RocketMQ之基础知识讲解
一、RocketMQ知识介绍
1.1 前言
- RocketMQ是一个队列模型的消息中间件,具有高性能、高可用、高实时、分布式特点。
- 对列集合成为Topic, 如果Consumer做广播消费,则一个Consumer实例消费这个Topic对应的所有队列;如果做集群消费,则多个Consumer实例平均这个Topic对应的队列集合。
- 能够保证严格的消息顺序, 但是会失去FailOver特性,可以通过同步双写模式解决,但是服务切换任然会造成几分钟服务不可用。
- 可以提供多种消息拉取方式
- 高效的订阅者水平扩展能力
- 实时的消息订阅能力
- 亿级消息堆积能力,RocketMQ消息是持久化的,内部通过将几天前的消息删除,来满足亿级消息的处理能力。
- 较少的依赖
RocketMQ主要引用了JMS规范和Corbar Notification规范, 但是RocketMQ并不遵循任何规范,它参考了各种规范和同类的设计思想 。
RocketMq经历了三个主要版本的迭代,Metaq 1.x , MetaQ 2.x , RocketMQ 3.x , 在 Metaq 1.x 和 2.x版本中,用zookeeper作为注册中心,以满足高可用性能,但是nameSrv不仅可以满足高可用,相较于zookeeper更加的轻量级而且性能更好
1.2 专业术语
- Producer
消息生产者,负责产生消息,一般由业务系统负责产生消息 - Consumer
消息消费者,负责消费消息,一般是后台系统负责异步消费 - Push Consumer
Consumer的一种, 应用通常向Consumer注册一个Listener接口, 一旦收到消息, Consumer对象立即回掉Listener接口方法 。 - Pull Consumer
Cosumer的一种, 应用通常主动调用Consumer拉取消息方法从Broker拉取消息, 主动权由应用控制 - Producer Group
一类Producer的集合名称,这类Producer通常发送一类消息, 且发送逻辑一样 - Consumer Group
一类Consumer的集合名称, 这类Consumer通常消费一类消息,且消费逻辑一样 - Broker
消息中转角色, 负责存储消息,转发消息,一般也成为Server, 在JMS规范中成为Provider - 广播消费
一条消息被多个Consumer消费, 即使这些Consumer属于同一个Consumer Group , 消息也会被Consumer Group中的每一个Consumer都消费一次,广播消费中的Consumer Group 概念可以认为在消息划分方面没有意义。
在Corba Notification规范中,消息方式都属于广播消费。
在JMS规范中,相当于JMS publish/subscribe 模式 - 集群消费
一个Consumer Group中的Consumer实例平均分摊消费消息,其中Consumer Group有三个实例 ,那么每个实例只需要消费其中3条消息。
在JMS规范中,point-to-point与之类似,但是RocketMQ的集群消费能力 >= PTP模型,因为单个Consumer Group内的消费者类似于PTP,但是一个Topic/Queue可以被多个Consumer Group消费。 - 普通顺序消息
正常情况下,可以保证完全的顺序消费,但是一旦发生通信异常,Broker重启,由于队列总数发生变化,哈希 取模后定位的队列会变化,产生短暂的消息顺序不一致。如果能够忍受消息的短暂乱序可以使用普通顺序方式 - 严格顺序消息
