版权声明:本文为博主原创文章,未经博主允许不得转载。个人博客:www.saoguang.top https://blog.csdn.net/u011580175/article/details/82292420
创建项目
- 命令行切换到项目创建目录
- 运行命令
scrapy startproject mysite - 这样就创建好了一个scrapy项目
目录结构 :
- mysite
- pycache
- spiders(编写爬虫的地方)
- init.py
- init.py
- items.py(定义爬取的数据的数据结构)
- middlewares.py(request,spiders的中间件)
- pipelines.py(数据清洗)
- settings.py(项目配置)
- scrapy.cfg(scrapy配置文件)
简单实践的内容
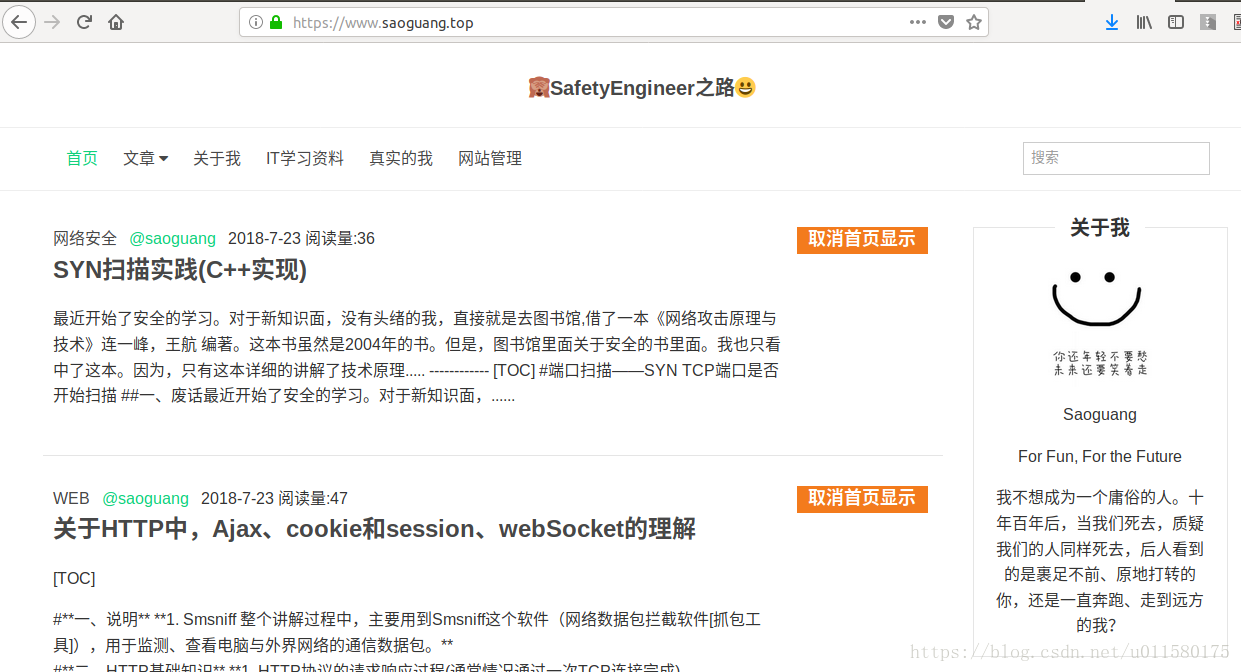
- 抓取saoguang.top,也就是我的博客的首页的文章列表的内容。包括:
- 文章分类
- 作者
- 发布时间
- 阅读量
- 文章标题
- 文章部分内容
编写简单爬虫
新建spider
在项目下的spiders文件夹下,执行命令
scrapy genspider mysite_spider saoguang.top定义数据项结构
按照上面要爬取的数据,编辑items.py文件中的class MysiteItem
class MysiteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#文章分类
article_type = scrapy.Field()
#作者
author = scrapy.Field()
#发布时间
pub_time = scrapy.Field()
#阅读量
read_quantity = scrapy.Field()
#文章标题
article_title = scrapy.Field()
#文章部分内容
article_content_part = scrapy.Field()- 编写spider
编辑spiders/mysite_spider.py文件
