什么是XML?
XML指可扩展标记语言(EXtensible Markup Language)。是一种标记语言,很类似HTML。XML标签没有被预定义,需要我们自定义标签。
XML的用途
- 保存数据
- 作配置文件
- 数据传输
XML实例
<?xml version="1.0" encoding="UTF-8"?>
<stus>
<stu>
<name>Tom</name>
<age>20</age>
</stu>
<stu>
<name>Mary</name>
<age>25</age>
</stu>
</stus>XML文件结构
- 文档声明
- XML元素
文档声明
第一行<?xml version="1.0" encoding="UTF-8"?>是文档声明。
version:定义了XML的版本,解析器会根据指定的版本来进行解析。encoding:定义了XML使用的编码,解析器会根据指定的编码来进行解析。
使用eclipse创建xml文件即可生成文档声明
XML元素
XML 元素指的是从(且包括)
开始标签直到(且包括)结束标签的部分。
元素可包含其他
元素、文本或者两者的混合物。元素也可以拥有属性。<stu> <name id="1">Tom</name> <age>20</age> </stu>stu元素中包含了name,age元素;
name元素中包含了文本Tom, 拥有属性id。元素可由单个标签或成对出现的标签组成。
<bean id="CategoryDao" class="CategoryDaoImp"/> <name id="1">Tom</name>文档声明下来的第一个元素叫做根元素 。上面的例子中
stu就是根元素。
XML基本语法
- 所有XML元素都须有关闭标签
- XML标签对大小写敏感
- XML必须正确地嵌套
- XML文档必须有根元素
- XML的属性值须加引号
- XML使用
<!-- This is a comment -->添加注释 - XML中,空格会被保留
具体见:XML 语法规则
XML解析
获取元素里面的文本数据或者属性数据
XML解析方式
常用的有:
- DOM
SAX
DOM
Document Object Model,文档对象模型。可以认为是把整个XML全部读到内存中,形成树状结构。适合于对文件进行修改和随机存取的操作,但是不适合于大型文件的操作。
- 整个文档对应为:Document对象
- 属性对应为:Attribute对象
- 元素结点对应为:Element对象
- 文本对应为:Text对象
以上的所有对象都可以抽象为:Node结点
SAX
Simple API for Xml,基于事件驱动。读取一行,解释一行。采用顺序的方式读取XML文件中,不受文件大小限制,但是不允许修改。
JDOM && DOM4J
JDOM
JDOM是使用Java编写的,用于读、写、操作XML的一套
组件。
JDOM =DOM修改文件的优点 +SAX读取快速的优点DOM4J
DOM4J也是一组
XML操作组件包,主要用来读写XML文件,由于dom4j性能优异、功能强大,且具有易用性,所以现在已经被广泛地应用开来。
更多关于DOM、SAX、JDOM、DOM4J可以参考:Java高级进阶-xml解析
使用DOM4J解析XML
准备工作
- 导入DOM4J依赖的jar包:dom4j-1.6.1.jar
- 待解析XML文件:stu.xml(放于src目录下)
<?xml version="1.0" encoding="UTF-8"?>
<stus>
<stu id="1">
<name>Tom</name>
<age>13</age>
<sex>男</sex>
</stu>
<stu id="2">
<name>Mary</name>
<age>12</age>
<sex>女</sex>
</stu>
</stus> 编码
package com.mbc.test;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jDemo {
public static void main(String[] args) throws DocumentException {
// 1.创建SaxReader解析器
SAXReader reader = new SAXReader();
// 2.指定解析的xml文件
File stu = new File("src/stu.xml");
Document document = reader.read(stu);
// 3.得到根元素
Element root = document.getRootElement();
// 4.获取根元素下面的所有子元素(stu元素)
List<Element> elements = root.elements();
// 5.遍历所有的stu元素
for (Element element : elements) {
// 获取元素指定的属性对应的值(每个stu的id)
String id = element.attributeValue("id");
// 获取stu元素下的name元素里的文本
String name = element.element("name").getText();
// 获取stu元素下的sex元素里的文本
String sex = element.element("sex").getText();
System.out.println("id: " + id + " name: " + name + " sex: " + sex);
}
}
}
运行结果:

使用DOM4J+Xpath解析XML
Xpath
Xpath是XML的路径语言,支持我们在解析XML时,能快速定位到具体的某一个元素。
例如:

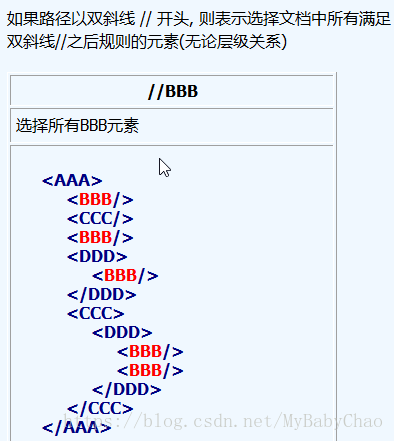
更多的使用,请参考Xpath的帮助文档。
准备工作
- 导入DOM4J依赖的jar包:dom4j-1.6.1.jar
- Xpath依赖的jar包:jaxen-1.1-beta-6.jar
- 待解析XML文件:stu.xml(放于src目录下)
package com.mbc.test;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
*
* 使用dom4j + xpath方法快速定位到具体的某一个元素
*/
public class Dom4jAndXpath {
public static void main(String[] args) throws DocumentException {
// 1.创建SaxReader解释器
SAXReader reader = new SAXReader();
// 2.指定待解释的xml文件(获得Document对象)
Document document = reader.read(new File("src/stu.xml"));
// 3.获得根元素
Element root = document.getRootElement();
// 4、获得根元素下的特定子元素(列表)
// "//name"表示获取所有满足//之后规则的元素,这里使用selectSingleNode()获取满足规则的第一个元素
Element node = (Element) root.selectSingleNode("//name");
System.out.println("第一个name元素:" + node.getText());
// 获取name元素的列表
System.out.println("name元素列表");
List<Element> nameNodes = root.selectNodes("//name");
for (Element element : nameNodes) {
System.out.println(element.getText());
}
}
}
总结
- XML的基本认识。
- 解析XML的方式
- 使用DOM4J组件解析XML
- 使用DOM4J+Xpath解析XML