(1) tf.nn.atrous_conv2d, (2)tf.nn.softmax, (3)tf.nn.log_softmax, (4)tf.nn.softmax_cross_entropy_with_logits
(5) tf.nn.sparse_softmax_cross_entropy_with_logits, (6) tf.nn.sigmoid_cross_entropy_with_logits,
(7)tf.nn.avg_pool, (8)tf.nn.xw_plus_b, (9)tf.nn.top_k, (10)tf.nn.in_top_k, (11) tf.arg_max, tf.argmax和numpy.argmax
1.tf.nn.atrous_conv2d(value, filters, rate, padding, name=None)
空洞卷积,【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积?里面的图很形象
对卷积核填充0,使卷积核变大从而扩大感受野
参数如下:
注意strides无法改变,为1
value:A 4-D `Tensor` of type `float`. It needs to be in the default "NHWC" format. Its shape is 【batch, in_height, in_width, in_channels】
filters:A 4-D `Tensor` with the same type as `value` and shape = [filter_height, filter_width, in_channels, out_channels]. `filters' in_channels` dimension must match that of `value`. Atrous convolution is equivalent to standard convolution with upsampled filters with effective height =`filter_height + (filter_height - 1) * (rate - 1)` and effective width =`filter_width + (filter_width - 1) * (rate - 1)`, produced by inserting `rate - 1` zeros along consecutive elements across the `filters`' spatial dimensions.
rate:A positive int32. The stride with which we sample input values across the `height` and `width` dimensions. Equivalently, the rate by which we upsample the filter values by inserting zeros across the `height` and `width` dimensions. In the literature, the same parameter is sometimes called `input stride` or `dilation`.
padding: A string, either `'VALID'` or `'SAME'`. The padding algorithm.
name: Optional name for the returned tensor.
返回值: A `Tensor` with the same type as `value`.
(1) Output shape with `'VALID`` padding is: 这个时候卷积核的大小不能大于原图大小
[batch, height - 2 * (filter_width - 1), width - 2 * (filter_height - 1), out_channels].(2)Output shape with `'SAME'` padding is:[batch, height, width, out_channels]
Raises: ValueError: If input/output depth does not match `filters`' shape, or if padding is other than `'VALID'` or `'SAME'`.
2.tf.nn.softmax(logits, dim=-1, name=None)
Computes softmax activations.
For each batch `i` and class `j` we have
softmax = exp(logits) / reduce_sum(exp(logits), dim) 公式如下解释
Args:
logits: A non-empty `Tensor`. Must be one of the following types: `half`, `float32`, `float64`.
dim: The dimension softmax would be performed on. The default is -1 which indicates the last dimension.
name: A name for the operation (optional).Returns:
A `Tensor`. Has the same type as `logits`. Same shape as `logits`.
Raises:
Invalid Argument Error: if `logits` is empty or `dim` is beyond the last dimension of `logits`.


3.tf.nn.log_softmax(logits, dim=-1, name=None)
For each batch `i` and class `j` we have
logsoftmax = logits - log(reduce_sum(exp(logits), dim))
其他的和上面的函数是一样的
4. tf.nn.softmax_cross_entropy_with_logits( _sentinel=None, labels=None, logits=None,
dim=-1, name=None)
比较可以参见链接Tensorflow四种交叉熵函数计算公式:tf.nn.cross_entropy
Computes softmax cross entropy between `logits` and `labels`
测量离散分类任务的概率误差,在这些任务中,类别都是相互排斥的(每一个条目只有一个类别)。例如,每一张CIFAR-10的图片被标记并且只能标记一个label,它可以是一只狗或者一辆卡车,但不能两者皆是。
注意:虽然类别是相互排斥的,但是这些类别的概率不要求是相互排斥的。仅仅要求each row of `labels` is a valid probability distribution(科普:这种分布要满足两个条件1) all probabilities must be nonnegative, and 2) the probabilities must add to 1)
同时也要注意:This op expects unscaled logits, since it performs a `softmax` on `logits` internally for efficiency. Do not call this op with the output of `softmax`, as it will produce incorrect results.
