12.1正则表达式及其相关类
12.1.1 正则表达式简介
用某种模式去匹配指定字符串的一种表示方式。
普通字符:如字母、数字、汉字等。
元字符:可以匹配某些字符形式的具有特殊含义的字符,其作用类似于DOS命令使用的通配符。
1.正则表达式基本书写符号
| 符号 |
含义 |
示例 |
解释 |
匹配输入 |
| \ |
转义符 |
\* |
符号“*” |
* |
| [ ] |
可接收的字符列表 |
[efgh] |
e、f、g、h中的任意1个字符 |
e、f、g、h |
| [^ ] |
不接收的字符列表 |
[^abc] |
除a、b、c之外的任意1个字符,包括汉字、数字和特殊符号 |
m、q、5、* |
| | |
匹配“|”之前或之后的表达式 |
ab|cd |
ab或者cd |
ab、cd |
| ( ) |
将子表达式分组 |
(abc) |
将字符串abc作为一组 |
abc |
| - |
连字符 |
[A-Z] |
任意单个大写英文字母 |
大写字母 |
2.正则表达式限定符
限定符将可选数量的数据添加到正则表达式,下表为常用限定符:
| 符号 |
含义 |
示例 |
解释 |
匹配输入 |
不匹配输入 |
| * |
指定字符重复0次或n次 |
(abc)* |
仅包含任意个abc的字符串 |
abc、abcabcabc |
a、abca |
| + |
指定字符重复1次或n次 |
m+(abc)* |
以至少1个m开头,后接任意个abc的字符串 |
m、mabc、mabcabc |
ma、abc |
| ? |
指定字符重复0次或1次 |
m+abc? |
以至少1个m开头,后接ab或abc的字符串 |
mab、mabc、mmmab、mmabc |
ab、abc、mabcc |
| {n} |
只能输入n个字符 |
[abcd]{3} |
由abcd中字母组成的任意长度为3的字符串 |
abc、dbc、adc |
a、aa、dcbd |
| 符号 |
含义 |
示例 |
解释 |
匹配输入 |
不匹配输入 |
| {n,} |
指定至少 n 个匹配 |
[abcd]{3,} |
由abcd中字母组成的任意长度不小于3的字符串 |
aab、dbc、aaabdc |
a、cd、bb |
| {n,m} |
指定至少 n 个但不多于 m 个匹配 |
[abcd]{3,5} |
由abcd中字母组成的任意长度不小于3,不大于5的字符串 |
abc、abcd、aaaaa、bcdab |
ab、ababab、a |
| ^ |
指定起始字符 |
^[0-9]+[a-z]* |
以至少1个数字开头,后接任意个小写字母的字符串 |
123、6aa、555edf |
abc、aaa、a33 |
| $ |
指定结束字符 |
^[0-9]\-[a-z]+$ |
以1个数字开头后接连字符“–”,并以至少1个小写字母结尾的字符串 |
2-a、3-ddd、5-efg |
33a、8-、7-Ab |
3.匹配字符集
(1)匹配字符集是预定义的用于正则表达式中的符号集。
(2)如果字符串与字符集中的任何一个字符相匹配,它就会找到这个匹配项。
正则表达式中的部分匹配字符集
| 符号 |
含义 |
示例 |
解释 |
匹配输入 |
不匹配输入 |
| . |
匹配除\n 以外的任何字符 |
a..b |
以a开头,b结尾,中间包括2个任意字符的长度为4的字符串 |
aaab、aefb、a35b、a#*b |
ab、aaaa、a347b |
| \d |
匹配单个数字字符,相当于[0-9] |
\d{3}(\d)? |
包含3个或4个数字的字符串 |
123、9876 |
12、01023 |
| \D |
匹配单个非数字字符,相当于[^0-9] |
\D(\d)* |
以单个非数字字符开头,后接任意个数字字符串 |