无论正常情况还是异常情况,都可以保证完全的顺序消费,但是牺牲了分布式Failover特性,即只要Broker集群中有一台机器不可用,则整个集群不可用,服务可用性大大降低,如果服务器部署为同步双写模式,此缺陷可通过备机切换为主机避免,不过仍然存在几分钟的服务不可用(依赖同步双写,主备自动切换,主备切换功能目前还没有实现) - Message Queue
在RocketMQ中,所有的消息队列都是持久化,长度无限制的数据结构,所谓长度无限制是指队列中的每个存储单元都是定长的,访问其中的存储单元通过offset来访问,offset为java long类型,64位,理论上100年不会溢出,另外队列只保存最近几天的数据,之前的数据会按照过期时间来删除。
1.3 RocketMQ解决的问题
- Publish/Subscribe(发布订阅) 支持
消息中间件最基本的功能 Message Priority(消息优先级) 不支持
消息优先级指的是在同一个队列中每条消息有不同的优先级,按照消息优先级进行投递。RocketMQ所有消息都是持久化的,同一个队列消息如果按照优先级进行投递,需要进行排序,开销会很大。
替代方案, 设置多个队列, 分别表示不同优先级的队列
1) 达到优先级目的,但不是严格意义的优先级。用多个Topic分别表示不同的优先级, 需要对业务优先级的额精确的做出妥协 。
2) 严格意义的优先级,优先级用整数表示。这种方式不能通过不同的Topic来解决,如果通过MQ来解决这个问题,会对性能有很大影响, 需要确定是否确实需要这种严格的优先级, 如果通过多个Topic来表示优先级会有什么影响 。- Message Order(消息有序) 支持
消息有序指的是一类消息消费时,能按照发送的顺序来消费,比如果同一个订单的不同阶段可以保证完全有序 。
- Message Order(消息有序) 支持
Message Filter(消息过滤) 支持
1) Broker端消息过滤。按照Consumer端的要求进行过滤,减少了网络无用消息的过滤,但是增加了Broker端的负担,实现相对复杂 。
2) Consumer端消息过滤。可以由应用完全自定义实现,可能会造成很多无用的消息传输到Consumer端。Message Persistense(消息持久化) 支持
1) 持久化到数据库, 比如Mysql
2) 持久化到KV存储, 例如levelDB
3) 文件记录是持久化
4) 对内存数据库做一个持久化镜像,比如beanstalkd, Visinotify
1),2),3) 具有将内存队列Buffer进行扩展的能力 , 4) 是内存的镜像,作用是当Broker挂掉或重启后仍能将之前的数据回复出来。Message Reliability(消息可靠性) 支持
影响消息可靠性的几种情况,
1) RocketMQ可以保证消息不丢失或丢失少量数据。
Broker正常关闭, Broker异常crash, OS Crash, 机器断电 但是可以立即回复供电情况
2) 单点故障,一旦发生消息全部丢失。
机器无法开机, 磁盘设备损坏
解决方式: 通过异步复制, 可保证数据99%消息不丢失; 同步双写模式可以完全避免地点故障,但是会影响性能,适合对消息要求极高的场合 。Low Latency Messaging(低延迟消息) 支持
在消息不堆积情况下,消息到达Broker后,能立即到达Consumer。RockerMQ使用长轮询Pull方式,可以保证消息非常实时 。At least Once(消息必须投递一次) 支持
RocketMQ Consumer先Pull消息到本地,消费完后,才向客户端ack, 如果没有消费一定不会ackExactly Only Once 不支持
1) 发送消息阶段, 不允许发送重复消息
2) 接收消息阶段, 不允许消费重复消息
