缓冲区是包在一个对象内的基本数据元素数组,Buffer类相比一个简单的数组的优点是它将关于数据的数据内容和信息包含在一个单一的对象中。
Buffer的属性
容量(capacity):缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变
上界(limit):缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数
位置(position):下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新
标记(mark):下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position =mark。标记在设定前是未定义的(undefined)。这四个属性之间总是遵循以下关系:0 <= mark <= position <= limit <= capacity
例如:
// mark=position=0;limit=capacity=256
ByteBuffer buf = ByteBuffer.allocate(256);Buffer源码分析
package com.swk.nio;
import java.nio.BufferOverflowException;
import java.nio.BufferUnderflowException;
import java.nio.InvalidMarkException;
import java.nio.ReadOnlyBufferException;
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
// Creates a new buffer with the given mark, position, limit, and capacity,
// after checking invariants.
//根据mark,position,limit,capacity初始化buffer
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
/**
* 返回Buffer的容量
* @author fuyuwei
* 2017年6月19日 下午9:23:19
* @return
*/
public final int capacity() {
return capacity;
}
/**
* 返回Buffer的位置
* @author fuyuwei
* 2017年6月19日 下午9:23:33
* @return
*/
public final int position() {
return position;
}
/**
* 设置Buffer的position,如果mark>position,则mark废弃
* @author fuyuwei
* 2017年6月19日 下午9:23:56
* @param newPosition
* @return
*/
public final Buffer position(int newPosition) {
if ((newPosition > limit) || (newPosition < 0))
throw new IllegalArgumentException();
position = newPosition;
if (mark > position) mark = -1;
return this;
}
/**
* 返回Buffer的上界
* @author fuyuwei
* 2017年6月19日 下午9:25:10
* @return
*/
public final int limit() {
return limit;
}
/**
* 设置Buffer的上界,如果position>limit,则把position设置为新的limit,如果mark>newLimit则废弃mark
* @author fuyuwei
* 2017年6月19日 下午9:25:26
* @param newLimit
* @return
*/
public final Buffer limit(int newLimit) {
if ((newLimit > capacity) || (newLimit < 0))
throw new IllegalArgumentException();
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
/**
* 将mark设置为position
* @author fuyuwei
* 2017年6月19日 下午9:28:02
* @return
*/
public final Buffer mark() {
mark = position;
return this;
}
/**
* 将buffer的position重置为先前的mark
* @author fuyuwei
* 2017年6月19日 下午9:28:32
* @return
*/
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
/**
* 用于写模式,清空buffer,将position置为0,limit置为capacity,丢弃mark
* 需要注意的此时buffer中仍有数据,当相同或不同线程再访问时可以直接从内存中获取
* @author fuyuwei
* 2017年6月19日 下午9:29:29
* @return
*/
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
/**
* 将写模式转变为读模式;翻转此buffer,首先对当前位置设置限制,然后将该位置设置为零。如果已定义了标记,则丢弃该标记
* @author fuyuwei
* 2017年6月19日 下午9:31:44
* @return
*/
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