# -*- coding: utf-8 -*-
import scrapy
class MysiteSpiderSpider(scrapy.Spider):
#爬虫名
name = 'mysite_spider'
#允许的域名,如果不是在下列的域名中,就不会进行抓取
allowed_domains = ['saoguang.top']
#入口url,此入口url会被scrapy引擎,传递给调度器,然后,调度器给downloader进行网页请求。
start_urls = ['https://saoguang.top/']
#解析函数,对下载到的数据进行数据解析
def parse(self, response):
#打印以下返回的数据
print(response.text)
- 这里我们请求了saoguang.top,
parse也就是解析的意思,也就是返回的数据,你需要在这个方法中进行解析,提取。我们这里parse就是简单的打印响应的text内容到控制台。 - 运行一下这个spider看看是否返回了网页数据。
- 命令行运行:
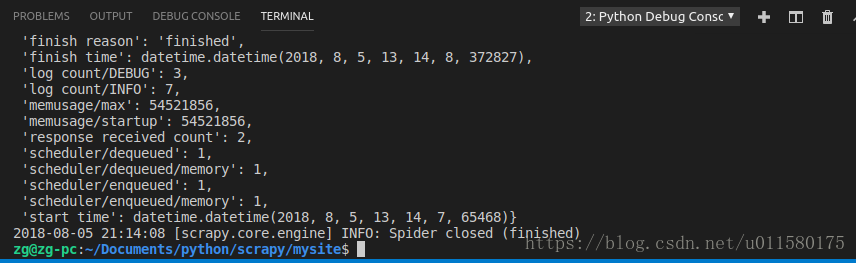
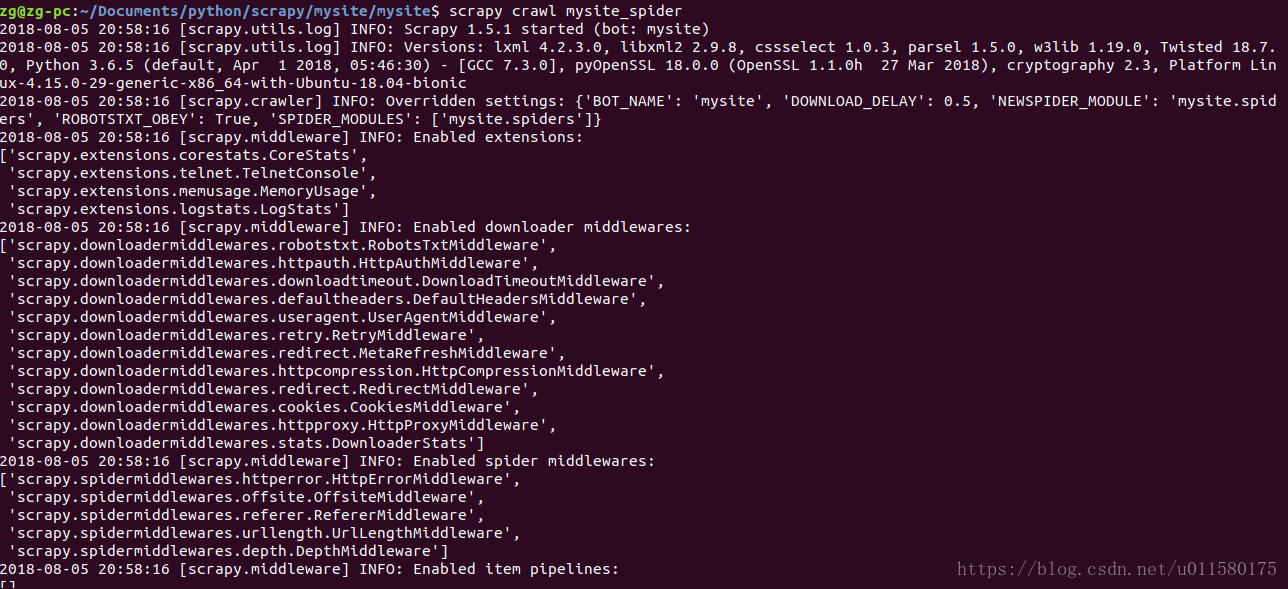
$ scrapy crawl mysite_spider这里的crawl就是爬行的意思 随后,会输出
- 一些这个scrapy版本,以及项目的模块,中间件等的信息
- 以及请求类型,与url和输出的网页的text,也就是网页html源码。
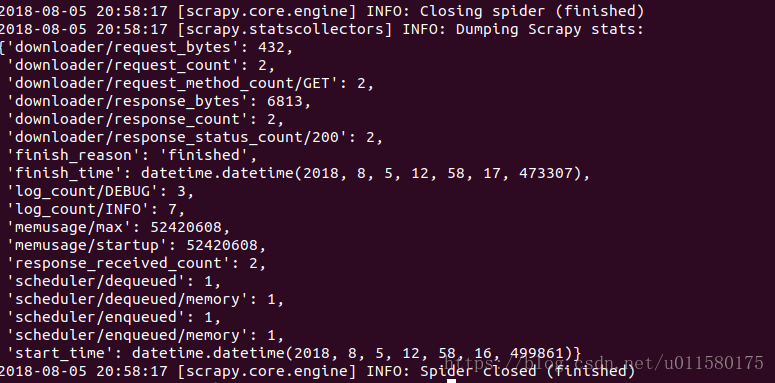
以及,运行结果的报告,数据统计
- 建立main.py文件
如上的运行方式,需要每次进入命令行,运行命令,而且这样不方便调试,所以,最好建立一个main.py文件,运行该爬虫。
在路径mysite/mysite/下,建立文件main.py,内容如下。
- 建立main.py文件
- 一些这个scrapy版本,以及项目的模块,中间件等的信息

from scrapy import cmdline
cmdline.execute('scrapy crawl mysite_spider'.split()) 以后直接F5运行main.py文件就好。