`logits` 和 `labels` 必须要是相同的shape,和相同的类型。 e.g. shape= `[batch_size, num_classes]` and dtype= (either `float32`,or `float64`)
参数:
_sentinel: 内部的,不需要使用这个参数(忽略)
labels: Each row `labels[i]` must be a valid probability distribution.one_hot = Ture(向量中只有一个为1,其他为0),是稀疏表示的
logits: Unscaled log probabilities.
dim: The class dimension. Defaulted to -1 which is the last dimension.
name: A name for the operation (optional).Returns:loss,一个一维的,shape=[batch_size]
A 1-D `Tensor` of length `batch_size` of the same type as `logits` with thesoftmax cross entropy loss.
它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象。output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
import tensorflow as tf import numpy as np def softmax(x): sum_raw = np.sum(np.exp(x),axis=-1) x1 = np.ones(np.shape(x)) for i inrange(np.shape(x)[0]): x1[i] = np.exp(x[i])/sum_raw[i] return x1 y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])# 因为类别相互排斥,每一行只有一个1 y=[batch,classes] logits =np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]) #logits=[batch,classes] #下面是公式的显式的写出来 y_pred = softmax(logits) E1 = -np.sum(y*np.log(y_pred),-1) # E1=[batch] # np.sum里面的参数axis默认是None,对全部的元素相加;axis=0是对第一维相加,axis=1是对第二维相加 #axis = -1 是对最后一维相加, #例如input的shape=[2,3,4],那么对应的shape: output0=[3,4],output1=[2,4],output-1 = [2,3] #下面是直接调用softmax交叉熵函数 y = np.array(y).astype(np.float64) E2 = tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits) sess = tf.Session() print(sess.run(E1)) print(sess.run(E2)) # E1 和E2 这两个是一样的 E=tf.reduce_sum(E2) # do not forget tf.reduce_sum()!!! print(sess.run(E)) #这个是总的损失结果

5. tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
Computes sparse softmax cross entropy between `logits` and `labels‘。
测量离散分类任务的概率误差,在这些任务中,类别都是相互独立并且相互排斥的(每一个条目只有一个类别)。例如,每一张CIFAR-10的图片被标记并且只能标记一个label,它可以是一只狗或者一辆卡车,但不能两者皆是。
注意:对于这个operation,类别的概率是相互排斥的. That is, soft classes are not allowed, and the `labels` vector must provide a single specific index for the true class for each row of `logits` (each minibatch entry)。也就是说参数labels是直接使用标签数据的,而不是采用one-hot编码形式。所以shape=[batch],里面的元素就是标签
同时也要注意:This op expects unscaled logits, since it performs a `softmax` on `logits` internally for efficiency. Do not call this op with the output of `softmax`, as it will produce incorrect results.
A common use case is to have logits of shape `[batch_size, num_classes]` and labels of shape `[batch_size]`. But higher dimensions are supported.
参数:
_sentinel: Used to prevent positional parameters. Internal, do not use.
labels: `Tensor` of shape `[d_0, d_1, ..., d_{r-1}]` (where `r` is rank of `labels` and result) and dtype `int32` or `int64`. (Each entry in `labels` must be an index in `[0, num_classes)`. Other values will raise an exception when this op is run on CPU, and return `NaN` for corresponding loss and gradient rows on GPU。是非稀疏表示的
logits: Unscaled log probabilities of shape `[d_0, d_1, ..., d_{r-1}, num_classes]` and dtype `float32` or `float64`.
name: A name for the operation (optional).Returns:
A `Tensor` of the same shape as `labels` and of the same type as `logits` with the softmax cross entropy loss.Raises:
ValueError: If logits are scalars (need to have rank >= 1) or if the rank of the labels is not equal to the rank of the labels minus one.