为了支持高性能, RocketMQ不支持这种特性,在分布式环境下,不可避免的会产生巨大的性能开销,可以在业务上进行去重,保证消费消息的幂等性。消息堆积的处理方式
Broker的buffer通常指Broker中一个内存Buffer的大小,这类Buffer通常大小有限。RocketMQ没有内存Buffer的概念, 数据是持久化到磁盘,定期进行数据清理。RocketMQ的内存Buffer抽象成一个无限的长度的队列,理论不管来多少数据都可以容纳的下,Broker会定期删除过期的数据,以保证长度无限。回溯消费 支持
回溯是指已经消费Consumer已经消费成功,由于业务需求需要重新消费,RocketMQ支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯也可以向后回溯。消息堆积
消息中间件主要功能是异步解耦,还有个重要功能是挡住前端的数据洪峰,保证后端系统的稳定性,这要求消息中间件具有一定的消息堆积能力。处理方式
1) 消息堆积在内存Buffer, 可以按照一定的策略丢弃消息,消息堆积后,性能不会下降太大,内存中存储数据的多少对影响对外提供访问的处理能里影响有限。
1.1) 拒绝新来的消息,
1.2) 按照特定策略丢弃已有信息
AnyOrder, FifoOrder, LifoOrder, PriorityOrder, DeadlineOrder
2) 消息堆积到持久化系统中,例如DB,KV系统,文件记录形式。堆积能里评估标准:
1) 消息的堆积能力
2) 消息堆积后,发消息的吞吐量是否收到影响
3) 消息堆积后,发消息的吞吐量大小,是否会受到堆积的影响
4) 消息堆积后,访问磁盘的消息时,吞吐量的大小- 定时消息
定时消息是指消息发到Broker后,不能被Consumer消费,要到特定的时间点或者等待特定的时间后才能被消费。
Broker支持定时消息,定时不支持任意时间精度,只支持特定的level,比如5s, 10s , 1mins
1.4 RocketMQ网络部署图
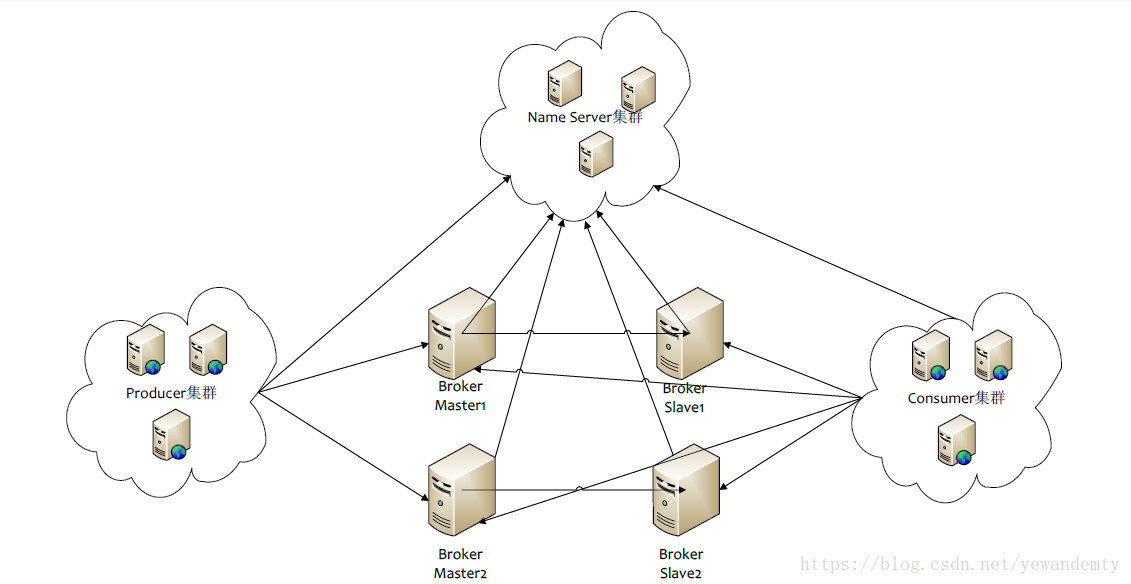
- Name Server是一个几乎无状态几点, 可集群部署,几点之间无任何消息同步 。
- Broker分为Master和Slave, 一个Master可以对应多个Slave,但是一个Slave只能对应一个Master, Master与Slave之间通过执行相同的Broker Name 不同的BrokerId来定义,brokerId = 0 表示Master节点, brokerId > 0 表示slave节点 , 每个broker与每个Name Server建立长连接,定时注册Topic信息到Name Server
- Producer 与Name Server 集群中的某个节点建立长连接(随机选择) , 定期从Namer Server获取Topic的路由信息, 并向提供topic服务的Master建立长连接,且定时向Master发送心跳,Producer是无状态的, 可集群部署
- Consumer与Name Server集群中的某个节点建立长连接(随机选择),定期从Name Server 获取Topic的路由信息, 并向提供服务的Master、slave建立长连接,且定时向Master、Slave发送心跳,Consumer既可以向Master订阅信息, 也可以向Slave订阅信息,具体的订阅规则由Broker的配置决定。
1.5 RocketMQ逻辑部署结构
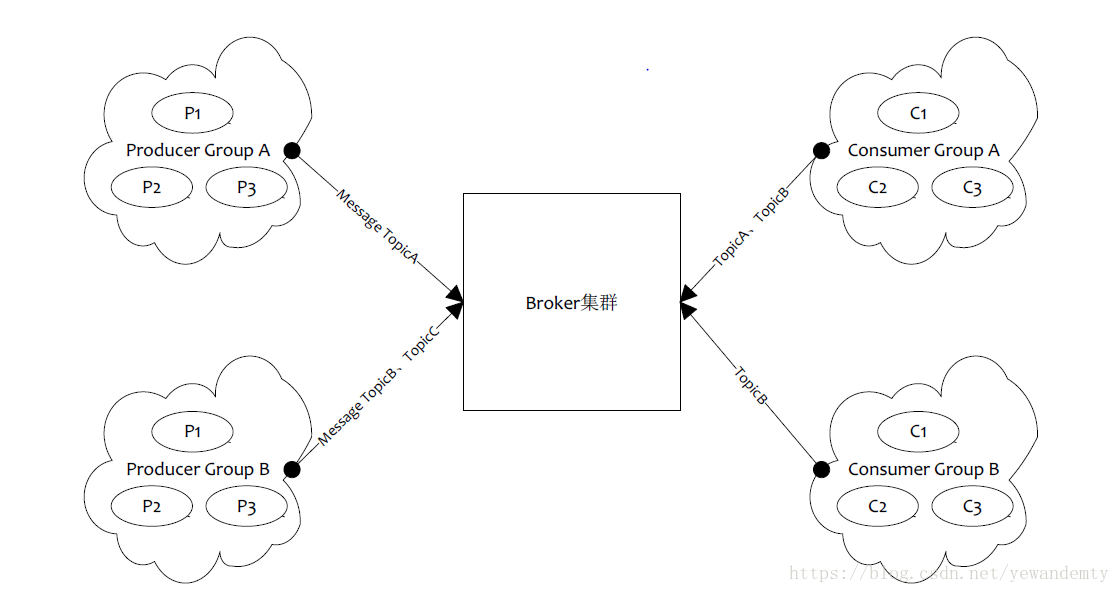
Producer Group
- 用来表示发送消息用 , 一个Producer Group 包含多个Producer实例
