GOTURN 网络理解
作者采用完全离线的方式进行训练,然后对目标进行跟踪,将追踪能做到100fps(是指在gtx 680上),当使用泰坦x 时能到160+fps ,数度确实很快,这样的离线训练,以及能在680上实现100fps,是对商业应用上有着提高。
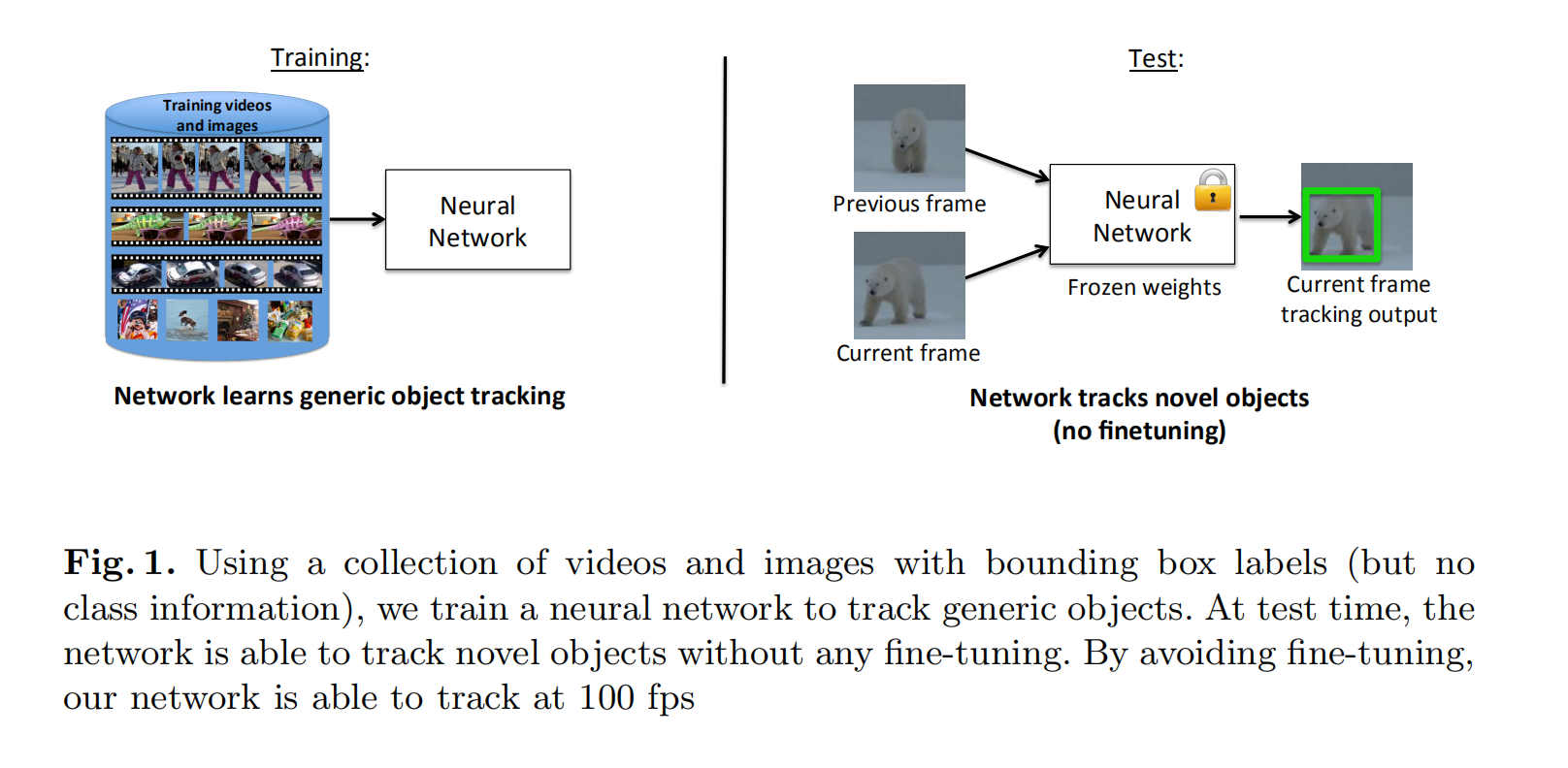
在以前的深度跟踪的工作中大多数都是不能满足实时性的要求: 在这之前的cnn做到7fps
穿插一下,这篇文章是2016年的,目前深度追踪发展迅速,很多已超越GOTURN网络,(目前大家对于这篇文章评价不是很高,因为kcf在数度上使用cpu训练已经可以达到170+fps的速度):这篇文章的网络类似于simese 网路:(后续续继续看simesefc这篇文章:来自牛津Luca Bertinetto大佬的SiameseFC tracker):
先贴网络:
转正题:
下面介绍一下GOTURN net 的输入与输出:
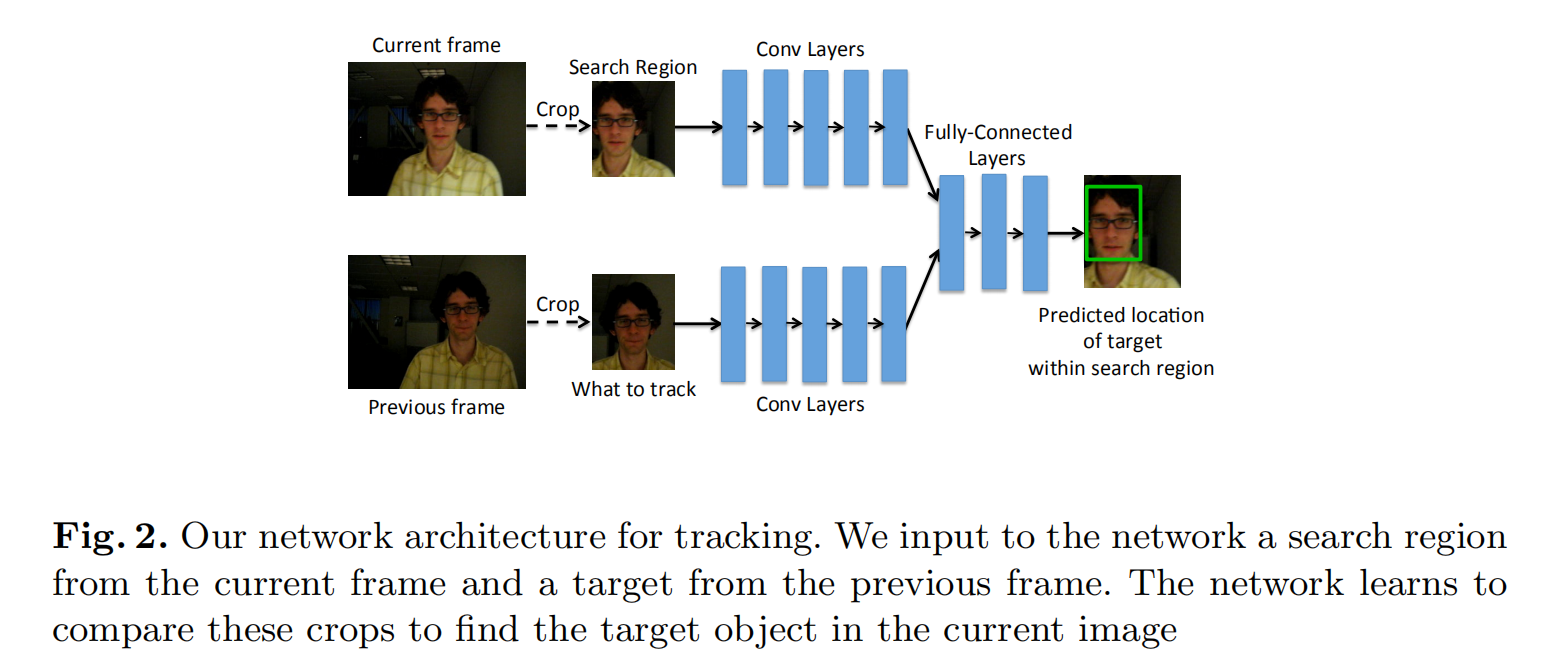
可视化整体网络结构:
输入1:当前帧图片,进行crop 得到带目标的中心的区域,
