介绍范式之前,先介绍数据库的一些基本概念:
实体:现实世界中客观存在并可以被区别的事物。在数据库中往往是一个数据表。
属性:教科书上解释为:“实体所具有的某一特性”,在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
候选码和主码:表中可以唯一确定一个元组的某个属性(或者属性组)叫候选码,我们从许多个候选码中挑一个就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
函数依赖:
设R(U)是一个属性集U上的一个关系模式,X和Y是U的子集。若对于R(U)的任意两个可能的具体关系r1、r2,若r1[x] == r2[x]则r1[y] == r2[y],或者若r1[x] != r2[x]则r1[y] != r2[y],称X决定Y,或者Y函数依赖于X,记作X→Y。就像函数一样,给一个确定的输入(属性集X),有一个确定的输出(属性集Y)。
抽象的“关系模式”和具体存在的“关系”,下文统称“关系”。
如果X→Y,但Y为X的子集, 则称X→Y是平凡函数依赖。
如:关系R(Sno, Cno),依赖关系(Sno, Cno)→Sno,(Sno, Cno)→Cno都是平凡函数依赖。
如果X→Y,但Y不为X的子集,则称X→Y是非平凡的函数依赖。
如:关系R(Sno, Cno, Grade),依赖关系(Sno, Cno)→Grade是非平凡函数依赖。
如果X→Y,存在X的真子集X1,使得X1→Y,则称Y部分依赖于X。也就是Y依赖于部分的X。
如:学生表(学号, 姓名, 性别, 班级, 年龄),(学号, 姓名)→性别,学号→性别,所以(学号, 姓名)→性别是部分函数依赖。
如果X→Y,但任何X的真子集X1都不存在X1→Y则称Y完全依赖于X。
如:成绩表(学号, 课程号, 成绩),(学号, 课程号)→成绩,学号!→成绩,课程号!→成绩,所以(学号, 课程号)→成绩是完全函数依赖。
如果X→Y,Y→Z,X⊄Y,Y!→X,(X∪Y)∩Z=∅,则称Z传递依赖于X。
如:关系S(学号, 系名, 系主任),学号→系名,系名→系主任,系名!→学号,所以学号→系主任为传递函数依赖。
函数依赖与属性的关系:
设R(U)是属性集U上的关系模式,X、Y是U的子集。
如果X和Y之间是一对一(1:1)关系,如学校和校长,则存在函数依赖X→Y和Y→X。
如果X和Y之间是一对多(1:n)关系,如年龄和姓名,则存在函数依赖Y→X。
如果X和Y之间是多对多(m:n)关系,如学生和课程,则X和Y之间不存在函数依赖。
什么是范式?
设计关系数据库时,需要遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。没有冗余的数据库未必是最好的数据库, 有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式 (5NF,又称完美范式)。
范式之间存在包含关系。一个数据库设计如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式,依次类推。
六种范式的介绍:
第一范式(1NF):
属性不可分。1NF是对属性的原子性约束,要求属性具有原子性,不存在多值属性。即表中的每一个属性都是不可再分的,也就是不能一列再分成两列。
如:
name tel age
手机 座机
Josh 13612345678 021-9876543 22
Wang 13988776655 010-1234567 21
很明显,tel这个属性还可以进行分解,分解成手机和座机这两个属性,不满足第一范式的数据库,不是关系数据库!所以,我们在任何关系数据库管理系统中,做不出这样的“表”来。
第二范式(2NF):
符合1NF,且所有的非主属性都完全依赖于主属性。从这个定义可以看出,第二范式不存在非主属性对于主属性的部分依赖,不过允许非主属性之间存在着传递依赖。2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性,更通俗说有主键。
主属性所属的字段称为主键。注意主属性是一个称为主属性的属性元组。当主键由多个字段组成时称之为复合主键。定义了主键,每条记录就可以通过主属性来唯一标识、区分。这个主键本身不要求有意义,所以经常使用连续增长的数来作为主属性。
主属性元组中的主属性也可能是好几个,如果一个主属性,它不能单独做为一个候选码,那么它也不能确定任何一个非主属性。
如:
我们考虑一个小学的教务 管理系统,学生上课指定一个老师,一本教材,一个教室,一个时间。那么数据库怎么设计?