a、A342 |
aa、AA78、1234 |
| \w |
匹配单个数字、大小写字母和汉字字符 |
\d{3}\w{4} |
以3个数字字符开头的长度为7的字符串 |
234abcd、12345Pe |
58a、Ra46 |
| \W |
匹配单个除汉字、字母、数字以外的其他字符 |
\W+\d{2} |
以至少1个非数字、字母和汉字的字符开头,2个数字字符结尾的字符串 |
#29、#?@10 |
23、#?@100 |
4.分组构造
常用分组构造形式
| 分组构造 |
说明 |
| ( ) |
非命名捕获。捕获匹配的子字符串(或非捕获组)。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其它捕获结果则根据左括号的顺序从1开始自动编号。 |
| (?<name>) |
命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。也可以用单引号替代尖括号,例如(?'name') |
5. 正则表达式举例
(1)至少1个字符:.{1,}
(2)3个“.”句点符号:\.{3}
(3)括号括起来的2~3个数字构成的字符串:\([0-9]{2,3}\)其中的反斜杠“\”表示转义。
(4)必须包含“ab”的字符串:.{0,}ab.{0,}
(5)以字母开头,允许包含字母、数字及下划线,长度为5~16:[a-zA-Z][a-zA-Z0-9_ ]{5,16}
(6)国内电话号码:( \d{3}-| \d{4}-)?( \d{8}| \d{7})
(7)至少3个汉字:[\u4e00-\u9fa5]{3,}
1.Regex类
IsMatch方法:正则表达式在输入字符串中是否找到匹配项。
Match方法:搜索下一个匹配项。
Matchs方法:搜索所有匹配项。
2.Match类
Match类表示正则表达式下一个匹配的结果,得到的结果是只读的。例如:
Regexr = new Regex("abc");
Match m = r.Match("123abc456");
if (m.Success)
{
Console.WriteLine("找到匹配位置:"+m.Index);
Console.WriteLine("找到匹配结果:"+m.Value);
}
运行结果:
找到匹配位置:3
找到匹配结果:abc
3.MatchCollection类
MatchCollection类表示成功的非重叠匹配的集合,得到的集合是只读的。例如:
Regexr = new Regex("abc");
MatchCollectionmc =r.Matches("123abc4abcd");
intcount =mc.Count;
String[] results = new String[count];
int[]matchPosition= newint[count];
for (inti = 0; i < count; i++)
{
results[i] = mc[i].Value;
matchPosition[i]= mc[i].Index;
Console.WriteLine("第{0}个匹配结果:{1},位置:{2}",i+1,
results[i], matchPosition[i]);
}
运行结果:
第1个匹配结果:abc,位置:3
第2个匹配结果:abc,位置:7
4. Group类
Group类表示单个捕获组的结果。当与正则表达式匹配的
字符串有多组时,可以使用该类得到某一组的结果。
【例12-1】编写一个Windows应用程序,输入某个正则表达式和一个字符串,然后验证该字符串中是否包含与正则表达式匹配的内容。

【例12-2】编写一个Windows应用程序,利用正则表达式验证用户注册信息是否符合要求。

12.2.1 WebBrower控件
