这篇文章我们探索Elasticsearch的写入流程,Elasticsearch的写入跟数据库的写入是完全不同的。
数据库中的写入只是单纯的写入行,Elasticsearch中的写入则是建立索引文件,可以理解成数据即索引。下面对比分析Elasticsearch与NoSQL数据库区别。
Elasticsearch并不支持事务。
实时性
Elasticsearch的主要应用场景就是实时,但Elasticsearch本身并非实时而是near-real-time(近实时)。Elasticsearch默认写入的数据会在1秒后,才可以被检索到。
NoSQL数据库则可以做到real-time(实时),一般情况下写入成功后是马上可以被查询到的。Elasticsearch中的Get请求也能保证是实时的,因为Get请求会直接读内存中尚未Flush到磁盘的TransLog。但是Get请求只支持通过doc_id进行查询,所以对于条件查询依然无法实现实时。
关于Get和Search请求:ElasticSearch原理(四):查询流程
可靠性
一种情况是我们从一个原始数据源,比如数据库,导入数据到Elasticsearch。这种情况对Elasticsearch的可靠性要求可能就没那么高,主要的功能还是搜索。因为原始数据存储是一个数据保障,即使Elasticsearch发生数据丢失,重新导入就行了。但有一种场景就是数据直接写Elasticsearch的,并且不允许丢失,这个时候对Elasticsearch的可靠性要求就很高。
关于Elasticsearch可靠性:ElasticSearch干货(五):Elasticsearch如何保证数据不丢失?
NoSQL数据库本身作为一款数据库,数据库对于数据可靠性一般都非常的高,但这也是数据库性能瓶颈的所在。如何使用Elasticsearch来中和两者,既保证数据可靠有保证性能就尤为重要。
众所周知,Elasticsearch是基于Lucene实现的,并且在Lucene的基础上做了功能上的修改和优化。下面我们开始探讨Lucene的写入和Elasticsearch的写入有什么区别。
Lucene的写入
Lucene的写入主要是index、update、和delete。因为segment是不支持修改的,所以update和delete其实都是写入。
Lucene中写操作主要是通过IndexWriter类实现,IndexWriter提供三个接口:
public long addDocument();
public long updateDocuments();
public long deleteDocuments();只要Doc通过IndesWriter写入后,后面就可以通过IndexSearcher搜索了。但也存在几点缺陷:
- Lucene并不是分布式
- Lucene只有在数据生成索引文件(segment)之后,才会被查询到,做不到实时
- 如何保证segment的可靠性
- segment不支持更新,一旦创建不能修改,所以不支持针对分档进行部分更新
Elasticsearch的写入
首先针对上述提到的Lucene的缺陷一一介绍Elasticsearch是怎么弥补优化的。
Elasticsearch为了实现分布式,引入了shard,将segment分布在不同的机器上。并且根据_routing来决定如何分配到指定的shard。
Elasticsearch中每个index由多个shard组成,默认是5个,每个shard分布在不同的机器上。shard分为主分片和副本分片,在文档写入时,会根据_routing来计算(OperationRouting类)得出文档要写入哪个分片。这里的写入请求只会写主分片,当主分片写入成功后,会同时把写入请求发送给所有的副本分片,当副本分片写入成功后,会传回返回信息给主分片,主分片得到所有副本分片的返回信息后,再返回给客户端。
在写入时,我们可以在Request自己指定_routing,也可以在Mapping指定文档中的Field值作为_routing。如果没有指定_routing,则会把_id作为_routing进行计算。由于写入时,具有相同_routing的文档一定会分配在同一个分片上,所以如果是自定义的_routing,在查询时,一定要指定_routing进行查询,否则是查询不到文档的。这并不是局限性,恰恰相反,指定_routing的查询,性能上会好很多,因为指定_routing意味着直接去存储数据的shard上搜索,而不会搜索所有shard。
从上述可以看出,Elasticsearch文档写入主要是写主分片和写副本分片。所以副本分片的个数就直接决定了写入的性能。合理配置副本数,在性能和安全之间取得平衡。
Lucene中索引数据只有在生成segment文件之后才会被查询到,Elasticsearch则是周期性(默认1秒)生成一个segment文件,生成的segment是允许被查询的,这样也就实现了near-real-time。参考:Elasticsearch原理(一):实时架构