学生 课程 老师 老师职称 教材 教室 上课时间
小明 一年级语文(上) 大宝 副教授 《小学语文1》 101 14:30
一个学生上一门课,一定在特定某个教室。所以有(学生,课程)->教室
一个学生上一门课,一定是特定某个老师教。所以有(学生,课程)->老师
一个学生上一门课,他老师的职称可以确定。所以有(学生,课程)->老师职称
一个学生上一门课,一定是特定某个教材。所以有(学生,课程)->教材
一个学生上一门课,一定在特定时间。所以有(学生,课程)->上课时间
因此(学生,课程)是一个码。
但是,一个课程,一定指定了某个教材,一年级语文肯定用的是《小学语文1》,那么就有课程->教材。(学生,课程)是个码,课程却决定了教材,这就叫做不完全依赖,或者说部分依赖。出现这样的情况,就不满足第二范式!有什么不好吗?你可以想想:
1、校长要新增加一门课程叫“微积分”,教材是《大学数学》,怎么办?学生还没选课,而学生又是主属性,主属性不能空,课程怎么记录呢,教材记到哪呢? ……郁闷了吧?(插入异常)
2、下学期没学生学一年级语文(上)了,学一年级语文(下)去了,那么表中将不存在一年级语文(上),也就没了《小学语文1》。这时候,校长问:一年级语文(上)用的什么教材啊?……郁闷了吧?(删除异常)
3、校长说:一年级语文(上)换教材,换成《大学语文》。有10000个学生选了这么课,改动好大啊!改累死了……郁闷了吧?(修改异常)
那应该怎么解决呢?投影分解,将一个表分解成两个或若干个表
学生 课程 老师 老师职称 教室 上课时间
小明 一年级语文(上) 大宝 副教授 101 14:30
学生上课表
课程 教材
一年级语文(上) 《小学语文1》
第三范式(3NF):
符合2NF,并要求任何非主属性不依赖于其他非主属性,也就是在第二范式的基础上消除传递依赖(A->B->C)。消除传递依赖。3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
如:
上面的“学生上课表”符合2NF,可以这样验证:两个主属性单独使用,不用确定其它四个非主属性的任何一个。但是它有传递依赖!在“老师”和“老师职称”这里,一个老师一定能确定一个老师职称。
如果不消除这种传递依赖,有可能会出现:
1、老师升级了,变教授了,要改数据库,表中有N条,改了N次……(修改异常)
2、没人选这个老师的课了,老师的职称也没了记录……(删除异常)
3、新来一个老师,还没分配教什么课,他的职称记到哪?……(插入异常)
那应该怎么解决呢?和上面一样,投影分解:
学生 课程 老师 教室 上课时间
小明 一年级语文(上) 大宝 101 14:30
老师 老师职称
大宝 副教授
BC范式(BCNF):
符合3NF,并且主属性内部不能有部分或传递依赖。这将消除对主属性子集的依赖,使主属性保持最简。BC范式既检查非主属性,又检查主属性。当只检查非主属性时,就成了第三范式。满足BC范式的关系都必然满足第三范式。
若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。
如:
若一张表的数据包括:“书号、书名、作者”其中,书号是唯一的,书名允许相同,一个书号对应一本书。一本书的作者可以多个,但是同一个作者所参与编著的书名应该是不同。
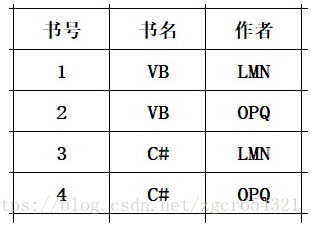
存在关系:
书号→书名
(书名、作者)→书号
其中,每一个属性都为主属性,但是上述关系存在传递依赖,不能是BCNF。即:
(书名、作者)→书号→书名
(书名、作者)→书名
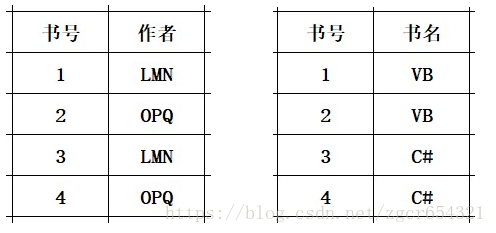
我们可以通过分解为两张表,实现BCNF。
多值依赖:
多值依赖是属性之间的一对多关系,记为K→→A。
函数依赖事实上是单值依赖,所以不能表达属性值之间的一对多关系。(有人称函数依赖为多值依赖的特例)
平凡的多值依赖:全集U=K+A,一个K可以对应于多个A,即K→→A。此时整个表就是一组一对多关系。
非平凡的多值依赖:全集U=K+A+B,一个K可以对应于多个A,也可以对应于多个B,A与B互相独立,即K→→A,K→→B。整个表有多组一对多关系,且有:“一”部分是相同的属性集合,“多”部分是互相独立的属性集合。
第四范式(4NF):
满足BCNF,消除非平凡且非FD的多值依赖(MVD)。4NF就是限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖。对每一个出现的非平凡的多值依赖K→→A,K→→B,分表。即消除多值依赖,只允许函数依赖。也就是说,当一个表中的非主属性互相独立时(3NF),这些非主属性不应该有多值。若有多值就违反了第四范式。显然一个关系模式是4NF,则必为BCNF。
如:
一个表中存在三个数据:“课程、学生、先修课”。假设2017级的计算机专业学生想要学习JAVA课程,那么他们需要先学习VB、C#、BS三门课,才可以选择进行JAVA课程。存在关系:
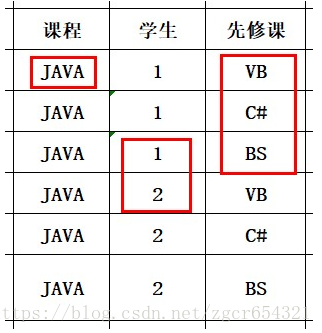
课程→学生
课程→先修课
两个均是1:N的关系,当出现在一张表的时候,会出现大量的冗余。所以就我们需要分解它,减少冗余。分解后如下:

第五范式(5NF):
是最终范式。消除连接依赖,并且必须保证数据完整性。
第五范式有以下要求:必须满足第四范式;表必须可以分解为较小的表,除非那些表在逻辑上拥有与原始表相同的主键。
范式的优化路线:
1NF:
非码的非平凡 | ↓ 消除非主属性对码的部分函数依赖
2NF:
↓ 消除非主属性对码的传递函数依赖
3NF:
↓ 消除主属性对码的部分和传递函数依赖
BCNF:
↓ 消除非平凡且非函数依赖的多值依赖
4NF:
↓消除不是由候选码所蕴含的连接依赖
5NF