1.记事本的ANSI编码为系统本地编码,我的是gbk
open()函数的encoding参数默认是本地编码,也就是gbk,所以直接读取ANSI编码的记事本文件是木有问题的。
怎么查看系统本地编码?
在cmd下输入: chcp
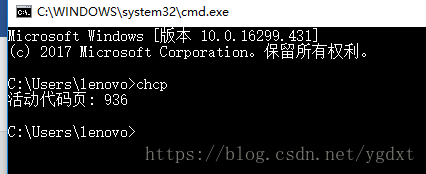
从下表可以看出,936对应gbk编码
下表列出了所有支持的代码页及其国家(地区)或者语言:
代码页 国家(地区)或语言
437 美国
708 阿拉伯文(ASMO 708)
720 阿拉伯文(DOS)
850 多语言(拉丁文 I)
852 中欧(DOS) - 斯拉夫语(拉丁文 II)
855 西里尔文(俄语)
857 土耳其语
860 葡萄牙语
861 冰岛语
862 希伯来文(DOS)
863 加拿大 - 法语
865 日耳曼语
866 俄语 - 西里尔文(DOS)
869 现代希腊语
874 泰文(Windows)
932 日文(Shift-JIS)
936 中国 - 简体中文(GB2312)
949 韩文
950 繁体中文(Big5)
1200 Unicode
1201 Unicode (Big-Endian)
1250 中欧(Windows)
1251 西里尔文(Windows)
1252 西欧(Windows)
1253 希腊文(Windows)
1254 土耳其文(Windows)
1255 希伯来文(Windows)
1256 阿拉伯文(Windows)
1257 波罗的海文(Windows)
1258 越南文(Windows)
20866 西里尔文(KOI8-R)
21866 西里尔文(KOI8-U)
28592 中欧(ISO)
28593 拉丁文 3 (ISO)
28594 波罗的海文(ISO)
28595 西里尔文(ISO)
28596 阿拉伯文(ISO)
28597 希腊文(ISO)
28598 希伯来文(ISO-Visual)
38598 希伯来文(ISO-Logical)
50000 用户定义的
50001 自动选择
50220 日文(JIS)
50221 日文(JIS-允许一个字节的片假名)
50222 日文(JIS-允许一个字节的片假名 - SO/SI)
50225 韩文(ISO)
50932 日文(自动选择)
50949 韩文(自动选择)
51932 日文(EUC)
51949 韩文(EUC)
52936 简体中文(HZ)
65000 Unicode(UTF-7)
65001 Unicode (UTF-8)
2.如果读取的是utf-8,我们需要在读文件的时候指定编码方式:
withopen("App3_1.cpp","r",encoding="utf-8") as fp:
3. python3 里只有unicode编码格式的字节对象能成为str。
其他编码格式的是bytes,如:gbk、utf-8………………
str.encode(编码格式) --> bytes
就是从 unicode 转换成 指定编码格式 的bytes
bytes.decode(编码格式) --> str
就是从 指定编码格式的bytes 转换成 unicode 的str
print('你好')
'你好'已经是 str了,不必转成bytes,直接输出就行。