推荐阅读
【小家java】java5新特性(简述十大新特性) 重要一跃
【小家java】java6新特性(简述十大新特性) 鸡肋升级
【小家java】java7新特性(简述八大新特性) 不温不火
【小家java】java8新特性(简述十大新特性) 饱受赞誉
【小家java】java9新特性(简述十大新特性) 褒贬不一
【小家java】java10新特性(简述十大新特性) 小步迭代
java.util.Arrays类能方便的操作数组,它所有的方法都是静态的。Java1.2为我们提供的。其中Java5和Java8都提供了更多增强方法。
Java有个命名习惯或者说是规范,后面加s的都是工具类,比如Arrays、Collections、Executors等等
备注:本博文基于JDK8讲解
有很多开发了很多年的人,只使用过它的asList方法去快速构建一个List,但其实它是非常强大的,可以很大程度上简化我们操作数组的方式。
方法分类介绍
先看几张截图分类
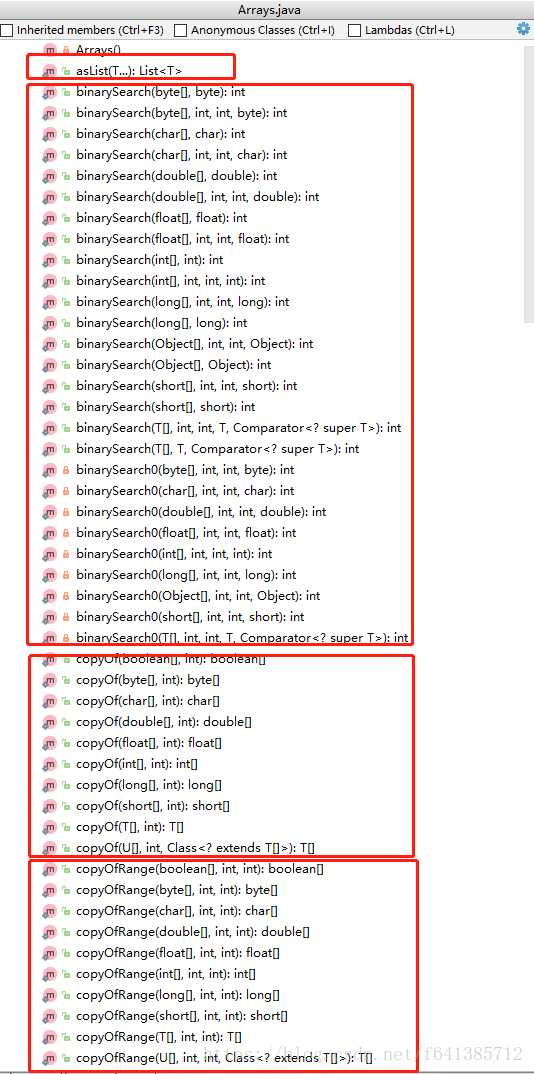
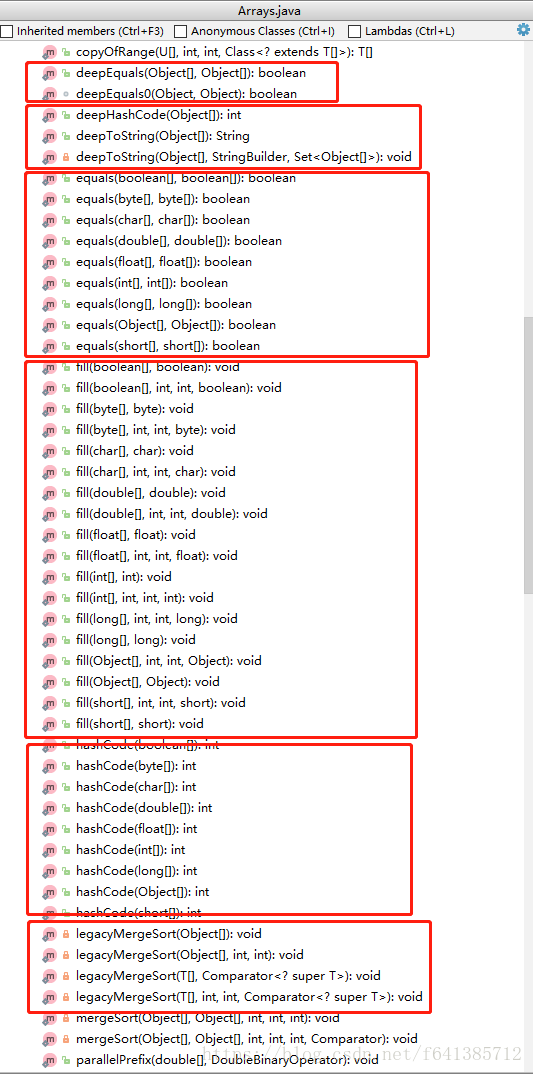
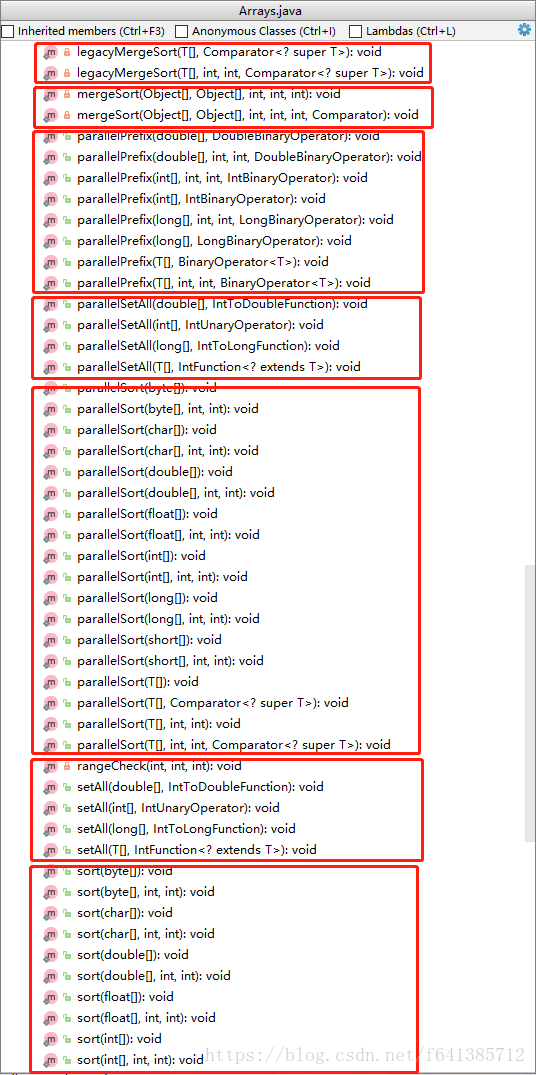
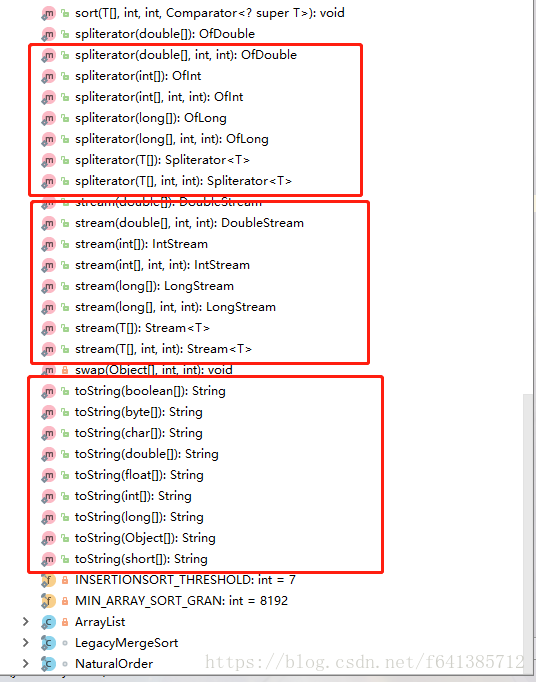
有了这个分类,现在从上到家进行讲解(会进行归类):
asList:快速构建一个list
这个可能不需要我讲解,其实大家都会了。我这里贴出它的实现
public static <T> List<T> asList(T... var0) {
return new Arrays.ArrayList(var0);
} private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{它是自己内部实现的一个ArrayList,使用起来个ArrayList差不多。但是需要注意:注意:注意,它的长度不可变,不能调用remove方法,比如下面就报错:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3);
list.remove(1); //java.lang.UnsupportedOperationException
}binarySearch:二分法查找,数组必须有序
使用二进制搜索算法来搜索指定的 int 型数组,以获得指定的值。
binarySearch()方法提供了多种重载形式,用于满足各种类型数组的查找需要,binarySearch()有两种参数类型。
必须在进行此调用之前对数组进行排序(sort 方法)。如果没有对数组进行排序,则结果是不明确的。如果数组包含多个带有指定值的元素,则无法保证找到的是哪一个。
public static void main(String[] args) {
int a[] = new int[]{1, 3, 4, 6, 8, 9};
int x1 = Arrays.binarySearch(a, 5);
int x2 = Arrays.binarySearch(a, 4);
int x3 = Arrays.binarySearch(a, 0);
int x4 = Arrays.binarySearch(a, 1);
System.out.println(x1); //-4 不存在时从1开始(因为是有序的 所有有角标)
System.out.println(x2); //2
System.out.println(x3); //-1 不存在时从1开始哦 所以值是-1 不是-0
