RankBoost的思想比较简单,是二元Learning to rank的常规思路:通过构造目标分类器,使得pair之间的对象存在相对大小关系。通俗点说,把对象组成一对对的pair,比如一组排序r1>r2>r3>r4,那可以构成pair:(r1,r2)(r1,r3),(r1,r4),(r2,r3)(r3,r4),这样的pair是正值,也就是label是1;而余下的pair如(r2,r1)的值应该是-1或0。这样一个排序问题就被巧妙的转换为了分类问题。近来CV界很多又用这种learning to rank的思想做识别问题(最早应该是这篇《Person Re-Identification by Support Vector Ranking》),也就是把识别转换为排序问题再转换为分类问题。
Pairwise的排序方法主要用RankSVM和RankBoost,这里主要说RankBoost,整体还是一个Boost的框架:

注意其与常规Boost的不同组要是Update的时候,当然数据分布也不同。这里可以看出对于最终的排序值,也就是ranking score,其值是没有实际意义的,相对的顺序才有意义。比如r1和r2最终得分是10分和1分,与r1,r2最终得分是100分和1分的信息量差别并不大,我们能得到的结论都是r1应该排在r2前面。
由于和传统的Boost目标不一样,求解也需要非常巧妙的方法,主要在于定义分类器的Loss函数:
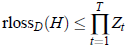
具体的,由于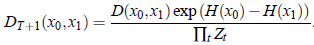
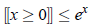
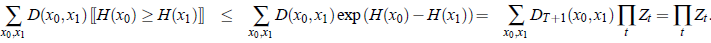
于是,目标就变成了最小化
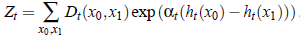
至此,传统的Boost线性搜索策略已经可以求解,但还有更巧妙的办法。由于函数:
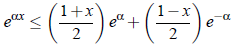
于是,对于所以[-1 1]范围内的x,Z可以近似为:
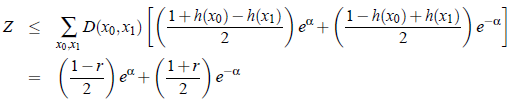
其中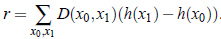
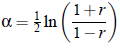
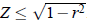
以下是一段RankBoost的代码:
function [ rbf ] = RankBoost( X,Y,D,T )
%RankBoost implemetation of RankBoost algoritm
% Input:
% X - train set.
% Y - train labels.
% D - distribution function over X times X, it the form of 2D matrix.
% T - number of iteration of the boosting.
% Output:
% rbf - Ranking Function.
rbf = RankBoostFunc(T);
% w - the current distribution in any iteration, initilize to D
w = D;
for t=1:T
tic;
fprintf('RankBoost: creating the function, iteration %d out of %d\n',t,T);
WL = getBestWeakLearner(X,Y,w);
rbf.addWeakLearner(WL,t);
rbf.addAlpha(WL.alpha,t);
alpha=WL.alpha;
%update the distribution
%eval the weak learnler on the set of X and Y
h=WL.eval(X);
[hlen, ~] = size(h);
tmph = (repmat(h,1,hlen) - repmat(h',hlen,1));
w=w.*exp(tmph.*alpha);
%normalize w
w = w./sum(w(:));
toc;
end
end一个比较明显的问题是RankBoost需要维持一个非常大的|X|*|X|的矩阵,程序运行十分占内存,经常抛出“Out of memory”的错误。所以诸如
tmph = (repmat(h,1,hlen) - repmat(h',hlen,1)); % tmph = (repmat(h,1,hlen) - repmat(h',hlen,1));
%w=w.*exp(tmph.*alpha);
[rows, cols] = size(w);
sumw = 0;
for r=1:rows
for c=1:cols
w(r,c) = w(r,c)*exp((h(r)-h(c))*alpha);
sumw = sumw + w(r,c);
end
end
%normalize w
%w = w./sum(w(:));
w = w./sumw;