在shard中,每次写入顺序是先写入Lucene,再写入TransLog。
当写入请求到shard后,首先是写Lucene,其实就是创建索引,索引创建好后并不是马上生成segment,这个时候索引数据还在缓存中,这里的缓存是lucene的缓存,并非Elasticsearch缓存。lucene缓存中的数据是不可被查询的。写入内存之后会写TransLog,TransLog可以理解为事务日志,类似数据库中的Binlog。这里跟数据库的区别是Elasticsearch是先写内存后写Log,数据库是先写Log再写内存。TransLog跟数据库一样是real-time的,所以Elasticsearch也可以做到real-time。那什么情况下是real-time呢?当Elasticsearch的查询是Get方式的时候,是优先查TransLog的,因为TransLog是real-time的,所以这个时候查到的数据就是实时写入的数据。参考:Elasticsearch原理(四):查询流程
Elasticsearch通过TransLog和副本来保障segment的安全性
前面提到了TransLog作为事务日志,记录了所有写入信息。因为Lucene缓存中的数据默认1秒之后才生成segment文件,即使是生成了segment文件,这个segment是写到页面缓存中的,并不是实时的写到磁盘,只有达到一定时间或者达到一定的量才会强制flush磁盘。如果这期间机器宕掉,内存中的数据就丢了。如果发生这种情况,内存中的数据是可以从TransLog中进行恢复的,TransLog默认是每5秒都会刷新一次磁盘。但这依然不能保证数据安全,因为仍然有可能最多丢失TransLog中5秒的数据。这里可以通过配置增加TransLog刷磁盘的频率来增加数据可靠性,最小可配置100ms,但不建议这么做,因为这会对性能有非常大的影响。一般情况下,Elasticsearch是通过副本机制来解决这一问题的。即使主分片所在节点宕机,丢失了5秒数据,依然是可以通过副本来进行恢复的。
Lucene不支持针对特定字段更新文档,而Elasticsearch为了能够实现针对文档中某个字段进行修改,在每次修改文档之前,都要先get要修改的文档的全部原始内容。
敲黑板划重点:update流程
- 接受update请求后,首先通过id在Segments或TransLog中取出要修改的文档内容,记录版本号为V1。
- 将版本号为V1的全部文档内容与要修改的文档内容(修改部分字段内容)合并,同时更新内存中的VersionMap。自此修改后的新文档已经生成,接下来就是index请求,把修改后的文档索引。
- 加锁
- 再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取。
- 检查版本是否冲突,如果V1==V2,则说明修改的最高版本号的文档,则进入下一步。如果V1 < V2,说明本次修改并非修改的最高版本号的文档,修改失败。返回第一步重新执行。
- 将版本号递增为V3(V2+1)。然后把文档写入到Lucene中,Lucene会先删除掉原来id的文档,然后把修改后的新文档增加进去。然后更新VersionMap中的版本号为V3。
- 释放锁,更新结束
Elasticsearch写入请求流程
Elasticsearch的写入请求主要包括:index、create、update、delete、bulk。bulk是实现对前四种的批量操作。在6.x版本以后实际上走的都是bulk接口了。
写入流程图
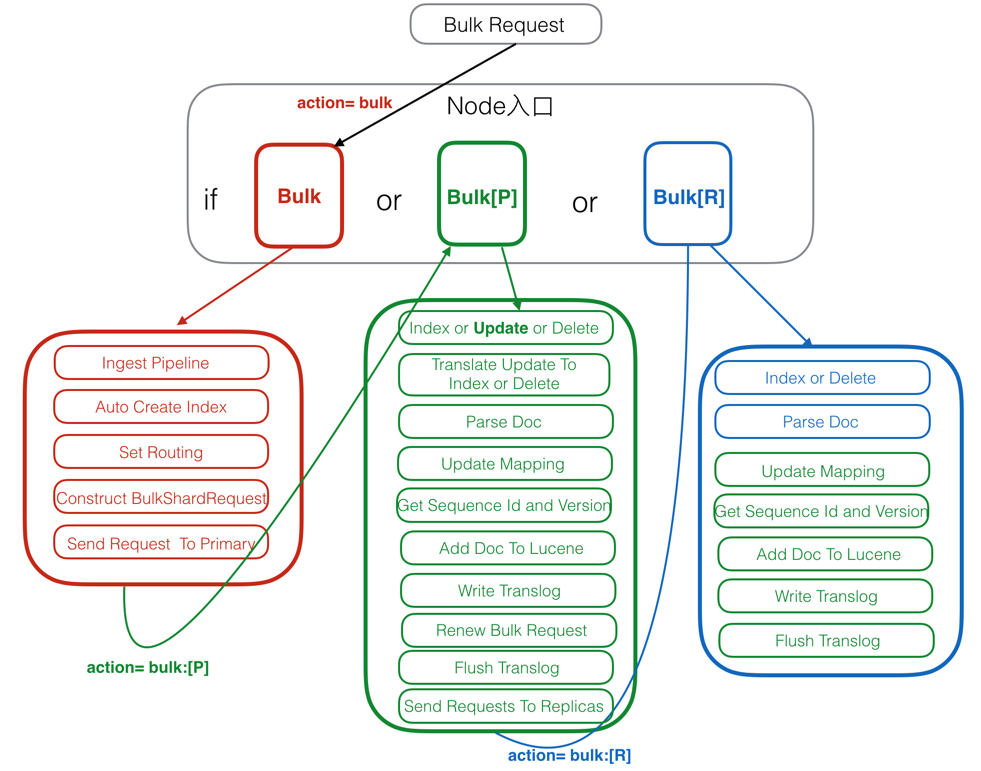
图片来自网络
- 红色:Client Node(客户端节点)。
- 绿色:Primary Node(主分片节点)。
- 蓝色:Replica Node(副本分片节点)。
注册Action
在Elasticsearch中,所有action的入口处理方法都是注册在ActionModule.java中,Bulk主要有两个入口,分别是Rest和Transport。
package org.elasticsearch.action;
...
registerHandler.accept(new RestBulkAction(settings, restController));
...
actions.register(BulkAction.INSTANCE, TransportBulkAction.class,
TransportShardBulkAction.class);
对于Rest请求,会在RestBulkAction中解析请求,并最终转成TransportAction处理。
protected void registerRequestHandlers(String actionName, TransportService transportService, Supplier<Request> request,Supplier<ReplicaRequest> replicaRequest, String executor) {
