版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37251044/article/details/81978136
0.前言
通过之前的学习【Python实现卷积神经网络】:卷积层的正向传播与反向传播+python实现代码,我们知道卷积层的反向传播有三个梯度要求:
1.对输入数据的求导
2.对W的求导
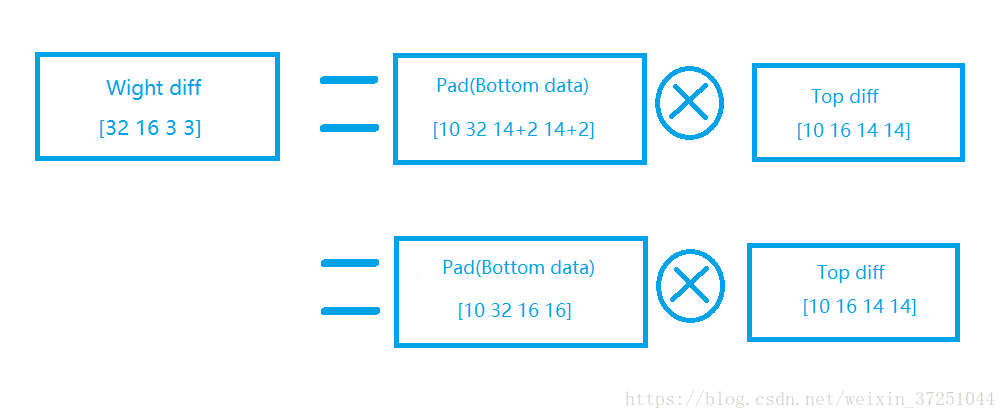
3.对b的求导
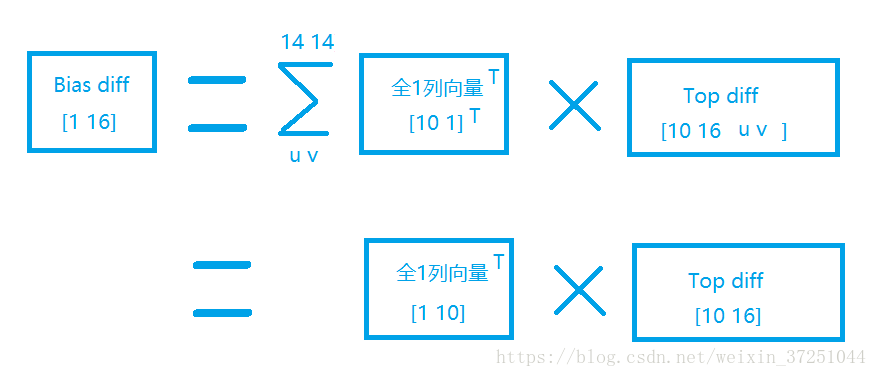
这篇博客推导第一个公式:对输入数据求导。如下公式是怎么来的:
1.【对输入数据求导】计算方法一
我在之前的博客中举了正向传播输入数据不带pad,它的反向传播对输入数据求导的例子。
这里我们通过举另外一个输入数据带pad的正向卷积,然后反向传播的例子。
假设我们现在已经可以递推出上层的梯度误差
δl+1
了;卷积层输出z,输入a和W,b的关系为:
zl=al∗Wl+b
因此本层残差(
δl
)和上层残差(
δl+1
)的递推关系为:
伪码:δl=∂J(W,b)∂al=∂J(W,b)∂zl∂zl∂al=δl+1∗Wl
上边伪码是为了便于推导理解,事实上公式是:
扫描二维码关注公众号,回复:
3054564 查看本文章

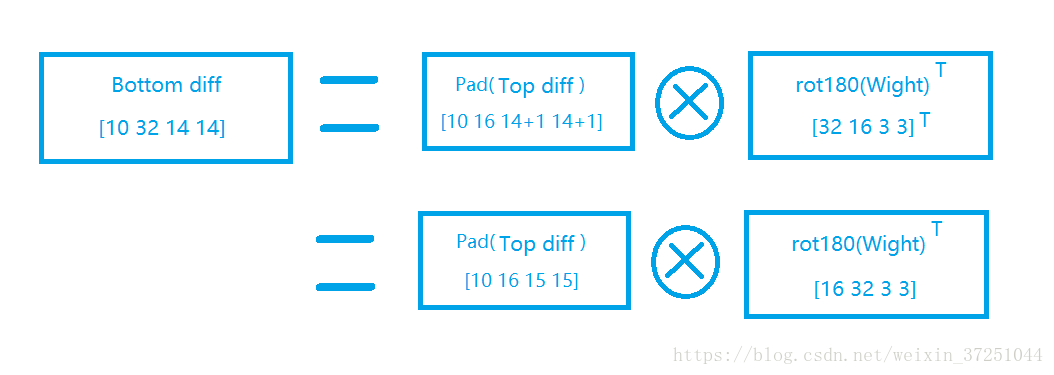
δl=∂J(W,b)∂al=∂J(W,b)∂zl∂zl∂al=pad(δl+1)⊗rot180(Wl)
假设我们输入a是2x2的矩阵,且加入pad=1卷积核W是3x3的矩阵,输出z是2x2的矩阵,那么反向传播的z的梯度误差δ也是2x2的矩阵。我们列出a,W,z的矩阵表达式如下:
⎛⎝⎜⎜⎜00000a11a2100a12a2200000⎞⎠⎟⎟⎟⊗⎛⎝⎜w11w21w31w12w22w32w13w23w33⎞⎠⎟=(z11z21z12z22)
反向传播的
z
的梯度误差
δl+1
是:
(δ11δ21δ12δ22)
利用卷积的定义,很容易得出:
z11=0+0+0+0+a11w22+a12w23+0+a21w32+a22w33z12=0+0+0+a11w21+a12w22+0+a21w31+a22w32+0z21=0+a11w12+a12w13+0+a21w22+a22w23+0+0+0z22=a11w11+a12w12+0+a21w21+a22w22+0+0+0+0
那么根据上面的式子,我们有:
∂J(W,b)∂al11=w22δ11+w21δ12+w12δ21+w11δ22∂J(W,b)∂al12=w23δ11+w22δ12+w13δ21+w12δ22∂J(W,b)∂al21=w32δ11+w31δ12+w22δ21+w21δ22∂J(W,b)∂al22=w33δ11+w32δ12+w23δ21+w22δ22
最终我们可以一共得到4个式子。整理成矩阵形式后可得:
∂J(W,b)∂al=⎛⎝⎜⎜⎜00000δ11δ2100δ12δ2200000⎞⎠⎟⎟⎟⊗⎛⎝⎜w33w23w13w32w22w12w31w21w11⎞⎠⎟
从这个例子证明了刚才的公式的正确性:
δl=∂J(W,b)∂al=∂J(W,b)∂zl∂zl∂al=pad(δl+1)⊗rot180(Wl)
当然,这个仅仅是对输入数据求导的计算公式1,如果我们有别的计算方法能够得出同样的结果,那么我们也可以总结为对输入数据求导的计算公式2。有没有呢?当然有,稍后再表。
1.1.代码
residual_pad = np.pad(residual, ((0,), (0,), (pad_diff_H,), (pad_diff_W,)), mode='constant', constant_values=0)
for i in range(H_out):
for j in range(W_out):
residual_pad_masked = residual_pad[:, :, i*stride:i*stride+HH, j*stride:j*stride+WW]
for h in range(C):
