游戏项目需要全球同服,做分布式架构。数据库需要分库,在使用 Mycat 中间件时,需要一个插入全局唯一id的问题,测试代码如下:
import pymysql
import datetime
import random
import socket
import time
con = pymysql.connect(host = "127.0.0.1", port = 8066, user = "root", passwd = "123456")
local_ip = socket.gethostbyname(socket.gethostname())
cur_mycat = con.cursor()
cur_mycat.execute("use endlessworld_db")
insert_test_str = "insert into `tb_test` (id,username) values(%s,%s)"
num_list = list(range(1, 1000))
random.shuffle(num_list)
def insert_record():
for i in num_list:
str_i = str(i)
#cur_mycat.execute("select next value for MYCATSEQ_GLOBAL")
#next_id = cur_mycat.fetchall()[0][0]
explain = cur_mycat.execute(insert_test_str, ("next value for MYCATSEQ_GLOBAL", "robot" + str_i))
con_1 = pymysql.connect(host = "127.0.0.1", port = 3306, user = "root", passwd = "123456")
cur_1 = con_1.cursor()
cur_1.execute("use endlessworld_1")
con_2 = pymysql.connect(host = "127.0.0.1", port = 3306, user = "root", passwd = "123456")
cur_2 = con_2.cursor()
cur_2.execute("use endlessworld_2")
con_3 = pymysql.connect(host = "127.0.0.1", port = 3306, user = "root", passwd = "123456")
cur_3 = con_3.cursor()
cur_3.execute("use endlessworld_3")
def query_test():
cur_1.execute("select * from tb_test")
record_result_1 = cur_1.fetchall()
record_list_1 = [i[0] for i in record_result_1]
cur_2.execute("select * from tb_test")
record_result_2 = cur_2.fetchall()
record_list_2 = [i[0] for i in record_result_2]
cur_3.execute("select * from tb_test")
record_result_3 = cur_3.fetchall()
record_list_3 = [i[0] for i in record_result_3]
print(len(record_list_1), len(record_list_2), len(record_list_3))
record_list = record_list_1 + record_list_2 + record_list_3
#print(len(record_list))
not_count = 0
for player_id in record_list:
cur_mycat.execute("select * from tb_test where id = %s",(player_id))
user_result = cur_mycat.fetchall()
if not user_result:
#print(player_id)
not_count += 1
print(not_count)
start = time.time()
insert_record()
end = time.time()
print("total insert cost time ", end - start)
query_test()
采用的分库方式为按照 id 作一致性哈希 schema.xml 中分库表的配置:
<table name="tb_test" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur" />测试的结果如下:
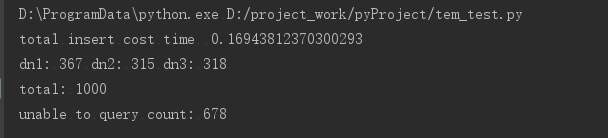
通过mycat插入1000 条记录,全部插入成功,可以在各个分库中都查询到,大致也是平衡均匀的。然后通过 mycat 查询时,发现大部分记录都不能通过mycat查询到。
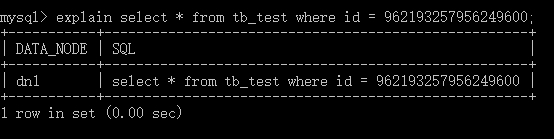
在命令行使用 explain 查询插入的一条记录,发现这条插叙记录被路由到分库dn1上。
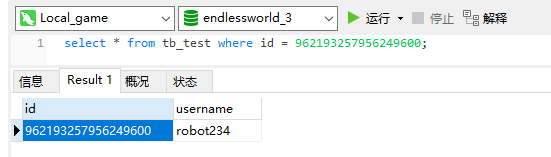
而实际该条记录被插入到了 dn3 中
修改插入的代码,即放开注释,更改获取下一个全局唯一id的方式
cur_mycat.execute("select next value for MYCATSEQ_GLOBAL")
next_id = cur_mycat.fetchall()[0][0]
explain = cur_mycat.execute(insert_test_str, (next_id, "robot" + str_i))再插入一百万条记录:

可以看到这回一百万条记录插入之后,也能通过mycat正常的查询到。所以问题就在全局唯一id的地方,需要先获取该id,整数表达的id才行。