这个函数和tf.nn.softmax_cross_entropy_with_logits函数比较明显的区别在于它的参数labels的不同,这里的参数label是非稀疏表示的。tf.nn.sparse_softmax_cross_entropy_with_logits()比tf.nn.softmax_cross_entropy_with_logits多了一步将labels非稀疏化的操作。因为深度学习中,图片一般是用非稀疏的标签的,所以用tf.nn.sparse_softmax_cross_entropy_with_logits()的频率比tf.nn.softmax_cross_entropy_with_logits高。output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
import numpy as np import tensorflow as tf y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])# 因为胡类别相互排斥,每一行只有一个1 y=[batch,classes],稀疏的标签 logits =np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]) #logits=[batch,classes] #这个是softmax交叉熵函数 y = np.array(y).astype(np.float64) E1 = tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits) Loss1 =tf.reduce_sum(E1) #下面就是Sparse_softmax交叉熵函数 dense_y=tf.arg_max(y,1) #首先将稀疏的标签稠密化,多了一步操作 E2 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=dense_y,logits=logits) Loss2 =tf.reduce_sum(E2)在里面应用到了一个函数tf.arg_max将稀疏的标签稠密化,详细参考最下面
6. tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
它适用于每个类别相互独立但互不排斥的情况也就是一个样本可以同时拥有多类:例如一幅图可以同时包含一条狗和一只大象。output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mea(loss)使用
参数:
_sentinel: Used to prevent positional parameters. Internal, do not use.
labels: A `Tensor` of the same type and shape as `logits`.
logits: A `Tensor` of type `float32` or `float64`.
name: A name for the operation (optional).Returns: A `Tensor` of the same shape as `logits` with the componentwise logistic losses.
Raises: ValueError: If `logits` and `labels` do not have the same shape.
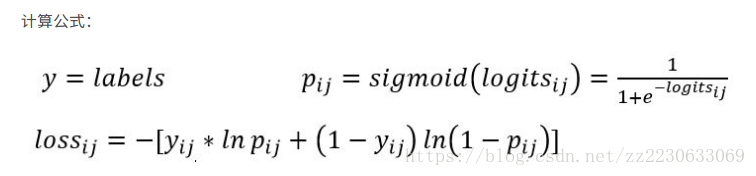
举例:
import tensorflow as tf import numpy as np def sigmoid(x): return 1.0/(1+np.exp(-x)) # 5个样本三分类问题,且一个样本可以同时拥有多类 y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]] logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]) # 按照定义来计算loss y_pred = sigmoid(logits) E1 = -y*np.log(y_pred)-(1-y)*np.log(1-y_pred) loss1 = tf.reduce_sum(E1) print(E1) # 按计算公式计算的结果 #按照sigmoid交叉熵函数直接计算loss y = np.array(y).astype(np.float64) # labels是float64的数据类型 E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits)) loss2 = tf.reduce_sum(E2) sess =tf.Session() print(sess.run(E2)) print(loss1,'\n'loss2) close sess # 结果是E1 = E2, loss1 = loss2
7.tf.nn.avg_pool(value, ksize, strides, padding, data_format="NHWC", name=None)
Performs the average pooling on the input. Each entry in `output` is the mean of the corresponding size `ksize` window in `value`.
参数:
value: A 4-D `Tensor` of shape `[batch, height, width, channels]` and type `float32`, `float64`, `qint8`, `quint8`, or `qint32`. ksize: A list of ints that has length >= 4. The size of the window for each dimension of the input tensor.
strides: A list of ints that has length >= 4. The stride of the sliding window for each dimension of the input tensor. padding: A string, either `'VALID'` or `'SAME'`. The padding algorithm. See the @{tf.nn.convolution$comment here}
data_format: A string. 'NHWC' and 'NCHW' are supported.
name: Optional name for the operation. Returns: A `Tensor` with the same type as `value`. The average pooled output tensor.
8. tf.nn.xw_plus_b(x, weights, biases, name=None)
Computes matmul(x, weights) + biases
参数:
x: a 2D tensor. Dimensions typically: 【batch, in_units】
weights: a 2D tensor. Dimensions typically: 【in_units, out_units】
biases: a 1D tensor. Dimensions: out_units name: A name for the operation (optional). If not specified "xw_plus_b" is used. Returns:A 2-D Tensor computing matmul(x, weights) + biases. Dimensions typically: batch, out_units.
