用户日志:
访问的系统属性:操作系统、浏览器类型
访问特征:点击的URL、来源(referer)url [推广]、页面停留时间
访问信息:session_id,访问IP
价值:分析每个用户的使用场景频率高的业务点,分析每个用户的IP 【解析到城市信息】,根据用户浏览商品打浏览标签精准推荐商品 等等…
- 数据处理
有数据者有未来,有数据意味着每一份用户行为数据都是宝贵的资源。经过数据清洗,再用算法提取分析,商业价值,商业决策、线上推广 等等….当然一切建立在有大量用户有流量的情况下的。
数据处理流程
数据采集:
Flume:将记录的用户行为日志提取至HDFS
数据清洗:
脏数据
Spark、Hive、MapReduce 或者是其他的分布式计算框架
清洗完的数据可以放到HDFS(HDFS,Spark SQL)
数据处理:
按照我们的需要进行相应的业务统计与分析
Spark、Hive、MapReduce 或者是其他的分布式计算框架
处理结果入库:
分析处理结果数据存储至:NoSQL、RDBMS
数据可视化
通过图形化展示出计算出来的数据结果
Echarts、HUE 等…
- 大数据处理架构
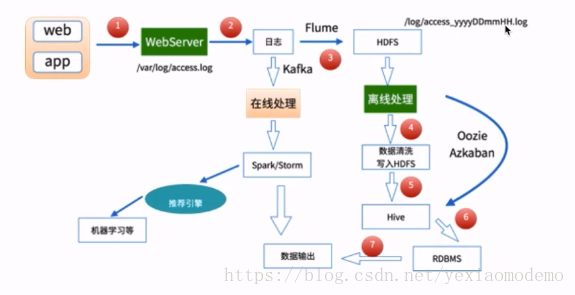
一个典型的简单版本的用户行为大数据处理架构。离线数据处理