Decision Tree简介
第五次写博客,作为决策树算法族的开篇,这里对各种决策树模型做一个简要概括和相关公式推导,并对决策树生成过程中的相关问题进行讨论。本人数学基础不是太好,如果有幸能得到读者指正,感激不尽,希望能借此机会向大家学习。为了方便理解,本文对信息论的一些理论做了简要介绍,下面直接进入正题。
决策树的基本生成过程
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点,叶结点对应于决策结果,其他每一个结点则对应于一个属性测试(一个/多个属性),每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集。决策树的学习目的是为了产生一颗泛化能力强,即处理未见事例能力强的决策树。决策树的生成遵循简单且直观的“分而治之”策略,其中对每个结点(node)的处理如下图所示。

上图涉及到了划分结点时遇到的三种情况:
1. 当前结点(node)所包含的样本全部属于同一类别,即全部拥有相同的标记,此时该结点无需划分,直接作为叶结点。(上图行2~4)
2. 当前结点(node)所包含的样本的属性为空或样本的所有属性值相等,此时该结点无需划分,直接作为叶结点,并将该叶结点的类别标记设置为该结点下,所含样本数量最多的类别(分类任务),或设置为该结点下所含样本的输出值的均值(回归任务)。需要注意的是,只有当算法采用的生成策略为,先选择好最优划分属性后,之后将该属性从属性集A移除时,最后才会产生“结点所含样本的属性为空”这种情况,此类算法以ID3为代表,而C4.5与C&RT会保留最优划分结点,并使其可能出现在之后的子结点中,这里不做详细的讨论。(上图行5~7)
3. 当前结点(node)所包含的样本数为零,此时该结点不能进行划分,同样是直接作为叶结点,但该叶结点的类别标记设置为其“父结点”所含样本数量最多的类别。(上图行11~13)
4. 其他情况的结点(node)作为内部结点,继续进行划分。
划分特征的选择
由算法第8行可知,决策树生成的重点在于最优划分属性的选择。划分属性的选择标准大多信息论为基础,旨在最大化划分后生成的各个子结点的纯度(Purity),即希望子结点所包含的样本尽可能属于同一个类别。根据“纯度”的定义不同,结点划分的准则有以下几种。
在这之前,先了解一下“信息熵”(Informatica
Entropy)的定义,“信息熵”是度量样本集合纯度最常用的一种指标,假设当前样本集
中第
类样本所占比例为
,其中
为样本集的总类别数量,则
的信息熵定义为

信息熵
越小,则
的纯度越高,需要注意的是由于
,因此
。
另外,“基尼系数”(Gini
Value)也是度量数据集纯度的一种指标,其定义如下

由上式可以看出,基尼系数(Gini
Value)反映了从数据集
中随机抽取两个样本,他们的类别标记不一致的概率,因此,基尼系数越小,数据集的纯度越高。
还可以采用回归/分类误差(Regression/Classification
Error)来定义数据集的纯度,“回归误差”(Regression
Error)的定义如下

其中,
。
“分类误差”(Classification
Error)的定义如下

其中
(即数据集中所含样本点数最多的类别标记)。
1. 信息增益(Informatica
Gain)
假定某一离散属性
有
个可能的取值,分别为
,若使用
来对样本集
进行划分,则会产生
个分支结点。其中第
个分支结点包含了
中所有在属性
上取值为
的样本,这些样本的集合记为
。可以根据式(1)对
的信息熵
进行计算,再考虑到不同的分支结点所包含的样本数不同,因此给每个分支结点的信息熵赋予权重
,即样本数越多的分支结点的影响越大,于是可以计算出使用属性
作为划分属性,对样本集
进行划分后所得的“信息增益”(Informatica
Gain)

信息增益 越大,即划分后的子集合的加权信息熵越小,则使用属性 来进行划分所得到的“纯度提升”越大。因此,可以使用信息增益作为结点划分的准则,即将算法中第8行改为

ID3就是以信息增益作为准则来选择最优划分属性的。
2. 增益率(Gain
Ratio)
实际上,将信息增益作为准则存在重要的问题,即他对可能的取值数量
较大的属性(e.g.
样本编号)有所偏好,为了解决这一问题,某些算法不直接采用信息增益做为准则,而是使用“增益率”(Gain
Ratio)来选择最优划分属性,他的定义为

上式中,

称为属性
的固有值(Intrinsic
Value)。与信息熵的定义类似,属性
的可能的取值数量
越大,其固有值越大。
需要注意的是,增益率对可取值数目
较少的属性有所偏好,因此在C4.5算法中并不是直接将具有最大增益率的属性作为划分属性,而是使用了一个“启发式”的方法,即先从候选划分属性中找出信息增益高于平均水平的属性,再从这些属性中选择增益率最高的作为最优划分属性。
3. 基尼指数(Gini Index)
还有一部分算法采用“基尼指数”(Gini Index)作为选择划分属性的准则,其定义如下