输入2: 输入当前帧,进行crop 的到search region :
在第Previous frame帧中,假设目标所在位置为(cx,cy),其大小为(w,h),则提取一块大小为(2w,2h)的图像块输入到CNN中。 为什么要选择2 ,这就是作者提出的新思想哈(根据目标框的拉普拉斯分布)
在第当前帧中,也以(cx,cy)为中心,提取大小为(2w,2h)的图像块,输入到CNN中
通过输入前后两幅图像
输出目标的窗口(左上角坐标和右下角坐标)。
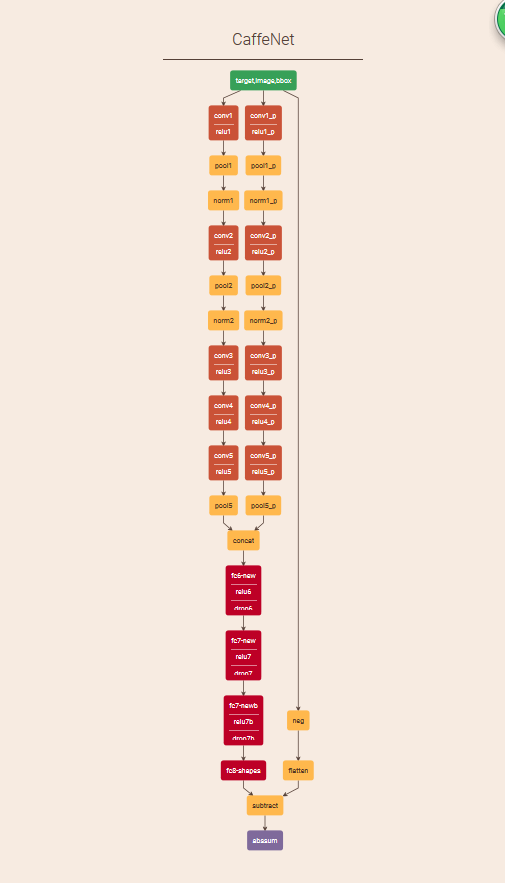
卷积层网络结构的作用:
卷积层是采用的5层结构(这里的5层结构是参照了CaffeNet里面的结构,其中卷积层的激励函数都采用了relu激励函数,部分卷积层后面添加了池化层)(
卷积层,用于提取目标区域和搜索区域的特征 ),并在imagenet上fine-tue进行预训练。
而全连接层则是由3层,每层4096个节点,各层之间采用dropout(
补充:理解dropout)和relu激励函数,以防过拟合和梯度消失。(全连接层,用于比较目标特征和搜索区域特征,输出新的目标位置.)输出则是一个四维向量,分别是跟踪窗口左上角和右下角坐标.
