1.项目说明
对3个月的A,B两种产品的数据进行数据过程中,对分析过程:数据读取,清洗,处理,可视化。
进行数学建模分析,采用函数式编程方式算法构建
2.项目具体要求
- 批量读取数据,并输出以下信息
(1)数据量
(2)数据字段columns
(3)输出每个文件分别有多少缺失值 - 批量读取数据,用均值填充缺失值数据,并完成以下计算及图表制作
(1)读取数据并用均值填充缺失值;对“日期”字段进行时间序列处理,转换成日period ,最后输出三个Dataframe文件data1,data2,data3
(2)分别计算data1,data2,data3中A,B产品的月总销量,并绘制多系列柱状图,存储在对应的图片文件夹路径
(3)分别计算A产品在每个月中哪一天超过了月度80%的销量,输出日期 - 读取数据并合并,做散点图观察A,B产品销量,并做回归,预测当A销量为1200时,B产品销量值
(1)读取数据删除缺失值;对“日期”字段进行时间序列处理,转换成日period ,合并三个月数据,输出data;
(2)针对A产品销量和B产品销量数据做回归分析,制作散点图并存储,并预测当A销量为1200时,B产品销量值
3.实现思路:
- 由于有三个文件因此在读取文件数据需要获得文件夹中的文件名称,然后循环读取文件并输出相应数据,可以使用os.walk(path)方法获得路径中的信息及文件,最后返回读取文件数据的list.
- 对文件数据list做for循环,用函数分别处理缺失值,时间序列处理,然后将处理完的数据连接成一个dataframe表格,
然后对表格数据做柱状图。使用cunsum()方法按日期计算累计销量,来计算那一天超过月度80%销量. - 使用两个函数完成数据的清洗,处理以及数据建模分析。LinearRegression()来构建回归模型,用于预测销量
4.实现过程:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import os
def get_data(path):
data = []
for root,dirs,files in os.walk(path): #返回路径中的信息及文件,使用for循环读取生成器数据
for file in files: #循环获取文件名称
df = pd.read_excel(os.path.join(root,file),index_col=0) #根据文件名生成文件路径,读取文件为DataFrame
file_name = file.split('.')[0] # 去除后缀,获取文件名称
print('%s的数据量为%i' %(file_name,len(df))) #输出回数据量
print('%s的columns为' % file_name,list(df.columns)) #输出数据字段columns
n = 0
for column in df.columns: #循环获取每一列中空值,相加为空值总数量
n+=df[column].isnull().value_counts()[True]
print('%s共有有%i个缺失值'%(file_name,n))
print('-------------')
data.append(df)
print('finished!')
return(data) #返回所有读取的文件的list
path = input('请输入文件路径:') #使用input读取文件夹路径
datalist1 = get_data(path)说明:os.walk(path)方法会逐层返回路径下的 root(路径),dirs(文件夹),files(文件)名称,通过连接root和file生成文件路径,
再使用pandas.read_excel()读取数据,然后输出所需信息,这里是每个数据表的数据量,字段名,缺失值数量。
#读取数据并用均值填充缺失值
def f_na(datalist):
dt = []
for i in range(len(datalist)):
dt.append(datalist[i].fillna(datalist[i].mean()))
return (dt)
datalist2 = f_na(datalist1)
#对“日期”字段进行时间序列处理,转换成日period ,最后输出三个Dataframe文件data1,data2,data3
def f_time(datalist):
for data in datalist:
data.index = data.index.to_period() #转换成日period
return datalist #输出三个Dataframe文件data1,data2,data3
data1,data2,data3 = f_time(datalist2)