基尼指数 越小,则使用属性 作为划分属性,划分后的数据集的纯度越高,因此可以将算法中第8行改为

C&RT决策树就是以此为准则来选择最优划分属性的。
4.
加权回归/分类误差(Weighted
Regression/Classification
Error)
他们的定义如下

加权误差越小,采用属性
划分后的数据集的纯度越高。
实际上,还有很多其他的划分准则,这些准则对决策树的尺寸影响较大,但是相较于“减枝”处理,他们对泛化误差的影响很有限。
防止过拟合的方法
“减枝”(Pruning)是决策树防止过拟合的主要方法,其基本策略分别为“预减枝”(Prepruning)和“后减枝”(Postpruning)。其中,“预减枝”是指在决策树生长(growth)过程中,对每个结点在划分之前先进行估计,若当前结点的划分不能提高决策树的泛化性能,则停止对当前结点的划分,并将他设置为叶节点。“后减枝”是指在决策树完全生长完成后,“自底向上”对每个非叶节点进行考察,若将该节点对应的子树替换为叶节点能提升决策树的泛化性能,则该子树替换为叶节点。泛化性能的评估可以采用留出法,将原始数据集划分为训练集(供决策树生长)和测试集(供决策树减枝)。
连续值的处理
当某一属性的可取值数目不可数(连续值)或数目很多(离散值)时,可以采用离散化对这种情况进行处理。最简单的离散化方法就是“二分法”(bi-partition),这在C4.5(对离散属性也可以采用“n分法”,即将可取值分成n类)和C&RT中均有体现。
给定数据集
和连续属性
,假定
在
上出现了
个不同的取值,将这些值从小到大进行排列,排列后的可取值集合记为
,之后基于划分点
可将数据集
分为两个子集
和
,他们分别包含那些在属性
上取值不大于
的样本和大于
的样本。对于连续属性
,可以选取可取值集合中相临近两点的均值作为候选划分点,使用这种方法产生的候选划分点集的大小为
,候选集合为
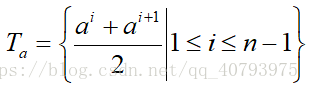
之后对候选划分点集中的每个候选点进行考察,选择使数据集纯度提升最高的那个作为划分点,具体方式如下所示

易知,
是数据集
基于划分点
二分后的信息增益。
需要注意的是,与离散属性不同的是,如果当前结点的划分属性为连续属性,该属性还可以作为其后代结点的划分属性。
缺失值的处理
现实任务中经常会遇到稀疏数据集,即数据集中的某些样本的某些属性值缺失,当遇到这种情况时,在决策树的训练过程中要考虑以下两个问题:
(1) 如何在属性值缺失的情况下,选择最优划分属性?
(2) 给定划分属性,若样本在该属性上的值缺失,如何对该样本进行划分?
同样,给定数据集
和属性
令
表示数据集
在属性
上没有缺失值的样本集合,那么对于第一个问题,显然我们只能根据
来决定属性
的好坏。假设属性
的可取值集合记为
,令
表示
中在属性
上取值为
的样本子集,
表示
中属于第
类
的样本子集,显然有
和
。假设为每个样本赋予一个权重
,并定义
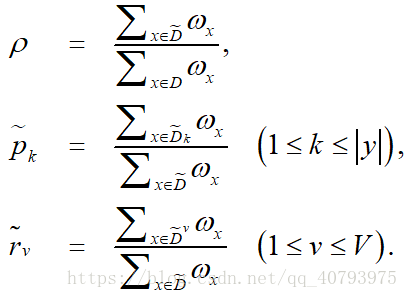
由上式定义可知,对于属性
,
表示无缺失值样本在整个数据集中所占的比例,
表示无缺失值数据集中属于第
类样本所占的比例,
表示无缺失值数据集中在属性
上取值为
的样本所占的比例,显然有
和
。
基于上述定义,我们可将信息增益的定义调整为

令 表示在数据集 中,并且在属性 上取值为 的样本子集中,属于第 类的样本集合,则这个样本集合在数据集 中所占的比例可以表示为
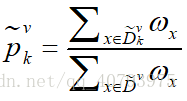
那么式(1)中的 和 可以分别表示为
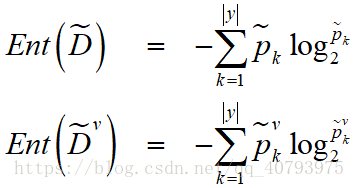
对于第二个问题,若样本 在划分属性 上的取值已知,则将 中去,并保持原始权值 。若样本 在划分属性 上的取值未知,则将 同时划分到所有的子结点中去,并且在每个子结点中该样本的权值变更为 ,直观的看,就是让同一个结点以不同的概率划分到不同的子结点中去。C4.5在处理缺失值(离散的)就采用了上述的方法。
决策树的特点
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关的特征数据。
缺点:可能会产生过拟合问题。
适用数据类型:连续型和离散型。