一、YARN通信协议
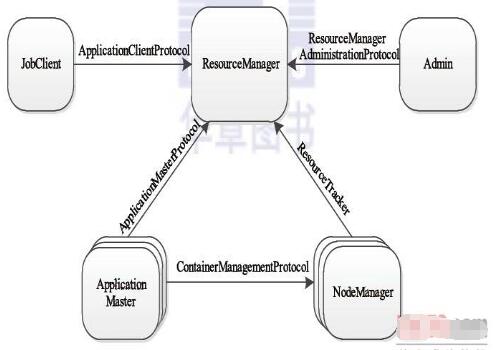
YARN通信协议,RPC协议是连接各个组件的“大动脉”,了解不同组件之间的RPC协议有助于我们更深入地学习YARN框架。在YARN中,任何两个需相互通信的组件之间仅有一个RPC协议,而对于任何一个RPC协议,通信双方有一端是Client,另一端为Server,且Client总是主动连接Server的,因此,YARN实际上采用的是拉式(pull-based)通信模型。如图,箭头指向的组件是RPC Server,而箭头尾部的组件是RPC Client,YARN主要由以下几个RPC协议组成:
JobClient(作业提交客户端)与RM之间的协议—ApplicationClientProtocol:JobClient通过该RPC协议提交应用程序、查询应用程序状态等。
Admin(管理员)与RM之间的通信协议—ResourceManagerAdministrationProtocol:Admin通过该RPC协议更新系统配置文件,比如节点黑白名单、用户队列权限等。
AM与RM之间的协议—ApplicationMasterProtocol:AM通过该RPC协议向RM注册和撤销自己,并为各个任务申请资源。
AM与NM之间的协议—ContainerManagementProtocol:AM通过该RPC要求NM启动或者停止Container,获取各个Container的使用状态等信息。
NM与RM之间的协议—ResourceTracker:NM通过该RPC协议向RM注册,并定时发送心跳信息汇报当前节点的资源使用情况和Container运行情况。
为了提高Hadoop的向后兼容性和不同版本之间的兼容性,YARN中的序列化框架采用了Google开源的Protocol Buffers(高效)。Protocol Buffers的引入使得YARN具有协议向后兼容性。
二、YARN RPC实现
YARN RPC实现,当前存在非常多的开源RPC框架,比较有名的有Thrift、Protocol Buffers和Avro。同Hadoop RPC一样,它们均由两部分组成:对象序列化和远程过程调用(Protocol Buflers官方仅提供了序列化实现,未提供远程调用相关实现,但三方RPC库非常多)。相比于Hadoop RPC,它们有以下几个特点:
跨语言特性。前面提到,RPC框架实际上是客户机–服务器模型的一个应用实例,对于Hadoop RPC而言,由于Hadoop采用Java语言编写,因而其RPC客户端和服务器端仅支持Java语言;但对于更通用的RPC框架,如Thrift或者Protocol Buffers等,其客户端和服务器端可采用任何语言编写,如Java、C++、Python等,这给用户编程带来极大方便。
引入IDL。开源RPC框架均提供了一套接口描述语言(Interface Description Language,IDL),它提供一套通用的数据类型,并以这些数据类型来定义更为复杂的数据类型和对外服务接口。一旦用户按照IDL定义的语法编写完接口文件后,可根据实际应用需要生成特定编程语言(如Java、C++、Python等)的客户端和服务器端代码。
协议兼容性。开源RPC框架在设计上均考虑到了协议兼容性问题,即当协议格式发生改变时,比如某个类需要添加或者删除一个成员变量(字段)后,旧版本代码仍然能识别新格式的数据,也就是说,具有向后兼容性。
随着Hadoop版本的不断演化,研发人员发现Hadoop RPC在跨语言支持和协议兼容性两个方面存在不足,具体表现为:
从长远发展看,Hadoop RPC应允许某些协议的客户端或者服务器端采用其他语言实现,比如用户希望直接使用C/C++语言读写HDFS中的文件,这就需要有C/C++语言的HDFS客户端。
当前Hadoop版本较多,而不同版本之间不能通信,比如0.20.2版本的JobTracker不能与0.21.0版本中的TaskTracker通信,如果用户企图这样做,会抛出VersionMismatch异常。
