站在老罗的肩膀上:https://blog.csdn.net/luoshengyang/article/details/50558942
在Chromium中,Render进程是通过Browser进程下载网页内容的,后者又是通过共享内存将下载回来的网页内容交给前者的。Render进程获得网页内容之后,会交给WebKit进行处理。WebKit所做的第一个处理就是对网页内容进行解析,解析的结果是得到一棵DOM Tree。DOM Tree是网页的一种结构化描述,也是网页渲染的基础。
网页的DOM Tree的根节点是一个Document。Document是依附在一个DOM Window之上。DOM Window又是和一个Frame关联在一起的。Document、DOM Window和Frame都是WebKit里面的概念,其中Frame又是和Chromium的Content模块中的Render Frame相对应的。Render Frame是和网页的Frame Tree相关的一个概念。关于网页的Frame Tree,可以参考前面Chromium Frame Tree创建过程分析一文。
上面描述的各种对象的关系可以通过图1描述,如下所示:
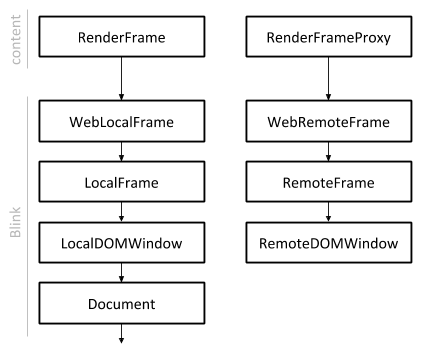
图1 Frame、DOM Window和Document的关系
从前面Chromium Frame Tree创建过程分析一文可以知道,有的Render Frame只是一个Proxy,称为Render Frame Proxy。Render Frame Proxy描述的是在另外一个Render进程中进行加载和渲染的网页。这种网页在WebKit里面对应的Frame和DOM Window分别称为Remote Frame和Remote DOM Window。由于Render Frame Proxy描述的网页不是在当前Render进程中加载和渲染,因此它是没有Document的。
相应地,Render Frame描述的是在当前Render进程中进行加载和渲染的网页,它是具有Document的,并且这种网页在WebKit里面对应的Frame和DOM Window分别称为Local Frame和Local DOM Window。
接下来,我们就结合源码分析WebKit在解析网页内容的过程中创建DOM Tree的过程。从前面Chromium网页URL加载过程分析一文可以知道,Browser进程一边下载网页的内容,一边将下载回来的网页交给Render进程的Content模块。Render进程的Content模块经过简单的处理之后,又会交给WebKit进行解析。WebKit是从ResourceLoader类的成员函数didReceiveData开始接收Chromium的Content模块传递过来的网页内容的,因此我们就从这个函数开始分析WebKit解析网页内容的过程,也就是网页DOM Tree的创建过程。
ResourceLoader类的成员函数didReceiveData的调用和实现如下所示:

void ResourceLoader::DidReceiveData(const char* data, int length) {
CHECK_GE(length, 0);
Context().DispatchDidReceiveData(resource_->Identifier(), data, length);
resource_->AppendData(data, length);
}src/third_party/blink/renderer/platform/loader/fetch/resource_loader.cc
void Resource::AppendData(const char* data, size_t length) {
...
ResourceClientWalker<ResourceClient> w(Clients());
while (ResourceClient* c = w.Next())
c->DataReceived(this, data, length);
}src/third_party/blink/renderer/platform/loader/fetch/resource.cc
从前面Chromium网页URL加载过程分析一文可以知道,DocumentLoader对象是从ResourceClient类继承下来的,它负责创建和加载网页的文档对象。接下来我们就继续分析它的成员函数dataReceived的实现,如下所示:
void DocumentLoader::DataReceived(Resource* resource,
const char* data,
size_t length) {
...
base::AutoReset<bool> reentrancy_protector(&in_data_received_, true);
ProcessData(data, length);
ProcessDataBuffer();
}
void DocumentLoader::ProcessData(const char* data, size_t length) {
...