通过此控件可以在 Windows 窗体客户端应用程序中显示网页,复制应用程序中的Internet Explorer Web浏览功能,禁用默认的Internet Explorer功能,并将该控件用作简单的HTML文档查看器
【例12-3】使用WebBrowser控件创建一个简易浏览器。

在System.Net命名空间下的WebClient类提供向URI标识的任何本地、Intranet或Internet资源发送数据以及从这些资源接收数据的公共方法。
通过此类从Web站点下载文件两种方式:
1.直接保存为本地文件
2.通过流进行读取,具体采用哪种方式要视情况而定。
该方法有两个参数:URI和本地保存路径。如:
WebClientmyWebClient = newWebClient();
myWebClient.DownloadFile("http://military.china.com/zh_cn/","C:\\test.htm");
此方法返回一个Stream引用,然后可以从数据流中读取数据,如:
using System.Net;
using System.IO;
……
WebClientwebClient = newWebClient();
Stream myStream=webClient.OpenRead("http://news.sohu.com");
StreamReadersr = newStreamReader(myStream);
string httpSource=sr.ReadToEnd();
直接读取包含网页源代码的字符串内容。例如:
using System.Net;
……
WebClientclient = new WebClient();
stringreply = client.DownloadString("Http://www.163.com");
Console.WriteLine(reply);
【例12-4】设计一个简单的搜索程序,能读取指定网址的html源文件,并能用正则表达式搜索包含的超链接与图片。
设计界面如图:
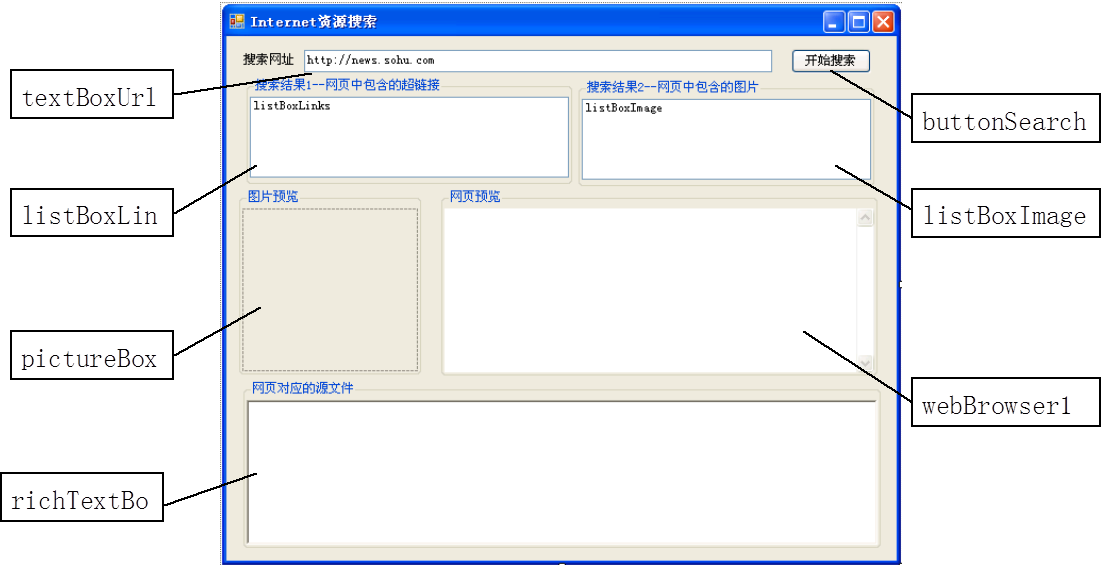
例12-4运行效果:

附:正则表达式



正则表达式:(表示字符串集(也表示为L(R))的字符序列。当用于约束词法空间时,正则表达式断言只有字符串集中的字符串对于该类型的值是有效文本。
正则表达式由零个或多个用“或”(|)字符分隔的分支组成。
)
转义字符:
| 一般字符 |
除 . $ ^ { [ ( | ) * + ? \ 外,其他字符与自身匹配。 |
| \a |
与响铃(警报)\u0007 匹配。 |
| \b |
如果在 [] 字符类中,则与退格符 \u0008 匹配;如果不是这种情况,请参见本表后面的“注意”部分。 |
| \t |
与 Tab 符 \u0009 匹配。 |
| \r |
与回车符 \u000D 匹配。 |
| \v |
与垂直 Tab 符 \u000B 匹配。 |
| \f |
与换页符 \u000C 匹配。 |
| \n |
与换行符 \u000A 匹配。 |
| \e |
与 Esc 符 \u001B 匹配。 |
用一个字符串来描述一个特征,来验证另一个字符串是否符合这个特征。
\d 用来匹配0-9任意一个的数字
\w 用来匹配任一个大小写字母
\s 用来匹配空白字符
\r\n换行回车
\t 制表符
\. 小数点
\$ 美元符号
\\ 表示\
. 表示任意字符
\d\d匹配 abcd1234efg成功
a.\d 匹配aaa1000成功
[ab5]匹配其中的一个
[^ab5]不能匹配其中的任意一个
[f-z0-3]
[a-f]{2}重复2次[a-f][a-f]
[a-f]{2,4}至少重复2次 最多4次
b[ab]?
