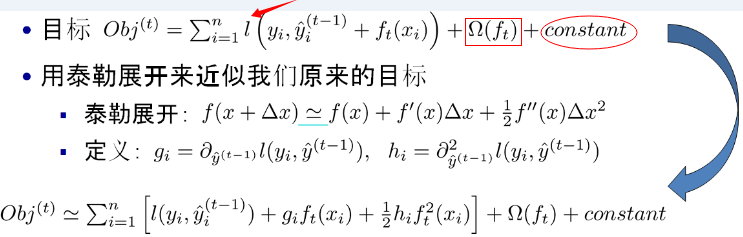
我个人的看法是,拟合是从很多种映射的集合中,找到某一映射使得损失函数最小。我们真正的关注点和目标是构造出损失函数,并让它取到最小值。看一下上图的目标函数,是未知的,是需要求得的树结构。而
、
、
是已知的,我们可以说是拟合
、
、
,也可以说是拟合
(因为
、
可由它求出),拟合什么东西不重要,重要的是使得损失函数最小。
就比如我在上面的提升树中,我可以说我下一轮的输入是
这和拟合
是等价的
因为我进入到前者的算法后,做的第一件事情就是算的值,然后构造出损失函数。后者作为残差更直观一些罢了。
因此,在XGBOOST中,我可以选择拟合
然后在内部算法中,算出、
,构造出损失函数,并最小化。“输入”只是一个形式。