2.1 CUDA并行模式
从串行到CUDA并行同时涉及硬件和软件两方面。
硬件的转换涉及包含了多个运算单元以及运算规划和数据传输机制的芯片。
软件的转换涉及API以及对编程语言的扩展。
主机:CPU和内存
设备:GPU和显存
CUDA芯片结构:
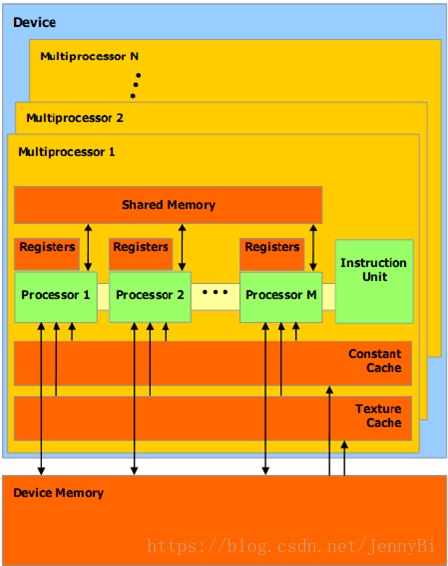
CUDA引用了单指令多线程(SIMT)的并行模式。
CUDA GPU包含了大量的基础计算单元,这些单元被称为核(core),每一个核包含了一个逻辑计算单元(ALU)和一个浮点计算单元(FPU)。多个核集成在一起被称为多流处理器(SM)。
•SP:最基本的处理单元,streaming processor,也称为CUDA core。包含独立的寄存器和程序计数器。
•SM:streaming multiprocessor,也叫GPU大核,可以看做GPU的心脏(对比CPU核心)。包括取指和调度单元。
CUDA编程模型
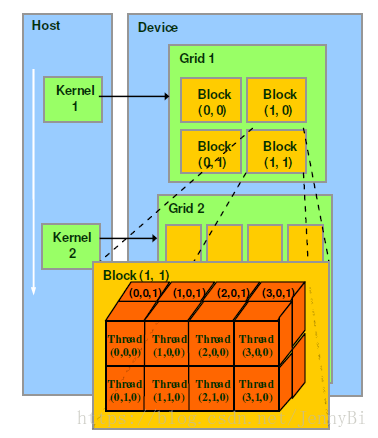
•Thread:一个CUDA的并行程序有多个threads来执行。
•Block:数个threads群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。(线程块被分解为大小与一个SM中核数量相同的线程束Warp,每个线程束由一个特定的多流处理器执行。)
•Grid:多个blocks则会再构成grid。
•Warp(硬件角度):SM执行程序时的调度单位,目前CUDA的warp的大小为32“线程”,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
2.2 需要知道的CUDA API和C语言扩展
__global__ 是标志着核函数的标识符(可以在主机端调用并在设备端执行)
__host__函数从主机端调用在主机端执行(可省略)
__device__函数从设备端调用并在设备端执行。(从核函数中调用的函数需要有__device__限定符)
在函数头添加__host____device__函数会让系统分别编译这个函数的主机版本和设备版本。
核函数有几个值得注意的权限和限制:
- 核函数不能带有返回值,因此返回类型通常为void。并且核函数需如下声明:
- __global__ void aKernel(typedArgs)
- 核函数提供了对于每一个线程块和线程的维度数和索引变量。
- 维度数目变量:
- gridDim声明了网格中的线程块数目。
- blockDim声明了每个线程块中的线程数目。
- 索引变量:
- blockIdx给出了这个线程块在网格中的索引。
- threadIdx给出了这个线程在线程块中的索引。
- 在GPU上执行的核函数通常不能访问主机端CPU可以访问的内存中的数据。
CUDA运行时API提供了一些可以将输入数据传输到设备端和将结果传回到主机端的函数:
- cudaMalloc()函数可以分配设备端内存
- cudaMemcpy()将数据传入或传出设备
- cudaFree()释放掉设备中不再使用的内存
CUDA为需要同步和并发执行时提供了相应的函数:
- __syncThreads()可以在一个线程块中进行线程同步
- cudaDeviceSynchronize()函数可以有效地同步一个网格中的所有线程
- 原子操作,例如atomicAdd(),可以防止多线程并发访问一个变量时造成的冲突。
CUDA提供的一些额外的数据类型:
- size_t:代表内存大小的专用变量类型
- cuda_Error_t:错误处理的专用变量。
- 向量类型:CUDA将标准C的向量数据类型扩展到了4个。独立的组件通过后缀.x .y .z .w进行访问。
向量类型的关键重要用法:
CUDA在blockIdx和threadIdx上使用uint3向量类型。uint3变量是一个包含了三个整型数的向量。
CUDA在gridDim和blockDim上使用了dim3向量类型。dim3类型与uint3一样,但将为声明的变量设置为1。