transportService.registerRequestHandler(actionName, request, ThreadPool.Names.SAME, new OperationTransportHandler());
transportService.registerRequestHandler(transportPrimaryAction, () -> new ConcreteShardRequest<>(request), executor,
new PrimaryOperationTransportHandler());
// we must never reject on because of thread pool capacity on replicas
transportService.registerRequestHandler(transportReplicaAction,
() -> new ConcreteReplicaRequest<>(replicaRequest),
executor, true, true,
new ReplicaOperationTransportHandler());
}这里对原始请求,Primary Node请求和Replica Node请求各自注册了一个handler处理入口。
由源码可知我们通过Rest请求Elasticsearch最终还是会转换成Transport方式,但官方并不建议直接采用Transport去与Elasticsearch交互,在新版本和未来版本中也是大力推荐使用Rest请求。
Client Node
客户端节点,用来接受请求和解析请求。
1. Ingest Pipeline
这里是对写入的原始文档进行解析处理,包括分词等。多是依赖于插件。
2. Auto Create Index
判断文档要写入的索引库是否存在,如果不存在需要创建index。这里的判断需要跟Master节点进行交互,为了避免,可以配置禁止自动创建索引。
3. Set Routing
配置路由,如果没有指定,则默认按照_id来配置路由。如果指定_routing,则按照指定的_routing配置。
4. Construct BulkShardRequest
对于某个shard上的请求会集中处理,构建BulkShardRequest。每个BulkShardRequest对应一个shard。
5. Send Request To Primary
将BulkShardRequest发送给主分片所在节点。
Primary Node
主分片所在节点,Primary 请求的入口是在PrimaryOperationTransportHandler的messageReceived。
protected class PrimaryOperationTransportHandler implements TransportRequestHandler<ConcreteShardRequest<Request>> {
public PrimaryOperationTransportHandler() {
}
@Override
public void messageReceived(ConcreteShardRequest<Request> request, TransportChannel channel, Task task) {
new AsyncPrimaryAction(request.request, request.targetAllocationID, request.primaryTerm, channel, (ReplicationTask) task).run();
}
}详细流程:
1. Index or Update or Delete
根据请求类型不同,指定不同的处理逻辑。其中,create/index是直接新增doc,delete是直接根据_id删除doc。
2. Translate Update To Index or Delete
这步数据update请求。将update请求转成index或delete请求。详情见上
3. Parse Doc
解析文档,生成_uid。
4. Update Mapping
Elasticsearch指定自动修改Mapping,就是在这步执行,如果发现doc中包含Mapping中没有的Field,并且配置允许自动修改Mapping,则自动修改。否则插入失败。
5. Get Sequence Id and Version
会从SequenceNumber Service获取一个sequenceID和Version。SequenceID在Shard级别每次递增1,SequenceID在写入Doc成功后,会用来初始化LocalCheckpoint。Version则是根据当前Doc的最大Version递增1。