/**
* rewind()在读写模式下都可用,它单纯的将当前位置置0,同时取消mark标记
* @author fuyuwei
* 2017年6月19日 下午9:34:48
* @return
*/
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
/**
* 获取当前位置到上限之间元素个数
* @author fuyuwei
* 2017年6月19日 下午9:35:12
* @return
*/
public final int remaining() {
return limit - position;
}
/**
* 是否还有剩余元素
* @author fuyuwei
* 2017年6月19日 下午9:35:51
* @return
*/
public final boolean hasRemaining() {
return position < limit;
}
/**
* 当前buffer是否是只读
* @author fuyuwei
* 2017年6月19日 下午9:36:16
* @return
*/
public abstract boolean isReadOnly();
/**
* 判断这个缓冲区是否被一个可访问数组所支持
* @author fuyuwei
* 2017年6月19日 下午9:38:38
* @return
*/
public abstract boolean hasArray();
/**
* 返回支持的数组
* 这种方法的目的是让数组支持的缓冲区更有效地传递给本地代码。具体的子类为这个方法提供了更强类型的返回值
* 对该缓冲区内容的修改将导致返回的数组内容被修改,反之亦然。
* 在调用这个方法之前,调用@link hasArray hasArray方法,以确保该缓冲区拥有一个可访问的支持数组。
* @author fuyuwei
* 2017年6月19日 下午9:39:11
* @return
*/
public abstract Object array();
/**
* 在缓冲区的第一个元素的支持数组中返回偏移量
* 如果这个缓冲区得到一个数组的支持那么缓冲位置对应于数组索引
* 在调用这个方法之前调用@link hasArray hasArray方法,以确保该缓冲区具有可访问的支持数组
* @author fuyuwei
* 2017年6月19日 下午9:40:52
* @return
*/
public abstract int arrayOffset();
/**
* Tells whether or not this buffer is
* <a href="ByteBuffer.html#direct"><i>direct</i></a>. </p>
*
* @return <tt>true</tt> if, and only if, this buffer is direct
*
* @since 1.6
*/
public abstract boolean isDirect();
// -- Package-private methods for bounds checking, etc. --
/**
* 检查当前位置与限制,如果它不小于限制,则抛出一个@link BufferUnderflowException,否则增加该位置
* @author fuyuwei
* 2017年6月19日 下午9:43:00
* @return
*/
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
/**
* 增加指定值的position
* @author fuyuwei
* 2017年6月19日 下午9:44:05
* @param nb
* @return
*/
final int nextGetIndex(int nb) { // package-private
if (limit - position < nb)
throw new BufferUnderflowException();
int p = position;
position += nb;
return p;
}
/**
* Checks the current position against the limit, throwing a {@link
* BufferOverflowException} if it is not smaller than the limit, and then
* increments the position. </p>
*
* @return The current position value, before it is incremented
*/
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
final int nextPutIndex(int nb) { // package-private
if (limit - position < nb)
throw new BufferOverflowException();
int p = position;
position += nb;
return p;
}
/**
* 检查给定索引的限制,如果它不小于limit或小于0,则抛出一个@link IndexOutOfBoundsException。
* @author fuyuwei
* 2017年6月19日 下午9:45:34
* @param i
* @return
*/
final int checkIndex(int i) { // package-private
if ((i < 0) || (i >= limit))
throw new IndexOutOfBoundsException();
return i;
}
final int checkIndex(int i, int nb) { // package-private
if ((i < 0) || (nb > limit - i))
