经过研究,发现网页统计浏览量主要是根据ip地址和cookie中的缓存,并且网站都会做防刷,
它会判断url的来源,如:
来源URL:Request.UrlReferrer
浏览器类型:Request.UserAgent
远程客户端的DNS:Request.UserHostName
所以用httpclient去访问页面时,还要把userAgent修改一下,当然紧紧是修改userAgent是不行的,浏览器访问网页得到html,需要解析:
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none - 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
- js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本禁止使用document.write(),它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
所以简单获取到html,只能称为简单的爬虫,例如博客园网站,计算浏览量方法不是一个url请求就能算浏览,还需要把html解析得到的url请求完。
解决这个问题,想到两个方法:
(1)写个批处理,先设置浏览器的代理服务器,再自动启动浏览器,然后在关闭 浏览器。
(2)将通过httpclient 爬到的html,解析,将所有资源都访问一遍。
先说第一种方法:
批处理如下,让Runtime这个类去执行:
cd \
C:
cd Users\jsonzb\AppData\Local\Google\Chrome\Application
chrome "https://www.cnblogs.com/fangxiaoneng/p/8302407.html"
执行批处理文件:Runtime.getRuntime().exec("Chrome.bat")
关闭浏览器:Runtime.getRuntime().exec("taskkill /f /im chrome.exe") 浏览器对同域名连接有最大限制,而http1.1的connection都是keep—alive
代理设置用com.alibaba.b2b.qa.browsers.compare.Browser这个类完成
经过测试可行,
测试过程:
1.我的chrome.bat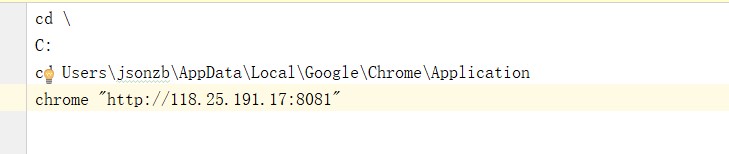
2.执行chrome
3.自动弹出浏览器访问url
4.结果:我的浏览器ip是,183.208.20.54,而模拟服务器最后得到的是代理服务器的ip,说明这种方式可以
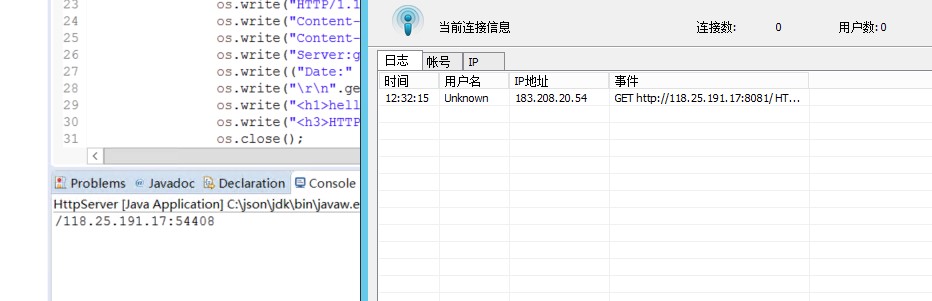
第二种方法等我刷出浏览量再发