前提安装好scrapy模块最好 requests和bs4模块都安装好
可以概括为五个步骤
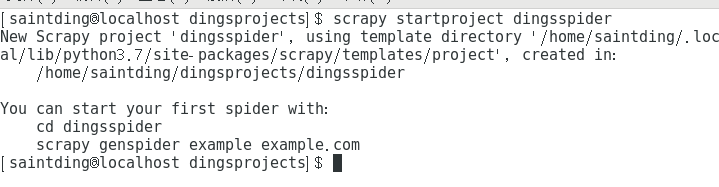
步骤一:新建一个项目
无论你用windows也好,linux也罢,在cmd或者终端 切换到目标文件夹,然后输入命令
scrapy startproject dingsspider(自定义的项目名)
步骤二:生成爬虫
如同shell终端提示的那样,要生成爬虫
重要提示:执行命令时你有可能遇到一个错误,可能不是由于你的代码语法错误,而是来自源代码的错误,请看如下帖子
http://bbs.51cto.com/thread-1547185-1.html
解决方案截图如下:

解决上述问题后,运行命令
scrapy genspider wenwa wenwa.com
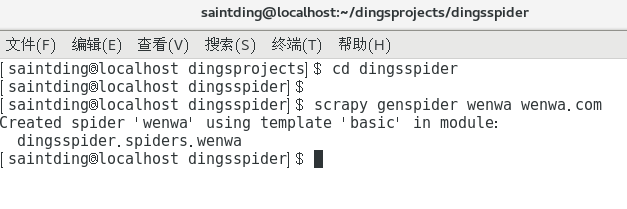
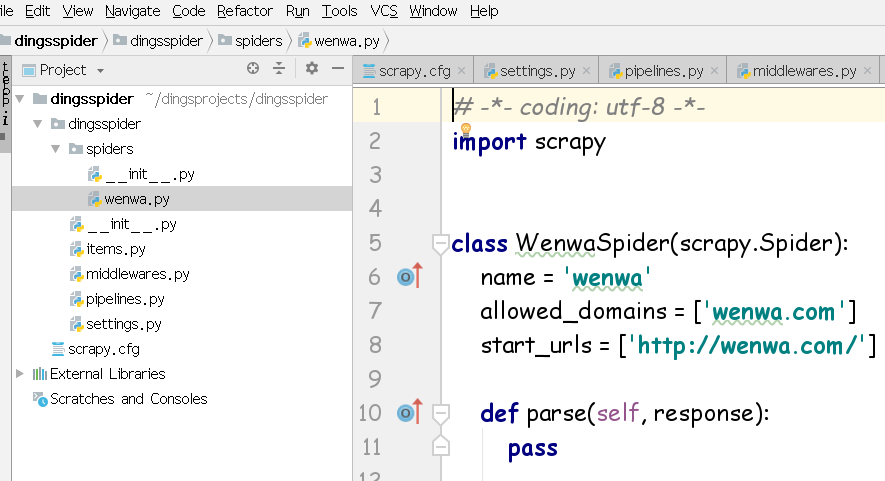
哟比~有了项目架构,我们就可以通过改写相关的爬虫类,实现爬虫的运转了
爬取一个网页,以著名编程知识网站runnoob为例,因为朕要学习php(找个python编程工作怎么就JB那么难,大爷的)
在步骤二中,已经通过genspider 命名了一个文件wenwa,那么在爬虫项目中找到同名文件wenwa.py,修改如下:
import scrapy
class WenwaSpider(scrapy.Spider):
name = 'wenwa'
allowed_domains = ['www.runoob.com']
start_urls = ['http://www.runoob.com/php/php-tutorial.html']
def parse(self, response):
filename = response.url.split("/")[-2]+".html"
with open(filename,"wb") as p:
p.write(response.body)
allow_domians显示了要爬去的主域名,start_urls则是我们要爬取的页面,parse中filename完全是拆分start_urls后形成的列表里面,拿出一个元素给装载爬取结果的文件命名,如果觉得晕,随便取个名字就好
成功生成文件php.html,如下图

打开一看,瓦嗷~真tm丑,不过总算成功了,瓦卡卡