题目来自leetcode: 已知一个BST(binary search tree), 将其原地转化成一个循环的排序过的双链表(circular sorted double linked list)。
说明:BST的节点有两个指针left, right, 分别指向比它小,和比它大的节点。变成DLL之后,由于DLL节点原本有prev 和 next 指针分别和之前和之后的节点,这里假定原left指针指向之前,原right 指向之后节点。关于题意可以参考下图:
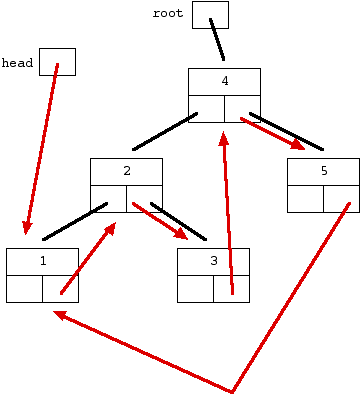
图一. BST to DLL 示例(转)
如图一所示,黑线是原本的BST中left和right指针,红色箭头表示转化成DLL后的next指针(借用原right指针)。
可以感觉到,大体是个遍历BST的过程,天生适合递归。本文会介绍三种解法,虽然都使用递归,但思路各有不同。
方法一:这个方法是我原创的,借鉴了中序遍历(in-order)遍历的思想。
附中序遍历:
void InOrder(node* root){ //LRV
InOrder(root->left);
display(root->val);
InOrder(root->right);
}沿用图一中的BST作为已知。图二展示了当前处理节点2的情况,在函数结束时,将自身作为前向节点去处理节点3。

图二. getTail()
对于DLL的头节点(head), 在递归函数的调用栈中,最底层调用(即最左边叶子节点)时,它的prev为空,因此它就是整个DLL的head。 对于DLL的尾节点(tail),这里最顶层递归函数返回的就是tail,所以这里等顶层递归函数返回后,再将头节点和尾节点链接起来。实现代码如下:
node* getTail(node* curr, node*& pPrev){
if(curr==0) return 0;
node* tmp = getTail(curr->left, pPrev);
if(tmp==0){
if(pPrev==0){
pPrev = curr; //head of sorted DLL
}else{
pPrev->right = curr;
curr->left = pPrev;
}
}else{
tmp->right = curr;
curr->left = tmp;
}
tmp = getTail(curr->right, curr);
return tmp==0 ? curr : tmp;
}
node* BST2SortedDLL_01(node* root){
node *head = 0, *tail = 0;
tail = getTail(root, head);
if(head==0 || tail==0){
return 0;
}
tail->right = head;
head->left = tail;
return head;
}方法二:来自leetcode网站。依然借鉴了中序遍历的思维,不过递归函数不再返回节点给后续,而是在函数体内部就将自身链接成一个闭环的DLL。这样每次都在尾部新插入一个节点,并将头节点跟它链接起来。

图三. bstToDLL(), 插入节点3,和插入节点4
void bstToDLL(node *p, node*& prev, node*& head){
if(!p) return;
bstToDLL(p->left, prev, head);
p->left = prev; //link p and its predecessor(prev)
if(prev)
prev->right = p;
else
head = p;
node *right = p->right; //head stays as the real "head" of DLL, it linked to p in every statement call. as a result, it is linked to
head->left = p; //real "tail" in final function call
p->right = head;
prev = p; //p as the prev of next function call
bstToDLL(right, prev, head);
}
node* BST2SortedDLL_02(node* root){
node *prev = 0;
node *head = 0;
bstToDLL(root, prev, head);
return head;
}方法三:来自leetcode转载,出处在此。这个方法的特点在于利用了分治(divide-and-conquer)的思维,而没有考虑中序遍历。每次把一个节点的左子树,自身节点,右子树都变成一个闭环的双向链表,然后一个一个再链接起来,最后形成一个全树的闭环双向链表。当然,递归是必不可少的。

图四. append() 和 join()
下面是完整代码实现。图四是我根据代码画的示意图,可以帮助理解有关函数。
void join(node* a, node* b){ //link a to b as predecessor of b
a->right = b;
b->left = a;
}
node* append(node* a, node* b){//convert alast->a,blast->b to alast->b, blast->a
if(a==0) return b;
if(b==0) return a;
node *aLast = a->left;
node *bLast = b->left;
join(aLast, b);
join(bLast, a);
return a;
}
node* BST2SortedDLL_03(node* root){
if(root==0) return 0;
node *aList = BST2SortedDLL_03(root->left);
node *bList = BST2SortedDLL_03(root->right);
root->left = root; //unlink root to append to left half, and append right half to left half seperately
root->right = root;
aList = append(aList, root);
aList = append(aList, bList);
return aList;
}不断的合并两个已有的闭环双向链表,需要更多的对于整个问题的大局观,这个解法的确很酷。
小结:
1. 二叉树相关问题,天生适用递归。事实上,树这个概念,就是用递归来定义的。
2. 递归方法,实质是将一个许多步的处理问题,按照某种方式分配成很多份,每一份由一次函数调用来实现。那么我们在设计递归函数中,首先需要考虑如何分配这些处理。比如方法一和方法二,每一次递归函数,仅仅处理(插入)一个新节点进双向链表;方法三中,将当前的左子树,右子树分别放进递归函数中处理。
3. 递归函数是否需要返回值因题而异。很多时候,返回值有助于简化递归函数内部的处理,如方法一。如果有返回值,记得在最顶层的递归函数返回后进行必要处理。如果没有返回值,记得在递归函数内部加以处理,如方法二。
4. 递归函数要特别注意边界情况。最可怕的就是缺乏退出条件从而造成无限循环,那简直是噩梦。