CommitData(data, length);
...
}DocumentLoader类的成员函数dataReceived主要是调用另外一个成员函数commitData处理从Web服务器下载回来的网页数据,后者的实现如下所示:
void DocumentLoader::CommitData(const char* bytes, size_t length) {
...
if (parser_blocked_count_) {
if (!committed_data_buffer_)
committed_data_buffer_ = SharedBuffer::Create();
committed_data_buffer_->Append(bytes, length);
} else {
parser_->AppendBytes(bytes, length);
}
}src/third_party/blink/renderer/core/loader/document_loader.cc,parser_为 HTMLDocumentPaser
void HTMLDocumentParser::AppendBytes(const char* data, size_t length) {
if (!length || IsStopped())
return;
if (ShouldUseThreading()) {
if (!have_background_parser_)
StartBackgroundParser();
std::unique_ptr<Vector<char>> buffer =
std::make_unique<Vector<char>>(length);
memcpy(buffer->data(), data, length);
TRACE_EVENT1(TRACE_DISABLED_BY_DEFAULT("blink.debug"),
"HTMLDocumentParser::appendBytes", "size", (unsigned)length);
loading_task_runner_->PostTask(
FROM_HERE,
WTF::Bind(&BackgroundHTMLParser::AppendRawBytesFromMainThread,
background_parser_, WTF::Passed(std::move(buffer))));
return;
}HTMLDocumentParser类的成员函数appendBytes调用另外一个成员函数shouldUseThreading判断是否需要在一个专门的线程中对下载回来的网页数据进行解析。如果需要的话,那么就把下载回来的网页数据拷贝到一个新的缓冲区中去交给专门的线程进行解析。否则的话,就在当前线程中调用父类DecodedDataDocumentParser类的成员函数appendBytes对下载回来的网页数据进行解析。为了简单起见,我们分析后一种情况,也就是分析DecodedDataDocumentParser类的成员函数appendBytes的实现。
void DecodedDataDocumentParser::AppendBytes(const char* data, size_t length) {
...
String decoded = decoder_->Decode(data, length);
UpdateDocument(decoded);
}src/third_party/blink/renderer/core/dom/decoded_data_document_parser.cc
DecodedDataDocumentParser类的成员变量m_decoder指向一个TextResourceDecoder对象。这个TextResourceDecoder对象负责对下载回来的网页数据进行解码。解码后得到网页数据的字符串表示。这个字符串将会交给由另外一个成员函数updateDocument进行处理。
DecodedDataDocumentParser类的成员函数updateDocument的实现如下所示:
void DecodedDataDocumentParser::UpdateDocument(String& decoded_data) {
GetDocument()->SetEncodingData(DocumentEncodingData(*decoder_.get()));
if (!decoded_data.IsEmpty())
Append(decoded_data);
}DecodedDataDocumentParser类的成员函数updateDocument又将参数decodedData描述的网页内容交给由子类HTMLDocumentParser实现的成员函数append处理。
HTMLDocumentParser类的成员函数append的实现如下所示:
void HTMLDocumentParser::Append(const String& input_source) {
...
const SegmentedString source(input_source);
...
input_.AppendToEnd(source);
...