整个算法实现的框架如上图:作者将上一帧的目标和当前帧的搜索区域同时经过CNN的卷积层(Conv Layers),然后将卷积层的输出通过全连接层(Fully-Connected Layers),用于回归(regression)当前帧目标的位置。
文中训练时loss function 采用的是L1-loss
损失函数则是采用的
L
1
-Loss
的方式

作者给出几种训练数据的俄对比表格:
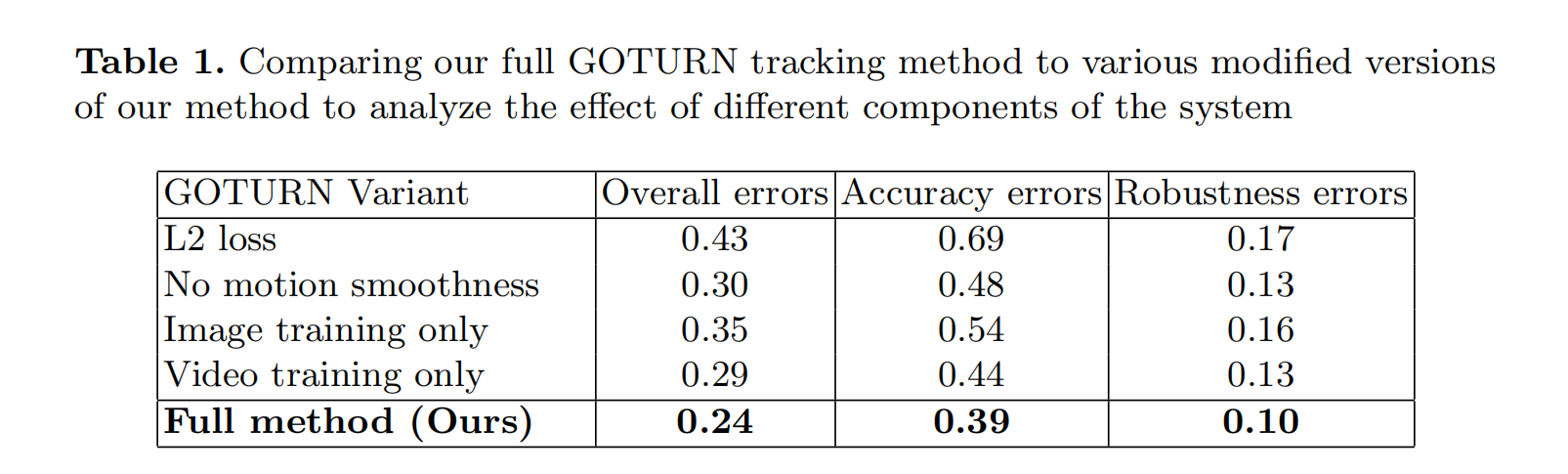
本文的特殊点:
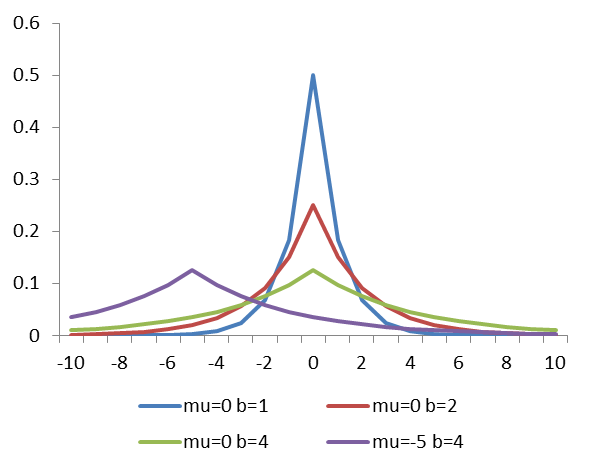
目前没有人去研究目标位置与尺度的关系,但是作者通过groundtruth进行研究,前帧目标的位置和尺度变化与上一帧的目标存在着某种分布关系,符合拉普拉斯分布:对于具体的拉普拉斯分布的介绍在论文后有详细的介绍:
在看完论文后,下一篇有介绍代码的实现: