一.基础查询
/*关键字都以红色标出*/
/*sql关键字不区分大小写,数据库自动转为大写*/
1.1:查询某字段
- select /*需要查询的属性*/,/*需要查询的属性*/
- from /*需要查询的表*/;
结果:返回字段的列信息
举栗子:
SELECT id,name
FROM students;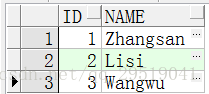
1.2:查询所有字段(关键记忆 *)
- select *
- from /*需要查询的表*/;
举栗子:
SELECT *
FROM students;注意 * 在执行阶段,oracle系统会将其解析成表中的实际字段之后,再去执行命令。效率低。开发中尽量不使用。
1.3:对查询结果进行计算(关键记忆 + - * / )
/*只有number类型的字段能做算数运算
注意对于+ 号在oracle里只是算数运算,不能做字符串拼接*/
举栗子:
日期类型也可以做算数运算, 只能做 + - 运算, 运算的单位是天
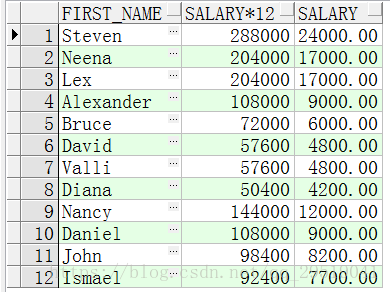
select first_name,salary*12,salary
from employees;
1.4:字段起别名(关键记忆 as )
/*关于别名加双引号和不加双引号 的区别 : 如果别名为英文字符, 加双引号严格区分大小写,不加双引号不区分大小写*/
Select first_name,last_name,salary*12 as "年薪"
From employees;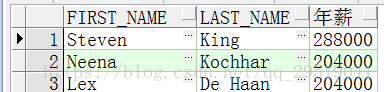
1.5:字符串拼接(关键记忆 || )
/*as后放双引号,其他位置字符用单引号*/
Select first_name||'_'||last_name as "姓名"
From employees;
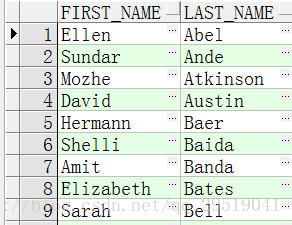
对比不拼接列结果:
Select first_name,last_name
From employees;
二.排序查询(关键记忆 order by,asc,desc )
/*asc[默认] 代表升序 | desc 代表降序
asc/desc 作用于前面的字段
在oracle系统中 null 值最大 .
*/
查询所有员工的信息, 按照工资的升序排列(从小到大)
Select *
From employees order by salary asc;
查询所有员工的信息, 按照工资的降序排列 | 如果工资相同则按照员工编号的升序排列
Select *
From employees order by salary desc ,employee_id asc;三.条件查询(关键记忆 where )
3.1 等值查询
= ,!=,(<>)
-- 查询员工工资为24000的人员信息
Select *
From employees where salary=24000;3.2 关系比较
> ,>=, <, <=
-- 查询员工工资大于10000的人员信息
Select *
From employees where salary > 10000;3.3 逻辑运算
and(并且) or(或者)
-- 查询工资 大于8000 小于12000的人员信息
Select *
From employees where salary>8000 and salary <12000;3.4 区间查询
between ... and
-- 查询工资 8000到12000之间的人员信息 | 包括8000和12000的人员
Select *
From employees where salary between 8000 and 12000; | 包含边界值3.5 枚举查询
in (条件1,条件2...)
-- 查询工资为 2100、8000、12000、24000的人员信息
Select *
From employees where salary in (2100,8000,12000,24000);3.6 对null值的处理
is null is / not null (不能使用“=null”这种语法 )
-- 查询没有提成人员的信息
Select
From employees where commission_pct is null;3.7 模糊查询
like 条件 | _ -匹配一个字符 % - 匹配 0-n个字符
-- 查询first_name由4个字符组成的人员信息
Select *
From employees where first_name like ‘____’;
-- 查询first_name以大写字母D开头的人员信息
Select *
From employees where first_name like ‘D%’;
-- 查询first_name以大写S开头的 由5个字符组成的人员信息
Select *
From employees where first_name like ‘S____’;
-- 查询first_name 不包含字母 a的人员信息
Select *
From employees where first_name not like ‘%a%’;补充:
查看系统时间(Date类型数据)
select sysdate from dual;
Select systimestamp from dual; // 时间比较精确, 精确到秒小数后6位dual(称为 哑表或虚表 )表是oracle数据库系统提供的,旨在维护sql语句的完整性 . 这个表只有一行一列.