9. tf.nn.top_k(input, k=1, sorted=True, name=None)
Finds values and indices of the `k` largest entries for the last dimension.寻找最后一维的前k个最大值,和该最大值所在的索引号。
参数:
input: 1-D or higher `Tensor` with last dimension at least `k`.
k: 0-D `int32` `Tensor`. Number of top elements to look for along the last dimension (along each row for matrices).
sorted: If true the resulting `k` elements will be sorted by the values in descending order.
name: Optional name for the operation.Returns: 类型为'tensorflow.python.ops.gen_nn_ops.TopKV2' ,
values: The `k` largest elements along each last dimensional slice.例如input是一个[a,b,c,d]shape的tensor,那么k一定不能大于d(最后一维),输出来的shape=[a,b,c,k]
indices: The indices of `values` within the last dimension of `input`. The same shape with value
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
input = tf.constant(np.random.rand(3,4))
k = 2
output = tf.nn.top_k(input, k)
with tf.Session() as sess:
print(sess.run(input))
print(sess.run(output))
输出
[[ 0.98925872 0.15743092 0.76471106 0.5949957 ]
[ 0.95766488 0.67846336 0.21058844 0.2644312 ]
[ 0.65531991 0.61445187 0.65372938 0.88111084]]
TopKV2(values=array([[ 0.98925872, 0.76471106],
[ 0.95766488, 0.67846336],
[ 0.88111084, 0.65531991]]), indices=array([[0, 2],
[0, 1],
[3, 0]]))10.tf.nn.in_top_k(predictions, targets, k, name=None)
Says whether the targets are in the top `K` predictions
参数:
predictions: A `Tensor` of type `float32`. A `batch_size` x `classes` tensor. 预测的结果,是个二维矩阵
targets: A `Tensor`. Must be one of the following types: `int32`, `int64`. A `batch_size` vector of class ids. 实际的标签
k: An `int`. Number of top elements to look at for computing precision.
name: A name for the operation (optional).Returns: A `Tensor` of type `bool`. Computed Precision at `k` as a `bool Tensor`.
import tensorflow as tf;
A = [[0.8,0.6,0.3], [0.1,0.6,0.4]]
B = [1, 1]
out1 = tf.nn.in_top_k(A, B, 1)
out2 = tf.nn.in_top_k(A,B,2)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
print(sess.run(out1))
print(sess.run(out2))
输出
[False,True]
[True, True]对上述代码进行分析:A=[batch,classes]=[2,3]可以看成两张图片,每一张图片可能是三个类别也就是有三种标签对应着索引号。B是一个vector长度为batch的值,是每张图片的实际的标签,在这里实际的标签是两张图片都是1。当k=1的时候,得到的topk第一张图片的最大值是0.8,所在的索引是0也就是属于第一类;第二张图片的最大值是0.6,所在的索引是1也就是标签是1。和实际标签一对比,所以结果就是False,True。当k=2的时候,第一张图片得到两个最大值0.8和0.6,索引分别是0和1,所以和真实标签对比之后,由于真实标签属于得到的索引集合里面,所以也返回了True。
11.tf.argmax(input, axis=None, name=None, dimension=None, output_type=dtypes.int64)
一般用来求一个矩阵中,每行最大值的index。tf.arg_max和tf.argmax作用是一样的
参数:
input: A `Tensor`. Must be one of the following types: `float32`, `float64`, `int64`, `int32`, `uint8`, `uint16`, `int16`, `int8`, `complex64`, `complex128`, `qint8`, `quint8`, `qint32`, `half`.
axis: A `Tensor`. Must be one of the following types: `int32`, `int64`.(注意这里是整形就行了)int32, 0 <= axis < rank(input). Describes which axis of the input Tensor to reduce across. For vectors, use axis = 0.
name: A name for the operation (optional).raise ValueError("Cannot specify both 'axis' and 'dimension'")
tf.argmax() 与 numpy.argmax() 方法的用法是一致的
>>> a = np.arange(6).reshape(2,3) >>> a array([[0, 1, 2], [3, 4, 5]]) >>> np.argmax(a) 5 >>> np.argmax(a, axis=0) #0代表列 array([1, 1, 1]) >>> np.argmax(a, axis=1) #1代表行 array([2, 2]) >>> >>> b = np.arange(6) >>> b[1] = 5 >>> b array([0, 5, 2, 3, 4, 5]) >>> np.argmax(b) #只返回第一次出现的最大值的索引 1