CVPR 2018 ORAL 零样本学习新进展:使用鉴别性特征实现零样本识别
ZSL
零样本学习(zero-shot learning, ZSL)详细的解释见郑哲东在知乎中的回答。它的目标是将学习到的特征映射到另一个空间,进而映射到已见和未见类别的属性或者标签上。
本文亮点:在学习了已定义标签的同时,学习了隐含属性。
Abstract
摘要:零样本学习(ZSL)的目标是通过学习图像表征和语义表征之间的嵌入空间来识别未曾见过的图像类别。多年以来,在已有的研究成果中,这都是学习对齐视觉空间和语义空间的合适映射矩阵的中心任务,而学习用于ZSL 的鉴别性表征的重要性却被忽视了。在本研究中,我们回顾了已有的方法,并表明了为 ZSL的视觉和语义实例学习鉴别性表征的必要性。我们提出了一种端到端的网络,能够做到:1)通过一个缩放网络自动发现鉴别性区域;2)在一个为用户定义属性和隐含属性引入的扩增空间中学习鉴别性语义表征。我们提出的方法在两个有挑战性的ZSL 数据集上进行了大量测试,实验结果表明我们提出的方法的表现显著优于之前最佳的方法。
Introduction
已有方案的缺点(drawbacks):
1,在映射前,抽取图像的特征,传统的用预训练模型等方法仍不是针对ZSL特定抽取特征的最优解。
2,现有的都是学习用户定义属性,而忽略了隐含表示。
3,低层次信息和空间是分离训练的,没有大一统的框架。
本文便是对应着解决了以上问题。
贡献:
- 一种级联式缩放机制,可用于学习以目标为中心的区域的特征。我们的模型可以自动识别图像中最具鉴别性的区域,然后在一个级联式的网络结构中将其放大以便学习。通过这种方式,我们的模型可以专注于从以目标为焦点的区域中学习特征。
- 一种用于联合学习隐含属性和用户定义的属性的框架。我们将隐含属性的学习问题形式化为了一个类别排序问题,以确保所学习到的属性是鉴别性的。同时,在我们模型中,鉴别性区域的发掘和隐含属性的建模是联合学习的,这两者会互相协助以实现进一步的提升。
- 一种用于 ZSL 的端到端网络结构。所获得的图像特征可以调整得与语义空间更加兼容,该空间中既包含用户定义的属性,也包含隐含的鉴别性属性。
Our Method - Latent Discriminative Features Learning(LDF)
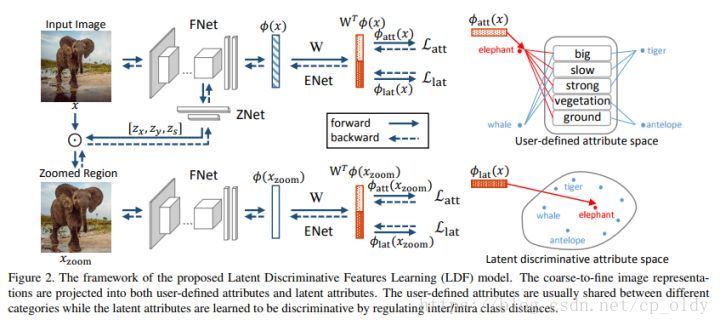
Notation:
FNet (The Image Feature Network) :提取图像特征;
ZNet(The Zoom Network): 定位最具判别性的区域并将其放大;
ENet(The Embedding Network): 将图像特征映射到另一个空间。
问题
1. ZNet是如何定位判别性区域的?
下面我们先介绍各个子网络
FNet
FNet的目标就是提取图像特征。文章选择了已有的VGG19/GoogleNet。
ZNet
动机
已有研究表明对目标的区域进行学习,有利于图像级的目标分类。受此启发,我们假设图像中存在判别性区域有助于ZSL。
ZNet的目标是定位到能够增强我们提取的特征的辨识度的区域,这个区域同时也要与某一个我们已经定义好了的属性对应。
- ZNet的输入是FNet的最后一个卷积层的输出。
- 在这里运用某个已有的激活函数方法,将我们定位好了的区域提取出来,即将裁剪操作在网络中直接实现。
- 将ZNet的输出与输入图像做按像素的矩阵乘法。
- 最后,将区域放大到与输入图像相同的尺寸。
如图2所示,再将ZNet的输出输入到另一个FNet(第一个FNet的拷贝)
ENet
ENet的目的是学习一个能够将视觉和语义信息关联起来的嵌入空间。
作者提出了一个兼容性得分。
其中, 是FNet输出的 维的图像表示, 是注释属性向量。
兼容性得分的物理意义是什么?
答:衡量一张图像在属性空间的投影和类别的定义/隐含属性之间的相似性(兼容性)。
Enet将图像特征映射到2k维度的空间中。其中,1k维对应于用户定义属性(UA),并用softmax loss;另1k维则是对应潜藏属性,为了使这些特征具有判别性,作者使用了triplet loss。
为什么UA是softmax loss,而LA是triplet loss?
答:???。