?0或者1次
+ 至少出现一次{1,}
* 不出现或者出现任意次{0,}
([ab][cd]){2}
he | ta
| * |
匹配前导元素零次或零次以上。该限定符等效于{0,}。* 是贪婪限定符,对应的非贪婪限定符是 *?。 例如,正则表达式 \b91*9*\b 尝试匹配字边界后面的数字 9。9 后面可以是数字1 的零个或零个以上的实例,而数字 1 后面又可跟数字 9 的零个或零个以上的实例。下面的示例演示了此正则表达式。在输入字符串内的 9 个数字中,有 5 个与模式匹配,有 4 个(95、929、9129 和9919)不匹配。 |
| + |
匹配前导元素一次或多次。它等效于{1,}。+ 是贪婪限定符,对应的非贪婪限定符是 +?。 例如,正则表达式 \ba(n)+\w*?\b 尝试匹配以字母 a 开头且后跟字母 n 的一个或多个实例的完整单词。下面的示例演示了此正则表达式。该正则表达式匹配单词 an、annual、announcement 和antique,但不匹配 autumn 和all。 |
| ? |
匹配前导元素零次或一次。它等效于{0,1}。? 是贪婪限定符,对应的非贪婪限定符是 ??。 例如,正则表达式 \ban?\b 尝试匹配以字母 a 开头且后跟字母 n 的零个或一个实例的完整单词。换言之,它尝试匹配单词 a 和 an。下面的示例演示了此正则表达式。 |
| {n,} |
匹配前导元素至少 n 次。{n,} 是贪婪限定符,对应的非贪婪限定符为 {n}?。 例如,正则表达式\b\d{2,}\b\D+ 尝试匹配如下字符串:先是一个字边界,然后是至少 2 个数字,然后再跟一个字边界和一个非数字字符 |
| {n,m} |
匹配前导元素至少 n 次,但不超过 m 次。{n,m} 是贪婪限定符,对应的非贪婪限定符为 {n,m}?。 例如,正则表达式 (00\s){2,4} 尝试匹配两个相连的零和一个紧随的空格,且匹配 2 到 4 个实例。 |
| 说明 |
|
| [字符分组] |
(正字符分组。) 匹配指定字符分组内的任何字符。 字符分组由串连的一个或多个原义字符、转义符、字符范围或字符类组成。 例如,若要指定所有元音字母,使用[aeiou]. 若要指定所有标点符号和十进制数字符,使用代码 [\p{P}\d]。 |
| [^字符分组] |
(负字符分组。) 匹配不在指定字符分组内的任何字符。 字符分组由串连的一个或多个原义字符、转义符、字符范围或字符类组成。前导符 (^) 是强制的,指示字符分组为负字符分组,而不是正字符分组。 例如,若要指定除元音字母以外的所有字符,使用[^aeiou]. 若要指定除标点符号和十进制数字符以外的所有字符,使用 [^\p{P}\d]。 |
| [第一个字符-最后一个字符] |
(字符范围。) 匹配字符范围中的任何字符。 字符范围是一系列连续的字符,定义的方法是:指定系列中的第一个字符,连字符 (-),然后指定系列中的最后一个字符。如果两个字符具有相邻的 Unicode 码位,则这两个字符是连续的。可以串连两个或更多字符范围。 例如,若要指定从“0”至“9”的十进制数范围、从“a”至“f”的小写字母范围,以及从“A”至“F”的大写字母范围,使用[0-9a-fA-F]。 |
| . |
(句点字符。) 匹配除\n 以外的任何字符。如果已用 Singleline 选项做过修改,则句点字符可与任何字符匹配。有关更多信息,请参见正则表达式选项。 请注意,正字符分组或负字符分组中的句点字符(方括号内的句点)将被视为原义句点字符,而非字符类。 |
| \p{名称} |
匹配通过名称(例如 Ll、Nd、Z、IsGreek 和 IsBoxDrawing)指定的 Unicode 通用类别或命名块中的任何字符。 |
| \P{名称} |
匹配不在名称中指定的 Unicode 通用类别或命名块中的任何字符。 |
| \w |
与任何单词字符匹配。等效于 Unicode 通用类别[\p{Ll}\p{Lu}\p{Lt}\p{Lo}\p{Nd}\p{Pc}\p{Lm}]。如果通过 ECMAScript 选项指定了符合 ECMAScript 的行为,则\w 等效于 [a-zA-Z_0-9]。 |
| \W |
与任何非单词字符匹配。等效于 Unicode 通用类别[^\p{Ll}\p{Lu}\p{Lt}\p{Lo}\p{Nd}\p{Pc}\p{Lm}]。如果通过ECMAScript 选项指定了符合 ECMAScript 的行为,则 \W 等效于 [^a-zA-Z_0-9]。 |