四.单行函数
(单行函数作用于表中的每一行数据产生一个结果)
4.1:to_char : 日期转字符串
-- 查询今天是星期几
Select to_char(sysdate,’day’)
From dual;
-- 查询当前系统时间 展示 年/月/日 时:分:秒 星期
Select to_char(sysdate,’yyyy/MM/dd HH:MI:SS day’)
From dual;4.2:to_date : 字符串转日期 | 是将一个字符串转换成oracle系统默认的日期格式展示
Select to_date(‘2018-08-24’,’yyyy-mm-dd’) // 把字符串转换成日期格式
From dual;4.3:round(值, n) //n代表指定值小数位精确位数
4.4:mod(值1,值2) // 返回值1模值2的结果
4.5:nvl(值1,值2) //如果值1为null,返回值2 , 如果值1不为null返回值1
4.6:查询一个指定值的字符长度 :
length(字符串) | 返回字符串的长度 单位是字符
lengthb(字符串) | 返回字符串的长度 单位是字节
补充:oracle系统,一个中文默认占3个字节 .
五.组函数/聚合函数
(作用于每一组数据产生一个结果)
5.1:sum(字段) : 求一组数据的和
5.2:avg(字段) : 求一组数据的平均值
5.3:max(字段) : 求最大值
5.4:min(字段) : 求最小值
PS: sum()与avg() 只能作用于数值类型的字段
max()与min() 可以作用于所有类型的字段 | 没有什么实质的意义
5.5:count(*) : 统计查询
举栗子
-- 查询员工表一共多少条数据
Select count(*) from employees;
Select count(1) from employees;结果

举栗子
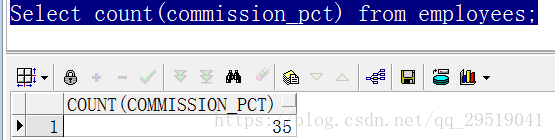
-- 统计查询所有有提成人员的数量
Select count(commission_pct) from employees; 结果
六.分组查询(关键记忆 group by)
意义:把数据以一列中出现的不同类数据分组,同类的分为一组
例如在部门id中,部门id相同的分为一组。
注意!
- 只有出现在group by子句中的字段,才能单独出现在select子句中
- 如果一个字段没有出现在group by子句,但是还想出现在select子句中,那么必须配合组函数使用 | 只是语法上的,没有实战价值
- 如果group by子句中的字段使用了某个单行函数,那么 select子句中对应也必须使用相同的单行函数
栗一:
-- 查询员工表各个部门的平均工资 、以及部门编号
分析:
① 确定分组条件 : 部门 department_id
② 对没组数据按需求 ,求结果 : avg(salary)
Select department_id,avg(salary)
From employees group by department_id;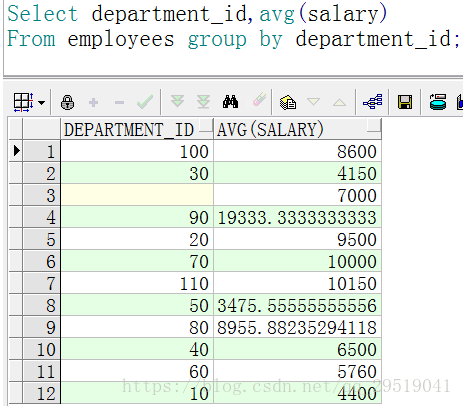
栗二:
-- 查询统计各个部门各个职位员工的人数
分析:
Select department_id,job_id,count(*)
from employees
Group by department_id,job_id;