算法这条路,是自己目前下定决心去学习,所以,不管遇到多少困难,都希望自己能够坚持下去!还有一年即将面临择业,望付出自己的努力。嘿嘿,不矫情,开始正式的讲解。 —–雷钝
冒泡排序
冒泡排序就是像自然中冒泡的现象一样,把数据排好序。解释如下。
想象有一个直上直下的圆筒,圆筒中装满了水。水中竖直悬浮着大大小小的气泡,圆筒中每个位置有且只有一个气泡。气泡由于浮力的作用,会不断地往上浮。每次从最下面的气泡开始,如果这个气泡碰到上面比它小的气泡,它就和这个小的气泡交换位置;如果这个气泡碰到上面比它大的气泡,它就保持不动,然后那个大的气泡接替它,继续这样往上浮,直到碰到圆筒最上面,已经排好序了的都比它大的气泡为止。随着气泡们这样不断地上浮,最终圆筒中的气泡,会变成大气泡在上,小气泡在下的排好序的形式,冒泡排序完毕。可以看见,越大的气泡,越会快速地上升到圆筒的顶端,这正好和气泡越大,往上冒的速度越快的自然现象不谋而合。这又让你不得不佩服取名者的智慧。

一图胜千言。上面的解释,再结合下面的动态图,相信你会更加明了。相信在未来的某一天,你会一说冒泡排序,就会想到自然界中的冒泡现象,自然而然地写出冒泡排序算法。

问题提出:
将以下数据升序排列:9, 2, 8, 6, 4
冒泡排序原理:
冒泡排序就是遍历数据,每次只与下一个数字比较,如果这两个数顺序不对,则与交换过来。
就上面那个问题来说,因为要升序排列,所以数字越大越排在后面。则两个数比较的时候,如果后一个数比当前数小,则顺序不对,要将这两个数交换。遍历的过程如下图:
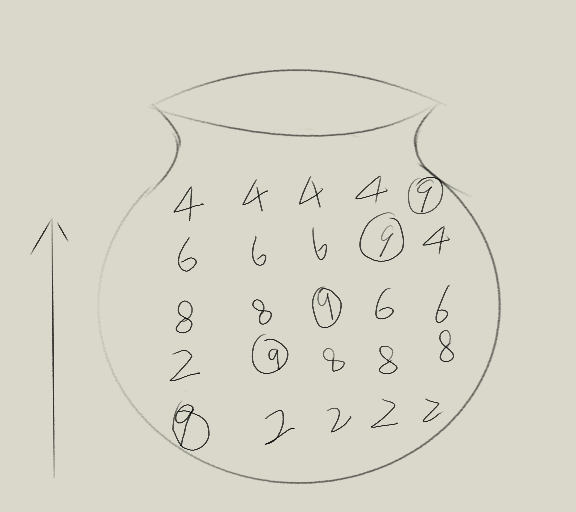
Step1:第一次比较第一和第二个数字,9与2相比较,9比2大,顺序不对,则交换位置。
Step2:第二次比较第二与第三个数字,因为9换到了第二位,则9与8比较,9大,顺序不对,则交换位置。
Step3:以此类推,最后9就像泡泡一样升到了最后一位,我们称这样为一趟,这一趟里面有多次比较。
综上所述:
由于一趟只归为一个数,则如果有n个数字,则需要进行n-1趟。
因为归位后的数字不用再比较了,所以每趟只需要比较n-1-i次(i为已执行的趟数)。
由上可以得出冒泡排序的关键步骤是两个循环:
for(i = 0; i < n-1; i++){
for(j = 0; j < n-1-i; j++)
if(a[j] > a[j+1]){
temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}python实现:
根据上述思路,用python实现也是把关键地方实现即可:
#假设变量已经全部定义好
for i in range(len-1):
for j in range(len-1-i):
if a[j] > a[j+1]:
a[j], a[j+1] = a[j+1], a[j]以下是完整代码:
#!/usr/bin/env python
# -*- coding:utf8 -*-
'''
简介:本程序主要是用python实现冒泡排序,程序的功能是实现
降序排列。
作者:leedom 日期:2018/08/19 版本1
'''
class BubbleSort(object):
'''
self.datas: 要排序的数据列表
self.datas_len: 数据集的长度
_sort(): 排序函数
show(): 输出结果函数
用法:
BubbleSort(datas) 实例化一个排序对象
BubbleSort(datas)._sort() 开始排序,由于排序直接操作
self.datas, 所以排序结果也
保存在self.datas中
BubbleSort(datas).show() 输出结果
'''
def __init__(self, datas):
self.datas = datas
self.datas_len = len(datas)
def _sort(self):
#冒泡排序要排序n个数,由于每遍历一趟只排好一个数字,
#则需要遍历n-1趟,所以最外层循环是要循环n-1次,而
#每次趟遍历中需要比较每归位的数字,则要在n-1次比较
#中减去已排好的i位数字,则第二层循环要遍历是n-1-i次
for i in range(self.datas_len-1):
for j in range(self.datas_len-1-i):
if(self.datas[j] < self.datas[j + 1]):
self.datas[j], self.datas[j+1] = \
self.datas[j+1], self.datas[j]
def show(self):
print('Result is:'),
for i in self.datas:
print(i,end='')
if __name__ == '__main__':
try:
datas = raw_input('Please input some number:')
datas = datas.split()
datas = [int(datas[i]) for i in range(len(datas))]
except Exception:
pass
bls = BubbleSort(datas)
bls._sort()
bls.show()时间复杂度
1.如果我们的数据正序,只需要走一趟即可完成排序。所需的比较次数C和记录移动次数M均达到最小值,即:Cmin=n-1;Mmin=0;所以,冒泡排序最好的时间复杂度为O(n)。
2.如果很不幸我们的数据是反序的,则需要进行n-1趟排序。每趟排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:冒泡排序的最坏时间复杂度为:O(n2) 。

综上所述:冒泡排序总的平均时间复杂度为:O(n2) 。
空间复杂度
空间复杂度是运行完一个程序所需要的内存的大小。这里包括了存储算法本身所需要的空间,输入与输出数据所占空间,以及一些临时变量(比如上面的i,j)所占用的空间。一般而言,我们只比较额外空间,来比较算法的空间优越性。
冒泡排序的临时变量所占空间不随处理数据n的大小改变而改变,则空间复杂度为O(1)。
总结:
冒泡排序因为是在原数组上直接操作,所以它占的空间资源较少,在数据量不大的情况还是挺好的。但是由于算法涉及双重循环,所以在数据量大的情况下,程序运行的时间是相当长的,因为要一次一次地遍历数据。
最后。非常感谢博客园中的King_DIG,链接:https://www.cnblogs.com/king-ding/p/bubblesort.html