$ 参数估计 | 极大似然估计
1 参数估计的问题提出
极大似然估计:找出与 样本的分布 最接近的 概率分布模型。最大似然估计是利用已知的样本的结果,在使用某个模型的基础上,反推最有可能导致这样结果的模型参数值。
问题:假设有两点分布的抛硬币游戏,每次抛完为正面向上的概率为
θ ,则重复10次实验的得到的结果(即样本)为:+ + - + + + - + - +。
那么可得到如此结果的概率式为:
L(θ)=θ7(1−θ)3 能够看到这样的事件发生,我们就认为背后的这套概率模型机制发生的概率最大。于是求如上的概率公式
L(θ) 的最大值(转化为对数然后对θ 求导)。
2 极大似然估计
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)对参数求导,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
3 为什么要有 EM ?
但是当概率模型含有隐变量时,就没有办法直接使用极大似然估计方法,从而提出能够求解隐变量的 EM 算法。
参考文献:https://www.jianshu.com/p/1121509ac1dc

后面在GMM模型中也会再次说明。
$ 凸优化 | Jensen 不等式
1 凸函数定义
给定映射
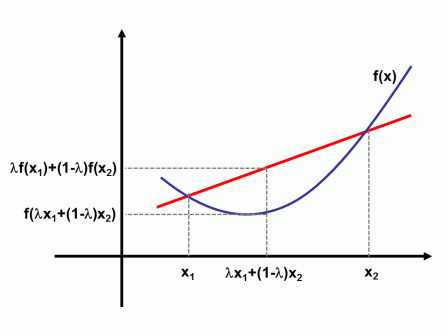
f:Rn→R ,如果dom f⊆Rn 为凸集,并且对于任意x,y∈dom f 和任意0≤t≤1 ,满足
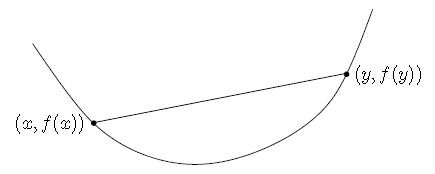
f(tx+(1−t)y)≤tf(x)+(1−t)f(y)
则称函数是凸的。
如下图所示,凸函数特点: 弦在弧上!
2 Jensen 不等式
Th1:如果
f 是 凸函数 ,X 是随机变量,则:
f(E(X))⩽E(f(X))
特别地,如果f 是 严格凸函数,那么f(E(X))=E(f(X)) 当且仅当X 是常量,即p(x=E(X))=1 。
Th2:若
f 是 凹函数,则:
f(E(X))≥E(f(X))
严格凸:对于任意
x≠y ,且0<t<1 ,有
f(tx+(1−t)y)<tf(x)+(1−t)f(y)
$ EM算法 | GMM模型
1 EM算法的要点
简介:
…………………………………………………………………………………………
《数学之美》的作者吴军将EM算法称为上帝的算法,EM算法也是公认的机器学习十大经典算法之一。
…………………………………………………………………………………………
EM是一种求解参数极大似然估计的迭代算法,具有良好的收敛性和每次迭代都能使似然函数值单调不减的优良性质。
…………………………………………………………………………………………
在统计学习、NLP 等领域应用非常广泛,许多统计学算法都是 EM 算法的体现,如隐马尔科夫模型的训练方法 Baum-Welch 算法、最大熵模型的训练方法 GIS 算法、高斯混合模型 EM 算法、主题模型训练推理的 pLSA 方法,都属于 EM 算法。甚至连聚类中的 k-means 算法其实也是EM方法的体现。
上面的简介在我看来就是激发一下兴趣,不过本质就是废话!接下来我们看几个要点,理解算法的灵魂核心。 在我看来,EM算法就是条件概率的一场游戏。
要点 1 :隐变量的华丽登场
似然估计的概率公式为
L(θ) ,其中yi 是样本数据(观测值),公式中可能会有 隐变量z ,公式变为p(y,z) 。公式可以根据强行分离出隐变量