| \s |
与任何空白字符匹配。等效于转义符和 Unicode 通用类别[\f\n\r\t\v\x85\p{Z}]。如果通过 ECMAScript 选项指定了符合 ECMAScript 的行为,则\s 等效于 [ \f\n\r\t\v]。 |
| \S |
与任何非空白字符匹配。等效于转义符和 Unicode 通用类别[^\f\n\r\t\v\x85\p{Z}]。如果通过 ECMAScript 选项指定了符合 ECMAScript 的行为,则\S 等效于 [^ \f\n\r\t\v]。 |
| \d |
与任何十进制数字匹配。对于 Unicode 类别的 ECMAScript 行为,等效于\p{Nd},对于非 Unicode 类别的 ECMAScript 行为,等效于 [0-9]。 |
| \D |
与任何非数字字符匹配。对于 Unicode 类别的 ECMAScript 行为,等效于\P{Nd},对于非 Unicode 类别的 ECMAScript 行为,等效于 [^0-9] 。 |
例子①
using System.Text.RegularExpressions; protected void btnSubmit_Click(object sender, EventArgs e) { Regex re = new Regex(@"\d{2}a"); Math m = re.Match(textbox1.Text); if(m.Success) { MessageBox.Show(m1.Index.ToString()); }
例子②电子邮件
protected void btn_Click(object sender, EventArgs e)
{
//验证电子邮箱
Regex a = new Regex(@"\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*");
Match b = a.math(textbox1.Text);
if (b.Success)
{
MessageBox.Show("电子邮箱格式正确!");
}
}匹配多个字符:
protected void btnSubmit_Click(object sender, EventArgs e)
{
Regex re = new Regex(@"\d{2}a");
MathCollextion m = re.Matches(textbox1.Text);
// Math m = re.Match(textbox1.Text);
foreach(Math m1 in m)
{ MessageBox.Show(m1.Index.ToString());
正则表达式中的分组问题:
protected void btn_Click(object sender, EventArgs e)
{
Regex re = new Regex(@"(?<user>[^@]@(?<host>.+\..+)");string s= "jioaaa.com";
Match m = re.math(s);
if (m.Success)
{string zhuji =m.Groups["host"].Value;
MessageBox.Show(zhuji);
}
}
| 分组构造 |
说明 |
| (子表达式) |
捕获匹配的子表达式(或非捕获组;有关更多信息,请参见正则表达式选项中的ExplicitCapture 选项)。使用 () 的捕获基于左括号按顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本。 |
| (?<name>子表达式) |
将匹配的子表达式捕获到一个组名称或编号名称中。用于 name 的字符串不得包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如(?'name')。 |
| (?<name1-name2>子表达式) |
(平衡组定义。) 删除先前定义的 name2 组的定义,并在 name1 组中存储先前定义的 name2 组和当前组之间的间隔。如果未定义 name2 组,则匹配将回溯。由于删除 name2 的最后一个定义会显示 name2 的先前定义,因此该构造允许将 name2 组的捕获堆栈用作计数器,用于跟踪嵌套构造(如括号)。在此构造中,name1 是可选的。可以使用单引号替代尖括号,例如(?'name1-name2')。 有关更多信息,请参见本主题中的示例。 |
