一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)
概念:
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
数据域:存数数据元素信息的域。
指针域:存储直接后继位置的域。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型:
根据链表的构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向循环链表
二、单链表:
概念:
链表的每个结点中只包含一个指针域,叫做单链表(即构成链表的每个结点只有一个指向直接后继结点的指针)
单链表中每个结点的结构:

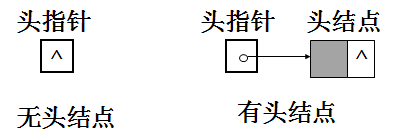
1、头指针和头结点:
单链表有带头结点结构和不带头结点结构两种。
“链表中第一个结点的存储位置叫做头指针”,如果链表有头结点,那么头指针就是指向头结点的指针。
头指针所指的不存放数据元素的第一个结点称作头结点(头结点指向首元结点)。头结点的数据域一般不放数据(当然有些情况下也可存放链表的长度、用做监视哨等)
存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
如下图所示:

不带头结点的单链表如下:

带头结点的单链表如下图:

关于头指针和头结点的概念区分,可以参考如下博客:
http://blog.csdn.net/hitwhylz/article/details/12305021
2、不带头结点的单链表的插入操作:

上图中,是不带头结点的单链表的插入操作。如果我们在非第一个结点前进行插入操作,只需要a(i-1)的指针域指向s,然后将s的指针域指向a(i)就行了;如果我们在第一个结点前进行插入操作,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。
因此,算法对这两种情况就要分别设计实现方法。
3、带头结点的单链表的插入操作:(操作统一,推荐)

上图中,如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值(改变头结点的指针域),而头指针head的值不变。
因此,算法实现方法比较简单,其操作与对其它结点的操作统一。
问题1:头结点的好处:
头结点即在链表的首元结点之前附设的一个结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理,编程更方便。
问题2:如何表示空表:
无头结点时,当头指针的值为空时表示空表;
有头结点时,当头结点的指针域为空时表示空表。
如下图所示:
问题3:头结点的数据域内装的是什么?
头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值。
三、单项链表的代码实现:
1、结点类:
编写一个Node类来充当结点的模型。我们知道,其中有两个属性,1存放数据的data,2存放下一结点的引用,
public class Node {
//为了方便,这两个变量都使用public,而不用private就不需要编写get、set方法了。
//存放数据的变量,简单点,直接为int型
public int data;
//存放结点的变量,默认为null
public Node next;
//构造方法,在构造时就能够给data赋值
public Node(int data){
this.data = data;
}
}1.1增加结点操作,addNode(Node)
/** * 增加操作 * 直接在链表的最后插入新增的结点即可 * 将原本最后一个结点的next指向新结点 */ public void addNode(Node node){ //链表中有结点,遍历到最后一个结点 Node temp = head; //一个移动的指针(把头结点看做一个指向结点的指针) while(temp.next != null){ //遍历单链表,直到遍历到最后一个则跳出循环。 temp = temp.next; //往后移一个结点,指向下一个结点。 } temp.next = node; //temp为最后一个结点或者是头结点,将其next指向新结点 }1.2 插入结点到链表的指定位置。 insertNodeByIndex(int index,Node node)
/** * insertNodeByIndex:在链表的指定位置插入结点。 * 插入操作需要知道1个结点即可,当前位置的前一个结点 * index:插入链表的位置,从1开始 * node:插入的结点 */ public void insertNodeByIndex(int index,Node node){ //首先需要判断指定位置是否合法, if(index<1||index>length()+1){ System.out.println("插入位置不合法。"); return; } int length = 1; //记录我们遍历到第几个结点了,也就是记录位置。 Node temp = head; //可移动的指针 while(head.next != null){//遍历单链表 if(index == length++){ //判断是否到达指定位置。 //注意,我们的temp代表的是当前位置的前一个结点。 //前一个结点 当前位置 后一个结点 //temp temp.next temp.next.next //插入操作。 node.next = temp.next; temp.next = node; return; } temp = temp.next; } }
1.3删除指定位置上的结点 delNodeByIndex(int index)
/** * 通过index删除指定位置的结点,跟指定位置增加结点是一样的,先找到准确位置。然后进行删除操作。 * 删除操作需要知道1个结点即可:和当前位置的前一个结点。 * @param index:链表中的位置,从1开始 * */ public void delNodeByIndex(int index){ //判断index是否合理 if(index<1 || index>length()){ System.out.println("给定的位置不合理"); return; } //步骤跟insertNodeByIndex是一样的,只是操作不一样。 int length=1; Node temp = head; while(temp.next != null){ if(index == length++){ //删除操作。 temp.next = temp.next.next; return; } temp = temp.next; } }
1.4计算单链表的长度
/** * 计算单链表的长度,也就是有多少个结点 * @return 结点个数 */ public int length() { int length=0; Node temp = head; while(temp.next != null){ length++; temp = temp.next; } return length; }
1.5遍历单链表,打印data
/**
* 遍历单链表,打印所有data
*/
public void print(){
Node temp = head.next;
while(temp != null){
System.out.print(temp.data+",");
temp = temp.next;
}
System.out.println();
}