- Producer实例可以是多台机器,也可以是一台机器的多个线程,或者一个线程的多个Producer对像
- 标识一类Producer
- 发送分布式事务消息时,如果Producer中途意外宕机,Broker会主动回掉Producer Group 内的任意一台机器来确认事务状态
Consumer Group
- 用来表示一个消费者应用,一个Consumer Group 下包含多个Consumer实例
- Consumer实例,可以是多台机器、一台机器的多个线程、一个线程的多个Consumer对象
- 一个Consmer Group下多个Consumer以均摊的方式消费消息, 如果广播的消费方式,那么每个Consumer消费所有的消息
1.6 RocketMQ存储特点 mmap + write方式
- 使用mmap + write 方式
- 优点:即使频繁调用,小块文件传输效率也很高
- 缺点: 不能很好的利用DMA方式, 回避sendfile多消耗CPU,内存安全性控制复杂,需要比秒JVM Crash
使用sendfile方式
- 优点: 可以使用DMA方式,消耗CPU比较少, 大块文件效率高,无内存安全问题
- 缺点:小块文件传输效率较mmap方式低,只能是BIO方式传输,不能使用NIO。
数据存储结构
图片没有导入成功, 后期导入可以导入再添加该部分信息RocketMQ关键特性
- 所有数据单独存储到一个Commit Log的位置信息,完全顺序写,随机读
- 对最终用户展现的队列实际只存储消息在Commit Log的位置消息,并且串行方式刷盘
- 优点
- 队列轻量化,单个队列数量非常少。
- 对磁盘的访问串行化,避免磁盘竞争,不会因为队列增加导致IOWAIT增高
- 缺点
- 写虽然完全顺序写,但是读却变成了完全的随机读。
- 读一条信息, 会先读Consumer queue , 再读Commit Log , 增加了开销。
- 要保证Commit Log 与 Consume Queue完全的一致 , 增加了编程的复杂度
- 规避方式
- 随机读。尽可能让读命中PAGE CACHE,减少IO操作,多以内存越大越好。
- 如果系统中堆积的消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降。 不会急剧下降
- 访问PAGECACHE , 系统会提前预读出更多的数据,在下次读时, 可能命中内存 。
- 随机访问Commit Log 磁盘数据,设置系统IO调度算法位NOOP , 会在一定程度上将完全的随机读取变成顺序跳跃方式 , 这种跳跃方式较随机方式性能要快 。
- 由于Consume Queue存储数据量极少,而且是顺序读,在PAGE CACHE预读作用下,即使存在堆积,Consume Queue的读性能几乎和内存一致 。
- Commit Log中存储了所有的元信息, 包含消息体 ,所以只要Commit Log 的消息在,Consume Queue即使数据丢失,任然可以回复出来 。
- 数据刷盘
- 异步刷盘
- 同步刷盘
1.7RocketMQ客户端
客户端寻址方式
代码中指定
producer.setNamesrvAddr("192.168.0.1:9876;192.168.0.2:9876"); consumer.setNamesrvAddr("192.168.0.1:9876;192.168.0.2:9876");Java启动参数中指定Name Server地址
-Drocketmq.namesrv.addr=192.168.0.1:9876;192.168.0.2:9876环境变量指定Name Server地址
export NAMESRV_ADDR=192.168.0.1:9876;192.168.0.2:9876- HTTP静态服务器资源(推荐) 客户端部署简单, Name Server集群可热部署