z 的形式:联合分布再积分。
取对数:要注意 隐含变量其实是
z(i) 。
对于每一个样例
yi ,令Qi 表示该样例隐变量z 的某种分布。
Qi 满足的条件是∑z(i)Qi(z(i))=1,Qi(z(i))>0 。
要点 2 :Jensen不等式的应用
log 是 凹函数。因此有
log(E(X))≥E(log(X))
X 可以替换为下面的表达式:
p(y,z|θ)Qi
要点 3 :探索最紧的下界
特别地如果
f(E(X))=E(f(X)) 当且仅当X 是常量,即
p(y,z|θ)Qi=c
c 是 constant ,则有
ℓ(θ)=∑ilog∑zQip(y,z|θ)Qi=∑i∑zQilogp(y,z|θ)Qi
Qi 满足的条件是∑z(i)Qi(z(i))=1,Qi(z(i))>0 。
要点 4 :EM 算法框架
初始化分布参数θ ; 重复E、M步骤直到收敛:E 步:根据参数
θ 初始值或上一次迭代所得参数值来计算出隐变量的后验概率(即隐性变量的期望),作为隐性变量的现估计值:
Qi(z(i))=p(z(i)|yi,θ)
M 步:将似然函数最大化以获得新的参数值θ :
θ=argmaxθ∑i∑zQilogp(y,z|θ)Qi
2 GMM模型
问题 1 :高斯分布
随机挑选10000名志愿者,测量身高。
志愿者中分男性和女性:男性身高分布服从
在样本中未知样本属于男性还是女性,即打乱样本的情况下,参数估计
如果将两个二维高斯分布
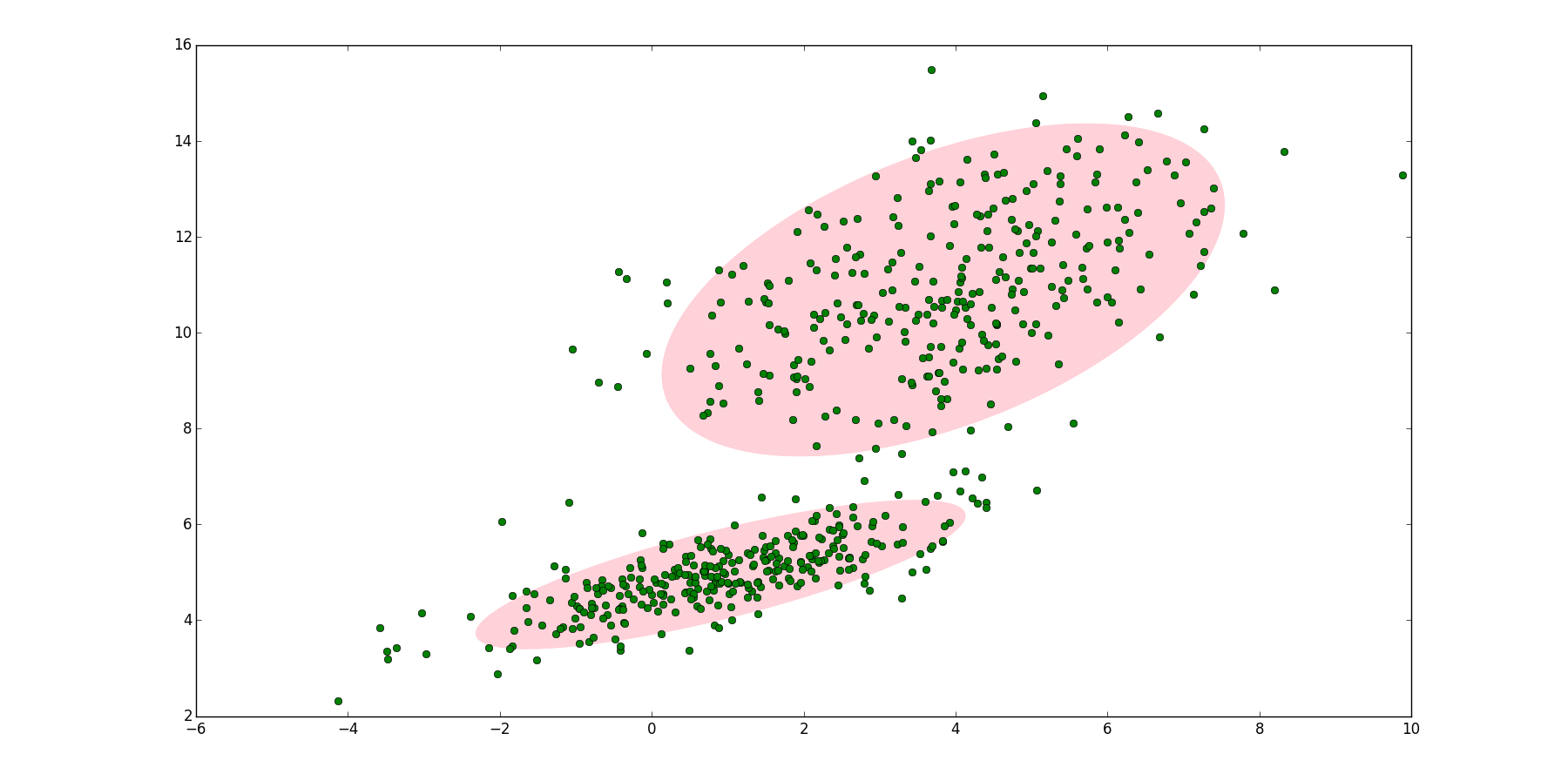
参考文献:http://blog.csdn.net/jinping_shi/article/details/59613054
问题 2 :GMM 的参数
GMM模型中有三个参数需要估计,分别是
参考文献:http://blog.csdn.net/u012151283/article/details/77649924
假设数据服从
从数据集求出这
通过 EM 算法,我们可以迭代计算出GMM中的参数:
参考文献:http://blog.csdn.net/junshen1314/article/details/50300421
问题 3 :GMM 的 EM 应用
- step 1:定义分量数目
K ,对每个分量k 设置πk,μk,Σk 的初始值,然后计算对数似然函数:
p(xi|π,μ,Σ)=∑k=1KπkN(xi|μk,Σk)
log∏ip(xi|π,μ,Σ)=∑ilogp(xi|π,μ,Σ)
- E step:根据当前的
πk,μk,Σk 计算后验概率,即期望γ(n,k) :
γ(n,k)=πkN(xn|μn,Σn)∑Kj=1πjN(xn|μj,Σj)
γ(n,k) 可以认为是第n 个样本来自第k 个分布的概率。
- M step:根据 E step 中计算的
γ(n,k) 再计算新的πk,μk,Σk :
μnewkΣnewkπnewk=1Nk∑n=1Nγ(n,k)xn=1Nk∑n=1Nγ(n,k)(xn−μnewk)(xn−μnewk)T=NkN
其中的Nk=∑Nn=1γ(n,k)
- step 4:计算对数似然函数:
logp(x|π,μ,Σ)=∑n=1Nlog{∑k=1KπkN(xk|μk,Σk)} - step 5:检查参数是否收敛或对数似然函数是否收敛,若不收敛,则返回第 2 步。
以上关于 GMM 的参数估计推导可以类比 EM 推导。