| (?:子表达式) |
(非捕获组。) 不捕获由子表达式匹配的子字符串。 |
| (?imnsx-imnsx:子表达式) |
应用或禁用子表达式中指定的选项。例如,(?i-s: ) 将打开不区分大小写并禁用单行模式。有关更多信息,请参见正则表达式选项。 |
| (?=子表达式) |
(零宽度正预测先行断言。) 仅当子表达式在此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。 |
| (?!子表达式) |
(零宽度负预测先行断言。) 仅当子表达式不在此位置的右侧匹配时才继续匹配。例如,\b(?!un)\w+\b 与不以un 开头的单词匹配。 |
| (?<=子表达式) |
(零宽度正回顾后发断言。) 仅当子表达式在此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。 |
| (?<!子表达式) |
(零宽度负回顾后发断言。) 仅当子表达式不在此位置的左侧匹配时才继续匹配。 |
| (?>子表达式) |
(非回溯子表达式(也称为“贪婪”子表达式)。) 该子表达式仅完全匹配一次,然后就不会逐段参与回溯了。(也就是说,该子表达式仅与可由该子表达式单独匹配的字符串匹配。) 默认情况下,如果匹配未成功,回溯会搜索其他可能的匹配。如果已知无法成功回溯,可以使用非回溯子表达式避免不必要的搜索,从而提高性能。 |
| 分组构造 |
说明 |
| (子表达式) |
捕获匹配的子表达式(或非捕获组;有关更多信息,请参见正则表达式选项中的 ExplicitCapture 选项)。使用 () 的捕获基于左括号按顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本。 |
| (?<name>子表达式) |
将匹配的子表达式捕获到一个组名称或编号名称中。用于 name 的字符串不得包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如 (?'name')。 |
| (?<name1-name2>子表达式) |
(平衡组定义。) 删除先前定义的 name2 组的定义,并在 name1 组中存储先前定义的 name2 组和当前组之间的间隔。如果未定义 name2 组,则匹配将回溯。由于删除 name2 的最后一个定义会显示 name2 的先前定义,因此该构造允许将 name2 组的捕获堆栈用作计数器,用于跟踪嵌套构造(如括号)。在此构造中,name1 是可选的。可以使用单引号替代尖括号,例如 (?'name1-name2')。 有关更多信息,请参见本主题中的示例。 |
| (?:子表达式) |
(非捕获组。) 不捕获由子表达式匹配的子字符串。 |
| (?imnsx-imnsx:子表达式) |
应用或禁用子表达式中指定的选项。例如,(?i-s: ) 将打开不区分大小写并禁用单行模式。有关更多信息,请参见正则表达式选项。 |
| (?=子表达式) |
(零宽度正预测先行断言。) 仅当子表达式在此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。 |
| (?!子表达式) |
(零宽度负预测先行断言。) 仅当子表达式不在此位置的右侧匹配时才继续匹配。例如,\b(?!un)\w+\b 与不以 un 开头的单词匹配。 |
| (?<=子表达式) |
(零宽度正回顾后发断言。) 仅当子表达式在此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。 |
| (?<!子表达式) |
(零宽度负回顾后发断言。) 仅当子表达式不在此位置的左侧匹配时才继续匹配。 |
| (?>子表达式) |
(非回溯子表达式(也称为“贪婪”子表达式)。) 该子表达式仅完全匹配一次,然后就不会逐段参与回溯了。(也就是说,该子表达式仅与可由该子表达式单独匹配的字符串匹配。) 默认情况下,如果匹配未成功,回溯会搜索其他可能的匹配。如果已知无法成功回溯,可以使用非回溯子表达式避免不必要的搜索,从而提高性能。 |