System.out.println(x4); //0 存在时 从0开始
}因为有这么多的限制,所以数组的查找我们其实用得还是比较少的
compare和compareUnsigned
备注:此两个方法是JDK9提供的方法。JDK里没有哦,所以本文不介绍此方法
copyOf和copyOfRange 复制、截取数组
这个在复制数组和截取数组的时候非常有用,推荐使用:
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
//复制出新的数组,复制长度由 newLength 决定,长度可大于被复制数组的长度 也可以小于
Integer[] copyArray1 = Arrays.copyOf(arrayTest, 2); //长度小于
Integer[] copyArray11 = Arrays.copyOf(arrayTest, 15); //长度大于
System.out.println(Arrays.toString(copyArray1)); //[6, 1]
System.out.println(Arrays.toString(copyArray11)); //[6, 1, 9, 2, 5, 7, 6, 10, 6, 12, null, null, null, null, null]
//复制指定下标范围内的值,含头不含尾(这是通用规则)
Integer[] copyArray2 = Arrays.copyOfRange(arrayTest, 2, 7); //截取部分
System.out.println(Arrays.toString(copyArray2));
}equals和deepEquals:比较数组内容是否相等
equals:比较一位数组内容
deepEquals:比较二维数组内容
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
//定义一个二维数组 学生成绩
Integer[][] stuGrades = {{1, 3, 5, 7, 9}, {2, 4, 6, 8}, {1, 5, 10}};
Integer[] equals1 = Arrays.copyOf(arrayTest, arrayTest.length); //完整拷贝
//比较一维数组内容是否相等
System.out.println(Arrays.equals(equals1, arrayTest)); //true
Integer[][] equals2 = Arrays.copyOf(stuGrades, stuGrades.length);
//比较二维数组内容是否相等
System.out.println(Arrays.deepEquals(stuGrades, equals2)); //true
}toString和deepToString
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
//一维数组toString
System.out.println(Arrays.toString(arrayTest));
Integer[][] stuGrades={{1,3,5,7,9},{2,4,6,8},{1,5,10}};
//二维数组toString
System.out.println(Arrays.deepToString(stuGrades));
}hashCode和deepHashCode
基本同上,例子略
fill:将一个数组全部置为 val ,或在下标范围内将数组置为 val
