python3 爬虫学习日记【一】
前段时间学完了python3的基本语法,今天开始学习爬虫,慢慢记录下,也是为以后写神经网络做好准备,毕竟别人不会给你数据,只能自己去爬了
之前在看《遮天》,正好拿它来练练手。
我用request和BeautifulSoup来写爬虫,优雅华丽~
- 写个爬网页文章的爬虫,首先要封装一个header,因为现在的网站基本都有请求来源的判断,不做简单的伪装,一般是会被目标服务器的拦截器拦掉的。
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'- 其次就是请求的封装,构建一个request,调用urlopen的方法请求url,获取到响应的response后,读取html
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()- 构建BeautifulSoup,取到需要的文字部分
soup = BeautifulSoup(html, 'lxml')
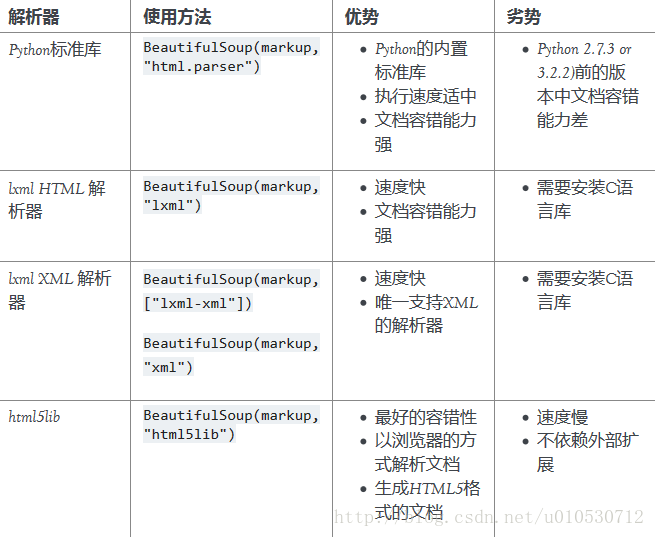
soup_texts = soup.find('div',id='list')传入参数为html和解析器类别(下图),BeautifulSoup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,可以直接通过html里的元素查询,find返回的是<div id='list'></div>这个div包含的内容
PS.保存成txt或其他文档时,建议用with open(‘d:\’,’w’) as f,这样就不用再去操作文档的f.close()
好了,大致的流程看完了,接下来说说抓一本书
要抓取一本完整的小说。首先要抓到他的目录
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'http://www.qu.la/book/394/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req=request.Request(url,headers=head)
response=request.urlopen(req)
html = response.read()
soup = BeautifulSoup(html,'lxml')
# print(soup.title.string)
soup_text = soup.find('div',id='list')
coup_contents = soup_text.dl.contents
for i in range(len(coup_contents)):
#这里i>2是因为抓取的id='list'到目录中间还有个html的元素,跳过它
if coup_contents[i] !='\n' and i>2:
print(coup_contents[i].text)
print(coup_contents[i].a.get('href'))然后是抓其中一章的内容
from urllib import request
from bs4 import BeautifulSoup
import re
if __name__ == '__main__':
url = 'http://www.qu.la/book/394/296472.html'
#url = 'http://www.136book.com/huaqiangu/ebxeew/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req=request.Request(url,headers=head)
response=request.urlopen(req)
html=response.read()
soup=BeautifulSoup(html,'lxml')
contents=soup.find('div',attrs={'id':'content'})
rege=r'<div id="content">(.*)泰国.*'
scon=re.findall(rege,str(contents.prettify()),re.S)
with open('e:\save.txt','w') as f:
for content in scon:
f.write(str(content).replace("<br/>",""))
下面的合成版,小伙伴看看就好,自己动手爬本小说吧~~~
from urllib import request
from bs4 import BeautifulSoup
import re
if __name__ == '__main__':
url = 'http://www.qu.la/book/394/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
soup_texts = soup.find('div',id='list')
with open('E:/'+soup.title.string+'.txt','w') as f:
coup_contents = soup_texts.dl.contents
for i in range(len(coup_contents)):
link = coup_contents[i]
if link != '\n' and i>2:
download_url = 'http://www.qu.la'+link.a.get('href')
download_req = request.Request(download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read()
download_soup = BeautifulSoup(download_html, 'lxml')
download_soup_texts = download_soup.find('div', id = 'content')
download_soup_texts = download_soup_texts.prettify()
rege=r'<div id="content">(.*)泰国.*'
scon=re.findall(rege,str(download_soup_texts),re.S)
for content in scon:
f.write(str(content).replace("<br/>",""))