PumpTokenizerIfPossible();
EndIfDelayed();
}src/third_party/blink/renderer/core/html/parser/html_document_parser.cc
HTMLDocumentParser类的成员函数append首先将网页内容附加在成员变量input_描述的一个输入流中,接下来再调用成员函数pumpTokenizerIfPossible对该输入流中的网页内容进行解析。
接下来我们就继续分析HTMLDocumentParser类的成员函数pumpTokenizerIfPossible的实现,如下所示:
void HTMLDocumentParser::PumpTokenizerIfPossible() {
CheckIfBodyStylesheetAdded();
if (IsStopped() || IsPaused())
return;
PumpTokenizer();
}之前的实现在调用成员函数pumpTokenizerIfPossible的时候,根据成员变量m_isPinnedToMainThread的值的不同而传递不同的参数。当成员变量m_isPinnedToMainThread的值等于true的时候,传递的参数为ForceSynchronous,表示要以同步方式解析网页的内容。当成员变量m_isPinnedToMainThread的值等于false的时候,传递的参数为AllowYield,表示要以异步方式解析网页的内容。在同步解析网页内容方式中,当前线程会一直运行到所有下载回来的网页内容都解析完为止,除非遇到有JavaScript需要运行。在异步解析网页内容方式中,在遇到有JavaScript需要运行,或者解析的网页内容超过一定量时,如果当前线程花在解析网页内容的时间超过预设的阀值,那么当前线程就会自动放弃CPU,通过一个定时器等待一小段时间后再继续解析剩下的网页内容。(猜测目前可能默认就异步了)
HTMLDocumentParser类的成员函数pumpTokenizer的实现如下所示:
void HTMLDocumentParser::PumpTokenizer() {
...
PumpSession session(pump_session_nesting_level_);
...
while (CanTakeNextToken()) {
...
{
...
if (!tokenizer_->NextToken(input_.Current(), Token()))
break;
}
...
}
ConstructTreeFromHTMLToken();
...
}
...
}HTMLDocumentParser类的成员函数pumpTokenizer通过成员变量tokenizer_描述的一个HTMLTokenizer对象的成员函数nextToken对网页内容进行字符串解析。网页内容被解析成一系列的Token。每一个Token描述的要么是一个标签,要么是一个标签的内容,也就是文本。
注意,HTMLDocumentParser类的成员函数pumpTokenizer通过一个while循环依次提取网页内容的Token,并且每提取一个Token,都会调用一次HTMLDocumentParser类的成员函数constructTreeFromHTMLToken。这个while循环在三种情况下会结束。
第一种情况是所有的Token均已提取并且处理完毕。第二种情况是在解析的过程中遇到JavaScript脚本需要执行,这时候调用HTMLDocumentParser类的成员函数canTakeNextToken的返回值会等于false。第三种情况出现在异步方式解析网页内容时,这时候HTMLDocumentParser类的成员函数canTakeNextToken会将本地变量session描述的一个PumpSession对象的成员变量needsYield的值设置为true,表示当前线程持续解析的网页内容已经达到一定量并且持续的时间也超过了一定值,需要自动放弃使用CPU。
有了这些Token之后,HTMLDocumentParser类的成员函数pumpTokenizer就可以构造DOM Tree了。这是通过调用另外一个成员函数constructTreeFromHTMLToken进行的。
void HTMLDocumentParser::ConstructTreeFromHTMLToken() {
DCHECK(!GetDocument()->IsPrefetchOnly());
AtomicHTMLToken atomic_token(Token());
...
tree_builder_->ConstructTree(&atomic_token);
...
}src/third_party/blink/renderer/core/html/parser/html_document_parser.cc
HTMLDocumentParser类的成员函数constructTreeFromHTMLToken所做的事情就是根据参数rawToken描述的一个Token来不断构造网页的DOM Tree。这个构造过程是通过调用成员变量m_treeBuilder描述的一个HTMLTreeBuilder对象的成员函数constructTree实现的。
HTMLTreeBuilder类的成员函数constructTree的实现如下所示:
void HTMLTreeBuilder::ConstructTree(AtomicHTMLToken* token) {
RUNTIME_CALL_TIMER_SCOPE(V8PerIsolateData::MainThreadIsolate(),
RuntimeCallStats::CounterId::kConstructTree);
if (ShouldProcessTokenInForeignContent(token))
ProcessTokenInForeignContent(token);
else
ProcessToken(token);
...