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
//Integer[] arrayTest = new Integer[5];
//将一个数组置为 val(5)
Arrays.fill(arrayTest,5);
System.out.println(Arrays.toString(arrayTest)); //[5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
//将一个数组指定范围内置为 val(10) 含头不含尾
Arrays.fill(arrayTest,2,3,10); //通过角标 可以控制可以批量换值
System.out.println(Arrays.toString(arrayTest)); //[5, 5, 10, 5, 5, 5, 5, 5, 5, 5]
}setAll和parallelSetAll:JDK有歧义的实现方式
这个有点类似于Stream里的Map,但是JDK的实现有bug。
setAll的语义,作者的元思想肯定是希望处理each element,但是我们看看源码:
public static <T> void setAll(T[] array, IntFunction<? extends T> generator) {
Objects.requireNonNull(generator);
for (int i = 0; i < array.length; i++)
array[i] = generator.apply(i);
}generator.apply(i);它竟然用的是i,而不是array[i],所以此处我们使用的时候一定要万分注意,回调给我们的是角标,而不是值,而不是值
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
Integer[] setAllArr = Arrays.copyOf(arrayTest, arrayTest.length);
//一个数组全部做表达式操作
System.out.println(Arrays.toString(setAllArr)); //[6, 1, 9, 2, 5, 7, 6, 10, 6, 12]
//一定要注意 此处我们需要用setAllArr[i]才是我们想要的结果
Arrays.setAll(setAllArr, i -> setAllArr[i] * 3);
//Arrays.setAll(setAllArr, i -> i * 3);
System.out.println(Arrays.toString(setAllArr)); //[18, 3, 27, 6, 15, 21, 18, 30, 18, 36]
}看到这种使用方式,很逆天有没有。真不知道是JDK的设计者脑子进水了,还是进水了,因为处理角标没任何意义,至少我是不太同意这种设计的。
一次同样的parallelSetAll也是采用的角标,他们的区别只是一个串行,一个并行。
stream 这个就不解释了
parallelPrefix:二元迭代,对原数组内容进行二元操作
这个解释起来比较麻烦,直接先看一个例子吧
public static void main(String[] args) {
Integer[] arrayTest = {6, 1, 9, 2, 5, 7, 6, 10, 6, 12};
Integer[] arrayPP1 = Arrays.copyOf(arrayTest, arrayTest.length);