6. Add Doc To Lucene
首先对_uid文档加锁,然后判断_uid的版本号是否匹配,如果不匹配,则抛出异常(VersionConflict),这个异常在第一步Index or Update or Delete会被捕获,并重新从这里执行。如果版本号匹配,则写入Lucene。如果是index或者create,则直接调用AddDocument。如果是update,则调用UpdateDocument。Lucene的update是先删后加。这里需要注意AddDocument最终也是调用的UpdateDocument中的add。
为了保证原子性,在delete前会加一个Refresh Lock,禁止被Refresh。只有等add完成之后才会释放锁。
7. Write Translog
写完Lucene的Segment后,接下来是写Translog,Translog中是key-value形式。key是_uid,value是文档内容。对于GetDocByID查询,直接从Translog中进行搜索。这里是real-time。
这一步的最后,会标记当前SequenceID已经成功执行,接着会更新当前Shard的LocalCheckPoint。
8. Renew Bulk Request
重新构造Bulk Request,主要是把update都转成了index或delete。这样副本分片节点久不需要处理update请求。
9. Flush Translog
Translog刷新到磁盘。详情见上
10. Send Requests To Replicas
将第8步中重新构造的Bulk Request发送给副本分片节点。并且会等待返回结果。
11. Receive Response From Replicas
接受全部副本分片节点的返回信息后,更新Primary Node的LocalCheckPoint。
Replica Node
副本分片所在节点。Replica 请求的入口是在ReplicaOperationTransportHandler的messageReceived。
public class ReplicaOperationTransportHandler implements TransportRequestHandler<ConcreteReplicaRequest<ReplicaRequest>> {
@Override
public void messageReceived(
final ConcreteReplicaRequest<ReplicaRequest> replicaRequest,
final TransportChannel channel,
final Task task)
throws Exception {
new AsyncReplicaAction(
replicaRequest.getRequest(),
replicaRequest.getTargetAllocationID(),
replicaRequest.getPrimaryTerm(),
replicaRequest.getGlobalCheckpoint(),
channel,
(ReplicationTask) task).run();
}
}详细流程:
1. Index or Delete
执行index或delete请求。注意在副本分片节点没有update请求。
2. Parse Doc
同上。
3. Update Mapping
同上。
4. Get Sequence Id and Version
同上。
5. Add Doc To Lucene
同上。注意这里主要AddDocument请求。不会有UpdateDocument。
6. Write Translog
同上。
7. Flush Translog
同上。
总结:
Elasticsearch的写入流程主要可分为几大特性。
- 可靠性,通过副本和TransLog来保障数据的可靠性。
- 一致性,Lucene中的Flush锁只保证Update接口里面Delete和Add中间不会Flush,但无法保证主分片与副本分片一致。因为如果add之后立即flush,这个时候segment是主分片可见的,但副本分片要落后于主分片。不过最终都会一致。
- 原子性,Add和Delete具有原子性。
- 实时性,Flush之后的segment对用户可见,最快可配置100ms,可实现near-real-time。特定的查询,直接查TransLog,可实现real-time。
- 性能,与实时性/可靠性互补。合理配置可提高系统整体性能。
更多:Elasticsearch深入理解专栏
——————————————————————————————————
作者:桃花惜春风
转载请标明出处,原文地址:
https://blog.csdn.net/xiaoyu_BD/article/details/81950081
您的支持是我坚持写作最大的动力,谢谢!