throw new IndexOutOfBoundsException();
return i;
}
final int markValue() { // package-private
return mark;
}
final void truncate() { // package-private
mark = -1;
position = 0;
limit = 0;
capacity = 0;
}
final void discardMark() { // package-private
mark = -1;
}
static void checkBounds(int off, int len, int size) { // package-private
if ((off | len | (off + len) | (size - (off + len))) < 0)
throw new IndexOutOfBoundsException();
}
}Buffer的存取
缓冲区管理着固定数目的数据元素,在我们想清空缓冲区之前,我们可能只使用了缓冲区的一部分。这时,我们需要能够追踪添加到缓冲区内的数据元素的数量,放入下一个元素的位置等等的方法。位置属性做到了这一点。它在调用 put()时指出了下一个数据元素应该被插入的位置,或者当 get()被调用时指出下一个元素应从何处检索。这里我们以ByteBuffer为例介绍下这两个方法。
public abstract class ByteBuffer {
/**
* 读取该缓冲区当前位置上的字节,然后增加位置。
* @author fuyuwei
* 2017年6月19日 下午9:54:42
* @return
*/
public abstract byte get();
/**
* 读取给定索引中的字节
* @author fuyuwei
* 2017年6月19日 下午9:56:17
* @param index
* @return
*/
public abstract byte get(int index);
/**
* 将给定的字节写入当前位置的缓冲区中,然后增加位置
* @author fuyuwei
* 2017年6月19日 下午9:56:54
* @param b
* @return
*/
public abstract ByteBuffer put(byte b);
/**
* 在给定索引中将给定字节写入该缓冲区
* @author fuyuwei
* 2017年6月19日 下午9:57:53
* @param index
* @param b
* @return
*/
public abstract ByteBuffer put(int index, byte b);
}Buffer的填充
我们将代表“Hello”字符串的 ASCII 码载入一个名为 buffer 的ByteBuffer 对象中。
public static void main(String[] args) {
ByteBuffer buffer=ByteBuffer.allocate(256);
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
}此时byteBuffer的position为5(从0开始),注意本例中的每个字符都必须被强制转换为 byte。我们不能不经强制转换而这样操做:
buffer.put('H');因为我们存放的是字节而不是字符。记住在 java 中,字符在内部以 Unicode 码表示,每个 Unicode 字符占 16 位。通过将char 强制转换为 byte,我们删除了前八位来建立一个八位字节值。既然我们已经在 buffer 中存放了一些数据,如果我们想在不丢失位置的情况下通过put进行修改。假设我们想将缓冲区中的内容从“Hello”的 ASCII 码更改为“ Mellow”。我们可以这样实现:
buffer.put(0,(byte)'M').put((byte)'w');第0个position的H被替换为了M,而第二个put不会修改第1个position他会从之前记住的position(第5个)开始往buffer里放数据
Buffer的翻转
对于已经写满了缓冲区,如果将缓冲区内容传递给一个通道,以使内容能被全部写出。但如果通道现在在缓冲区上执行get(),那么它将从我们刚刚插入的有用数据之外取出未定义数据。如果我们通过翻转将位置值重新设为 0,通道就会从正确位置开始获取。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}Flip()函数将一个能够继续添加数据元素的填充状态的缓冲区翻转成一个准备读出元素的释放状态
例如我们定义了一个容量是10的buffer,并填入hello,如下图所示

翻转后如下图所示

Rewind()函数与 flip()相似,但不影响上界属性。它只是将位置值设回 0。您可以使用 rewind()后退,重读已经被翻转的缓冲区中的数据。
翻转两次把上界设为位置的值,并把位置设为 0。上界和位置都变成 0,get()操作会导致 BufferUnderflowException 异常。而 put()则会导致 BufferOverflowException 异常。
Buffer的释放
如果一个填满的缓冲区在读之前要对其进行翻转,hashRemaining会在释放缓冲区时告诉我们是否已达到缓冲区的上界。缓冲区并不是线程安全的,多线程环境下在存取缓冲区之前要进行同步处理。一旦缓冲区对象完成填充并释放,它就可以被重新使用了,clear()将缓冲区重置为空。他并不改变缓冲区的数据,仅仅是将上界设为容量值,并把位置设置为0,这使得缓冲区可以重新被填入。
填充和释放缓冲区代码例如:
public class NIOTest {
private static int index = 0;
private static String [] strings = {
"A random string value",
"The product of an infinite number of monkeys",