System.out.println(Arrays.toString(arrayPP1)); //[6, 1, 9, 2, 5, 7, 6, 10, 6, 12]
//二元迭代,对原数组内容进行二元操作
Arrays.parallelPrefix(arrayPP1, (x, y) -> x * y);
System.out.println(Arrays.toString(arrayPP1)); //[6, 6, 54, 108, 540, 3780, 22680, 226800, 1360800, 16329600]
//在指定下标范围内,对原数组内容进行二元操作,下标含头不含尾
Integer[] arrayPP2 = Arrays.copyOf(arrayTest, arrayTest.length);
Arrays.parallelPrefix(arrayPP2, 0, 5, (x, y) -> x * y);
System.out.println(Arrays.toString(arrayPP2)); //[6, 6, 54, 108, 540, 7, 6, 10, 6, 12]
}从效果中我们可以看出来,这个就是拿前面的结果,和当前元素做运算。这个运算规则,由我们自己来定义。
使用场景:这个在一些数学运算中,会比较好用
sort和parallelSort:算法精华
排序一直以来效率是很依赖于算法的,所以我们抽查一个源码看看它的精妙之处:
static void sort(byte[] a, int left, int right) {
// Use counting sort on large arrays
if (right - left > COUNTING_SORT_THRESHOLD_FOR_BYTE) {
int[] count = new int[NUM_BYTE_VALUES];
for (int i = left - 1; ++i <= right;
count[a[i] - Byte.MIN_VALUE]++
);
for (int i = NUM_BYTE_VALUES, k = right + 1; k > left; ) {
while (count[--i] == 0);
byte value = (byte) (i + Byte.MIN_VALUE);
int s = count[i];
do {
a[--k] = value;
} while (--s > 0);
}
} else { // Use insertion sort on small arrays
for (int i = left, j = i; i < right; j = ++i) {
byte ai = a[i + 1];
while (ai < a[j]) {
a[j + 1] = a[j];
if (j-- == left) {
break;
}
}
a[j + 1] = ai;
}
}
}如果大于域值那么就使用计数排序法,否则就使用插入排序。
parallelSort是java8中新出的一种排序API,这是一种并行排序,Arrays.parallelSort使用了Java7的Fork/Join框架使排序任务可以在线程池中的多个线程中进行,Fork/Join实现了一种任务窃取算法,一个闲置的线程可以窃取其他线程的闲置任务进行处理。
性能对比结论:数组数据量越大,parallelSort的优势就越明显。
jdk源码中写的排序算法都很精简,值得学习
spliterator:最优的遍历
这是JDK为了高级遍历数组而提供的一个方法。具体使用方式,会在后续讲解spliterator迭代器的时候专题讲解