tree_.ExecuteQueuedTasks();
}src/third_party/blink/renderer/core/html/parser/html_tree_builder.cc
HTMLTreeBuilder类的成员函数constructTree首先调用成员函数shouldProcessTokenInForeignContent判断参数token描述的Token是否为Foreign Content,即不是HTML标签相关的内容,而是MathML和SVG这种外部标签相关的内容。如果是的话,就调用成员函数processTokenInForeignContent对它进行处理。
如果参数token描述的是一个HTML标签相关的内容,那么HTMLTreeBuilder类的成员函数constructTree就会调用成员函数processToken对它进行处理。接下来我们只关注HTML标签相关内容的处理过程。
处理完成参数token描述的Token之后,HTMLTreeBuilder类的成员函数constructTree会调用成员变量tree_描述的一个HTMLConstructionSite对象的成员函数executeQueuedTasks执行保存其内部的一个事件队列中的任务。这些任务是处理参数token描述的标签的过程中添加到事件队列中去的,主要是为了处理那些在网页中没有正确嵌套的格式化标签的。HTML标准规定了处理这些没有正确嵌套的格式化标签的算法,具体可以参考标准中的12.2.3.3小节:The list of active formatting elements。WebKit在实现这个算法的时候,就用到了上述的事件队列。
接下来我们继续分析HTMLTreeBuilder类的成员函数processToken的实现,如下所示:
void HTMLTreeBuilder::ProcessToken(AtomicHTMLToken* token) {
if (token->GetType() == HTMLToken::kCharacter) {
ProcessCharacter(token);
return;
}
// Any non-character token needs to cause us to flush any pending text
// immediately. NOTE: flush() can cause any queued tasks to execute, possibly
// re-entering the parser.
tree_.Flush(kFlushAlways);
should_skip_leading_newline_ = false;
switch (token->GetType()) {
case HTMLToken::kUninitialized:
case HTMLToken::kCharacter:
NOTREACHED();
break;
case HTMLToken::DOCTYPE:
ProcessDoctypeToken(token);
break;
case HTMLToken::kStartTag:
ProcessStartTag(token);
break;
case HTMLToken::kEndTag:
ProcessEndTag(token);
break;
case HTMLToken::kComment:
ProcessComment(token);
break;
case HTMLToken::kEndOfFile:
ProcessEndOfFile(token);
break;
}
}如果参数token描述的Token的类型是HTMLToken::kCharacter,就表示该Token代表的是一个普通文本。这些普通文本不会马上进行处理,而是先保存在内部的一个Pending Text缓冲区中,这是通过调用HTMLTreeBuilder类的成员函数processCharacter实现的。等到遇到下一个Token的类型不是HTMLToken::Character时,才会对它们进行处理,这是通过调用成员变量tree_描述的一个HTMLConstructionSite对象的成员函数flush实现的。
对于非HTMLToken::Character类型的Token,HTMLTreeBuilder类的成员函数processToken根据不同的类型调用不同的成员函数进行处理。在处理的过程中,就会使用图3所示的栈构造DOM Tree,并且会遵循HTML规范,具体可以参考这里:HTML Standard。例如,对于HTMLToken::StartTag类型的Token,就会调用成员函数processStartTag执行一个压栈操作,而对于HTMLToken::EndTag类型的Token,就会调用成员函数processEndTag执行一个出栈操作。
以图2所示的DOM Tree片段为例,它对应的网页内容为:
<div>
<p>
<div></div>
</p>
<span></span>
</div>各个标签的压栈和出栈过程如图3所示:
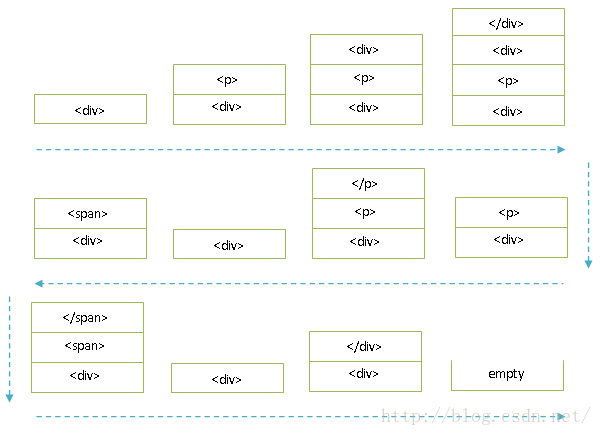
图3 网页内容解析过程中的HTML标签压栈和出栈操作
接下来我们主要分析HTMLTreeBuilder类的成员函数processStartTag的实现,主要是为了解WebKit在内部是如何描述一个HTML标签的。
HTMLTreeBuilder类的成员函数processStartTag的实现如下所示:
void HTMLTreeBuilder::ProcessStartTag(AtomicHTMLToken* token) {
DCHECK_EQ(token->GetType(), HTMLToken::kStartTag);
switch (GetInsertionMode()) {
...