"Hey hey we're the Monkees",
"Opening act for the Monkees: Jimi Hendrix",
"'Scuse me while I kiss this fly",
"Help Me! Help Me!",
};
public static void main(String[] args) {
CharBuffer buf = CharBuffer.allocate(128);
while(fillBuffer(buf)){
buf.flip();
drainBuffer(buf);
buf.clear();
}
}
private static void drainBuffer(CharBuffer buffer){
while(buffer.hasRemaining()){
System.out.println(buffer.get());
}
}
private static boolean fillBuffer(CharBuffer buffer){
if(index >= strings.length){
return false;
}
String string = strings[index++];
for(int i=0;i<strings.length;i++){
buffer.put(string.charAt(i));
}
return true;
}
}Buffer的压缩
public abstract ByteBuffer compact();如果我们只想从缓冲区中释放一部分数据,而不是全部,然后重新填充。为了实现这一点,未读的数据元素需要下移以使第一个元素索引为 0。尽管重复这样做会效率低下,但这有时非常必要,而 API 对此为您提供了一个 compact()函数。这一缓冲区工具在复制数据时要比您使用 get()和 put()函数高效得多。

压缩后变成

元素2-4被复制了0-2。位置3,4不受影响,3和4可以被之后的put覆盖,postion变成了被复制元素的个数的位置,limit=capacity,此时缓冲区可以再次被填满。调用 compact()的作用是丢弃已经释放的数据,保留未释放的数据,并使缓冲区对重新填充容量准备就绪。
Buffer的标记
标记,使缓冲区能够记住一个位置并在之后将其返回。缓冲区的标记在 mark( )函数被调用之前是未定义的,调用时标记被设为当前位置的值。reset( )函数将位置设为当前的标记值。如果标记值未定义,调用 reset( )将导致 InvalidMarkException 异常。一些缓冲区函数会抛弃已经设定的标记( rewind( ), clear( ),以及 flip( )总是抛弃标记)。如果新设定的值比当前的标记小,调用limit( )或 position( )带有索引参数的版本会抛弃标记。这里需要注意的是clear( )函数将清空缓冲区,而 reset( )位置返回到一个先前设定的标记。

如果这个缓冲区现在被传递给一个通道,两个字节(“ lo”)将会被发送,而位置会前进到 5。如果我们此时调用 reset( ),位置将会被设为标记,如下图所示。再次将缓冲区传递给通道将导致四个字节(“ello”)被发送。
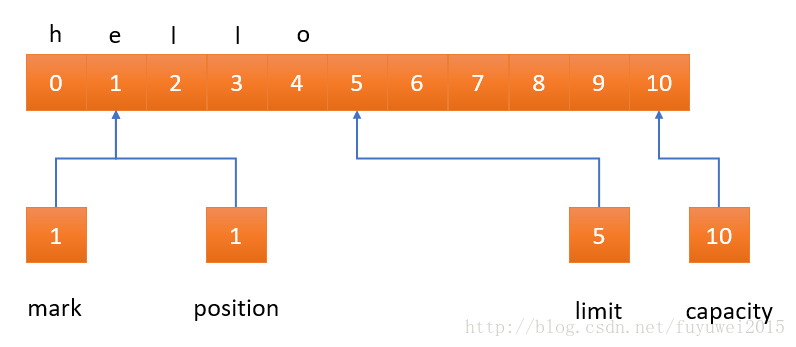
Buffer的比较
equals( )
返回true的条件:
1、两个对象类型相同。包含不同数据类型的 buffer 永远不会相等,而且 buffer绝不会等于非 buffer 对象。
2、两个对象都剩余同样数量的元素。 Buffer 的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相同。
3、在每个缓冲区中应被 Get()函数返回的剩余数据元素序列必须一致
compareTo( )
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer:
1、第一个不相等的元素小于另一个Buffer中对应的元素 。
2、所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。
Buffer的批量移动
缓冲区的涉及目的就是为了能够高效传输数据。一次移动一个数据元素效率并不高,Buffer的API给我们提供了批量移动的方法。批量移动总是具有指定的长度。也就是说,您总是要求移动固定数量的数据元素
/**
* 这个方法将所有字节从这个缓冲区传输到给定的目标数组中
* @author fuyuwei
* 2017年6月20日 下午9:21:41
* @param dst
* @return
*/
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
/**
* 这个方法将字节从这个缓冲区传输到给定的目标数组。
* @author fuyuwei
* 2017年6月20日 下午9:23:01
* @param dst
* @param offset
* @param length
* @return
*/
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
/**
* 这个方法将给定源字节数组的整个内容传输到这个缓冲区中。
* @author fuyuwei
* 2017年6月20日 下午9:26:33
* @param src
* @return
*/
public final ByteBuffer put(byte[] src) {
return put(src, 0, src.length);
}
/**
* 这个方法将字节从给定的源数组中转移到这个缓冲区中
* @author fuyuwei
* 2017年6月20日 下午9:30:52
* @param src
* @param offset
* @param length
* @return
*/
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
this.put(src[i]);
return this;
}