客户端启动后, 会定时访问一个静态HTTP服务器,比如: http://jmenv.tbsite.net:8080/rocketmq/nsaddr
访问后,这个地址会返回 192.168.0.1:9876;192.168.0.2:9876
可以通过修改/etc/host 增加如下配置 10.232.191.1 jmenv.tbsite.net
客户端的公共配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| namesrvAddr | Name Server地址列表,多个Name Server用分号隔开 | |
| clientIP | 本机IP | 客户端本机IP, 多网卡的情况下,某些机器会发生无法识别客户端IP地址的情况,需要应用在代码强制指定 |
| instanceName | DEFAULT | 客户端实例名称,客户端创建多个Peoducer、Consumer实际是使用一个内部实例(这个实例包含网络连接、线程资源等) |
| clientCallbackExcutorThreads | 4 | 通信层异步回调线程数 |
| poolNameServerInteval | 30000 | 沦轮询Name Server 间隔时间,单位ms |
| heartbeatInteval | 30000 | 向Broker发送心跳间隔时间 ,单位ms |
| persistConsumerOffsetInteval | 5000 | 持久化Consumer消费进度间隔时间,得ms |
- Producer 配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| producerGroup | DEFAULT_PRODUCER | producer组名,多个Producer如果属于一个应用,发送同样的消息,则应该将他们归为一组 |
| createTopicKey | TBW102 | 在发送消息时自动创建服务器不存在的topic,需要指定Key |
| defaultTopicQueueNums | 4 | 默认创建的队列数 |
| sendMsgTimeOut | 10000 | 发送消息超时时间,单位毫秒(ms) |
| compressMsgBodyOverHowmuch | 4096 | 消息body超过多大开始压缩(Consumer收到消息会自动解压缩),单位字节 |
| retryAnotherBrokerWhenNotStoreOK | FALSE | 如果发送消息返回sendResult, 当是发送sendStatus != OK, 是否重试发送 |
| maxMessageSize | 131072 | 客户端限制的消息大小,超过报错,同时服务端也会限制 |
| transactionListener | 事务消息回查监听器, 如果发送事务消息,必须设置 | |
| checkThreadPoolMinSize | 1 | Broker回查Producer事务状态时,线程池最小数目 |
| checkThreadPoolMaxSize | 1 | Broker回查Producer事务状态时, 线程池最大数目 |
| checkRequestHoldMax | 2000 | Broker回查Producer事务状态时, Producer本地缓冲请求队列大小 |
- PushComsumer 配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| consumerGroup | DEFAULT_GROUP | Consumer组名,多个Consumer如果属于一个应用,订阅同样的消息,且消费逻辑一样,则应该将他们归为一组 |