case kInBodyMode:
DCHECK_EQ(GetInsertionMode(), kInBodyMode);
ProcessStartTagForInBody(token);
break;
...
}
}void HTMLTreeBuilder::ProcessStartTagForInBody(AtomicHTMLToken* token) {
...
if (token->GetName() == addressTag || token->GetName() == articleTag ||
token->GetName() == asideTag || token->GetName() == blockquoteTag ||
token->GetName() == centerTag || token->GetName() == detailsTag ||
token->GetName() == dirTag || token->GetName() == divTag ||
token->GetName() == dlTag || token->GetName() == fieldsetTag ||
token->GetName() == figcaptionTag || token->GetName() == figureTag ||
token->GetName() == footerTag || token->GetName() == headerTag ||
token->GetName() == hgroupTag || token->GetName() == mainTag ||
token->GetName() == menuTag || token->GetName() == navTag ||
token->GetName() == olTag || token->GetName() == pTag ||
token->GetName() == sectionTag || token->GetName() == summaryTag ||
token->GetName() == ulTag) {
ProcessFakePEndTagIfPInButtonScope();
tree_.InsertHTMLElement(token);
return;
}
...
}HTMLConstructionSite类的成员函数insertHTMLElement的实现如下所示:
void HTMLConstructionSite::InsertHTMLElement(AtomicHTMLToken* token) {
Element* element = CreateElement(token, xhtmlNamespaceURI);
AttachLater(CurrentNode(), element);
open_elements_.Push(HTMLStackItem::Create(element, token));
}src/third_party/blink/renderer/core/html/parser/html_construction_site.cc
HTMLConstructionSite类的成员函数insertHTMLElement首先调用成员函数createHTMLElement创建一个HTMLElement对象描述参数token代表的HTML标签,接着调用成员函数attachLater稍后将该HTMLElement对象设置为当前栈顶HTMLElement对象的子HTMLElement对象,最后又将该HTMLElement对象压入成员变量open_elements_描述的栈中去。
接下来我们主要分析HTMLConstructionSite类的成员函数createHTMLElement的实现,以便了解WebKit是如何描述一个HTML标签的。 HTMLConstructionSite类的成员函数createHTMLElement的实现如下所示:
Element* HTMLConstructionSite::CreateElement(
AtomicHTMLToken* token,
const AtomicString& namespace_uri) {
...
Element* element;
if (will_execute_script) {
...
element = definition->CreateAutonomousCustomElementSync(document, tag_name);
...
for (const auto& attribute : token->Attributes())
element->setAttribute(attribute.GetName(), attribute.Value());
} else {
if (definition) {
DCHECK(GetCreateElementFlags().IsAsyncCustomElements());
element = definition->CreateElement(document, tag_name,
GetCreateElementFlags());
} else {
// Normally goes into here 常规标签此处建立
element = CustomElement::CreateUncustomizedOrUndefinedElement(
document, tag_name, GetCreateElementFlags(), is);
}
FormAssociated* form_associated_element =
element->IsHTMLElement()
? ToHTMLElement(element)->ToFormAssociatedOrNull()
: nullptr;
...
SetAttributes(element, token, parser_content_policy_);
}
return element;
}src/third_party/blink/renderer/core/html/custom/custom_element.cc
网页内容下载完成之后,DOM Tree的构造过程就结束。接下来WebKit就会根据DOM Tree创建Layout Object Tree。