#分别计算data1,data2,data3中A,B产品的月总销量,并绘制多系列柱状图,存储在对应的图片文件夹路径
def f_plot(*data):
df = pd.concat(data)
df_g = df.groupby(df.index.month).sum() #计算data1,data2,data3中A,B产品的月总销量
df_g.plot(kind = 'bar',color = ['c','y'],grid = True,alpha = 0.8,rot = 0,figsize =(13,8)) #绘制多系列柱状图
plt.title('A,B产品月总销量')
plt.xlabel('')
plt.ylim(0,30000)
plt.savefig('c://test//pic//sales.jpg') #存储在对应的图片文件夹路径
f_plot(data1,data2,data3 )
#分别计算A产品在每个月中哪一天超过了月度80%的销量,输出日期
def f_p(*datas):
for data in datas:
p = data['productA'].cumsum()/data['productA'].sum()
key = p[p>0.8].index[0]
print('A产品在%s月%s日销量超过当月80%%' % (str(key).split('-')[1].strip('0'),str(key).split('-')[2]))
f_p(data1,data2,data3)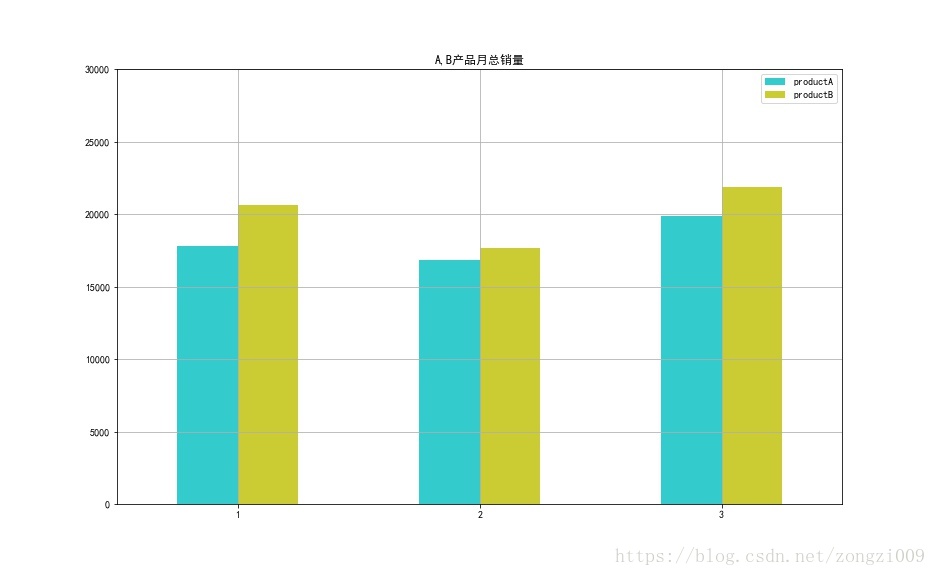
说明:分别创建4个函数分别处理缺失值,转换日期时间序列,计算总销量绘制柱状图,计算超过80%销量的日期。
#读取数据删除缺失值;对“日期”字段进行时间序列处理,转换成日period ,合并三个月数据,输出data
def get_data2(path):
dflist = []
for root,dirs,files in os.walk(path):
for file in files:
df = pd.read_excel(os.path.join(root,file),index_col=0)# 读取数据为DataFrame
df.index = df.index.to_period() #转换成日period
df.dropna(inplace = True) #数据删除缺失值
dflist.append(df)
data = pd.concat(dflist) #合并三个月数据
return data
data = get_data2(path)
#针对A产品销量和B产品销量数据做回归分析,制作散点图并存储,并预测当A销量为1200时,B产品销量值
def regression(data,x):
model = LinearRegression() #构建回归模型
model.fit(data.iloc[:,[0]],data.iloc[:,[1]]) #拟合直线
print('当A销量为1200时,B产品销量为%.2f' % model.predict(x)) #预测当A销量为1200时,B产品销量值
xtest = np.linspace(0,1000,1000)
ytest = model.predict(xtest[:,np.newaxis]) #创建测试数据
fig= plt.figure(figsize = (12,8))
plt.scatter(data.iloc[:,0],data.iloc[:,1],marker = '.',c = 'k',alpha = 0.8)#制作散点图
plt.plot(xtest,ytest,color ='r')
plt.grid()
plt.title('A,B产品回归分析图')
plt.savefig('C:\\test\\pic\\regression.jpg')
regression(data,1200)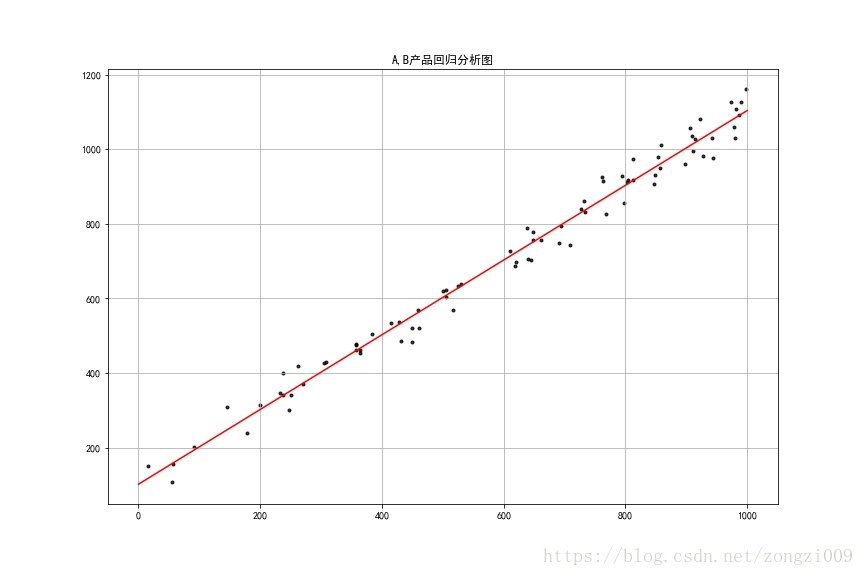
说明:这里对数据做回归分析分为两步,首先创建函数对数据进行清洗,传出缺失值,转换日期时间序列,并将
读取的不同表格数据合并为一个dataframe.数据用于后面的回归分析。
创建回归分析函数,函数传入两个参数:用于分析的数据(data),预测的数据(x),做回归分析的数据分别
是A,B两种产品的销量数据,用构建的回归模型拟合直线,然后预测A销售量为1200时B产品的销量。
5.总结
- 该项目要求有能力根据要求创建函数,并运用其解决实际的问题,从数据读取开始,到后面的数据清洗,数据统计计算,数据可视化,数学建模,多场景下进行函数构建。
- 函数构建是算法构建的基础,通过该项目对如何构建函数解决实际问题有了一个比较全面的学习,对复杂算法的构建及运用打下基础。