| messageModel | CLUSTERING | 消息模型 支持 1. 集群消费 2. 广播消费 |
| consumerFromWhere | CONSUMER_FROM_LAST_OFFSET | Consumer启动后默认从什么位置开始消费 |
| allocateMessageQueueStrategy | AllocateMessageQueueAveragely | Rebalance算法实现策略 |
| subscription | {} | 订阅关系 |
| messageListener | 消息监听器 | |
| offsetStore | 消费进度存储 | |
| consumerThreadMin | 10 | 消费线程池最小数目 |
| consumerThreadMax | 20 | 消费线程池最大数目 |
| consumerConcurrentlyMaxSpan | 2000 | 单队列并行消费允许的最大跨度 |
| pullThresholdForQueue | 1000 | 拉消息本地队列缓存消息最大数 |
| pullInteval | 0 | 拉消息间隔,由于是长轮询,所以为0 ,但是应用为了控流,也可以设置大于0的值,单位毫秒(ms) |
| consumerMessageBatchMaxSize | 1 | 批量消费,一次消费多少条消息 |
| ppullBatchSize | 32 | 批量拉消息, 一次最多拉多少条 |
- PullConsumer配置
| 参数名 | 默认值 | 说明 |
|---|---|---|
| producerGroup | DEFAULT_PRODUCER | producer组名,多个Producer如果属于一个应用,发送同样的消息,则应该将他们归为一组 |
| brokerSuspendMaxTimeMills | 20000 | 长轮询,Consumer拉消息请求在Broker挂起最长时间,单位毫秒(ms) |
| cosumerTimeoutMillsWhenSuspend | 300000 | 长轮询, Consumer拉消息请求在Broker挂起超过指定时间, 客户端认为超时,单位毫秒(ms) |
| consumerPullTimeoutMills | 10000 | 非长轮询,拉消息超时时间,单位毫秒(ms) |
| messageModel | BROADCASTING | 消息模型,支持以下两种, 1. 集群消费 2.广播消费 |
| messageQueueListener | 监听队列变化 | |
| offsetStore | 消息进度存储 | |
| registerTopics | [] | 注册的Topic集合 |
| allocateMessageQueueStrangely | AllocateMessageQueueAveragely | Rebalance算法实现策略 |
Producer数据结构
Producer数据结构 Consumer数据结构
在Producer端,使用org.apache.rocketmq.common.message.Message这个数据结构,由于Broker会为Message增加数据结构,所以消息到达Consumer后, 会在Message基础上增加多个字段,Consumer看到的是org.apache.rocketmq.common.message.MessageExt 这个数据结构,MessageExt继承自Message 。

注: 后期有什么新的内容会不定期的更新