dx_2[:, h , i, j] = np.sum(residual_pad_masked[:,:,:,:] * rot_w[:, h, :, :], axis=(1,2,3))
注意:
这里的pad大小是由正向传播卷积核与正向传播pad共同决定的,不是1。我总结的公式是:
paddiff=kernelsize−(1+padfoward)
至于这个公式是怎么来的,请读者将上边儿我举的例子中3X3的核变成5X5或者7X7的核,然后推导一边就总结出来了。
2.【对输入数据求导】计算方法二
还是上边儿的例子,这次我们换种计算方法,看最终结果和上边最终结果一样不。
我们假设:
∂J(W,b)∂al=pool(d)=pool(⎛⎝⎜⎜⎜d11d21d31d41d12d22d32d42d13d23d33d43d14d24d34d44⎞⎠⎟⎟⎟)=(d22d32d23d33)
注:这里pool()池化的意思,在这里表示去掉d的上下左右各pad=1的数字,剩下的部分。
d11=⎛⎝⎜d11d21d31d12d22d32d13d23d33⎞⎠⎟=⎛⎝⎜w11w21w31w12w22w32w13w23w33⎞⎠⎟∗δ11=⎛⎝⎜w11∗δ11w21∗δ11w31∗δ11w12∗δ11w22∗δ11w32∗δ11w13∗δ11w23∗δ11w33∗δ11⎞⎠⎟
d12=⎛⎝⎜d12d22d32d13d23d33d14d24d34⎞⎠⎟=⎛⎝⎜w11w21w31w12w22w32w13w23w33⎞⎠⎟∗δ12=⎛⎝⎜w11∗δ12w21∗δ12w31∗δ12w12∗δ12w22∗δ12w32∗δ12w13∗δ12w23∗δ12w33∗δ12⎞⎠⎟
d21=⎛⎝⎜d21d31d41d22d32d42d23d33d43⎞⎠⎟=⎛⎝⎜w11w21w31w12w22w32w13w23w33⎞⎠⎟∗δ21=⎛⎝⎜w11∗δ21w21∗δ21w31∗δ21w12∗δ21w22∗δ21w32∗δ21w13∗δ21w23∗δ21w33∗δ21⎞⎠⎟
d22=⎛⎝⎜d22d32d42d23d33d43d24d34d44⎞⎠⎟=⎛⎝⎜w11w21w31w12w22w32w13w23w33⎞⎠⎟∗δ22=⎛⎝⎜w11∗δ22w21∗δ22w31∗δ22w12∗δ22w22∗δ22w32∗δ22w13∗δ22w23∗δ22w33∗δ22⎞⎠⎟
然后,将
d11,d12,d21,d22
中相应
di,j
的位置相加,得到:
d11=w11∗δ11
...
d22=w22∗δ11+w21∗δ12+w12∗δ21+w11∗δ22
d23=w23∗δ11+w22∗δ12+w13∗δ21+w12∗δ22
d32=w32∗δ11+w31∗δ12+w22∗δ21+w21∗δ22
d23=w33∗δ11+w32∗δ12+w23∗δ21+w22∗δ22
...
d44=w33∗δ22
可以看出,我们的计算结果与第一个公式一样:
∂J(W,b)∂al=⎛⎝⎜∂J(W,b)∂al11∂J(W,b)∂al21∂J(W,b)∂al12∂J(W,b)∂al22⎞⎠⎟=(d22d32d23d33)
注意:计算方法二不需要rot180(w)
2.1.代码:
for i in range(H_out):
for j in range(W_out):
x_pad_masked = x_pad[:, :, i * stride:i * stride + HH, j * stride:j * stride + WW]
for k in range(F):
dw[k, :, :, :] += np.sum(x_pad_masked * (residual[:, k, i, j])[:, None, None, None], axis=0)
for n in range(N):
dx_pad[n, :, i * stride:i * stride + HH, j * stride:j * stride + WW] += np.sum((self.w[:, :, :, :] * (residual[n, :, i,j])[:, None, None, None]), axis=0)