为了解决以上几个问题,Hadoop YARN将RPC中的序列化部分剥离开,以便将现有的开源RPC框架集成进来。经过改进之后,Hadoop RPC的类关系,RPC类变成了一个工厂,它将具体的RPC实现授权给RpcEngine实现类,而现有的开源RPC只要实现RpcEngine接口,便可以集成到Hadoop RPC中。,WritableRpcEngine是采用Hadoop自带的序列化框架实现的RPC,而AvroRpcEngine和ProtobufRpcEngine分别是开源RPC(或序列化)框架Apache Avro和Protocol Buffers对应的RpcEngine实现,用户可通过配置参数rpc.engine.{protocol}以指定协议{protocol}采用的序列化方式。需要注意的是,当前实现中,Hadoop RPC只是采用了这些开源框架的序列化机制,底层的函数调用机制仍采用Hadoop自带的。
YARN提供的对外类是YarnRPC,用户只需使用该类便可以构建一个基于Hadoop RPC且采用Protocol Buffers序列化框架的通信协议。
Yarn RPC是一个抽象类,实际的实现由参数yarn.ipc.rpc.class指定,默认值是org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC。HadoopYarnProtoRPC通过RPC工厂生成器(工厂设计模式),RpcFactoryProvider生成客户端工厂(由参数yarn.ipc.client.factory.class指定,默认值是org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl)和服务器工厂(由参数yarn.ipc.server.factory.class指定,默认值是org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl),以根据通信协议的Protocol Buffers定义生成客户端对象和服务器对象。
RpcClientFactoryPBImpl:根据通信协议接口(实际上就是一个Java interface)及Protocol Buffers定义构造RPC客户端句柄,但它对通信协议的存放位置和类名命有一定要求。假设通信协议接口Xxx所在Java包名为XxxPackage,则客户端实现代码必须位于Java包XxxPackage.impl.pb.client中(在接口包名后面增加“.impl.pb.client”),且实现类名为PBClientImplXxx(在接口名前面增加前缀“PBClientImpl”)。
RpcServerFactoryPBImpl:根据通信协议接口(实际上就是一个Java interface)及Protocol Buffers定义构造RPC服务器句柄(具体会调用前面节介绍的RPC.Server类),但它对通信协议的存放位置和类命名有一定要求。假设通信协议接口Xxx所在Java包名为XxxPackage,则客户端实现代码必须位于Java包XxxPackage.impl.pb.server中(在接口包名后面增加“.impl.pb.server”),且实现类名为PBServiceImplXxx(在接口名前面增加前缀“PBServiceImpl”)。
Hadoop YARN已将Protocol Buffers作为默认的序列化机制(而不是Hadoop自带的Writable),这带来的好处主要表现在以下几个方面:
**继承了Protocol Buffers的优势。**Protocol Buffers已在实践中证明了其高效性、可扩展性、紧凑性和跨语言特性。首先,它允许在保持向后兼容性的前提下修改协议,比如为某个定义好的数据格式添加一个新的字段;其次,它支持多种语言,进而方便用户为某些服务(比如HDFS的NameNode)编写非Java客户端;此外,实验表明Protocol Buffers比Hadoop 自带的Writable在性能方面有很大提升。
**支持升级回滚。**Hadoop 2.0已经将NameNode HA方案合并进来,在该方案中,Name-Node分为Active和Standby两种角色,其中,Active NameNode在当前对外提供服务,而Standby NameNode则是能够在Active NameNode出现故障时接替它。采用Protocol Buffers序列化机制后,管理员能够在不停止NameNode对外服务的前提下,通过主备NameNode之间的切换,依次对主备NameNode进行在线升级(不用考虑版本和协议兼容性等问题)