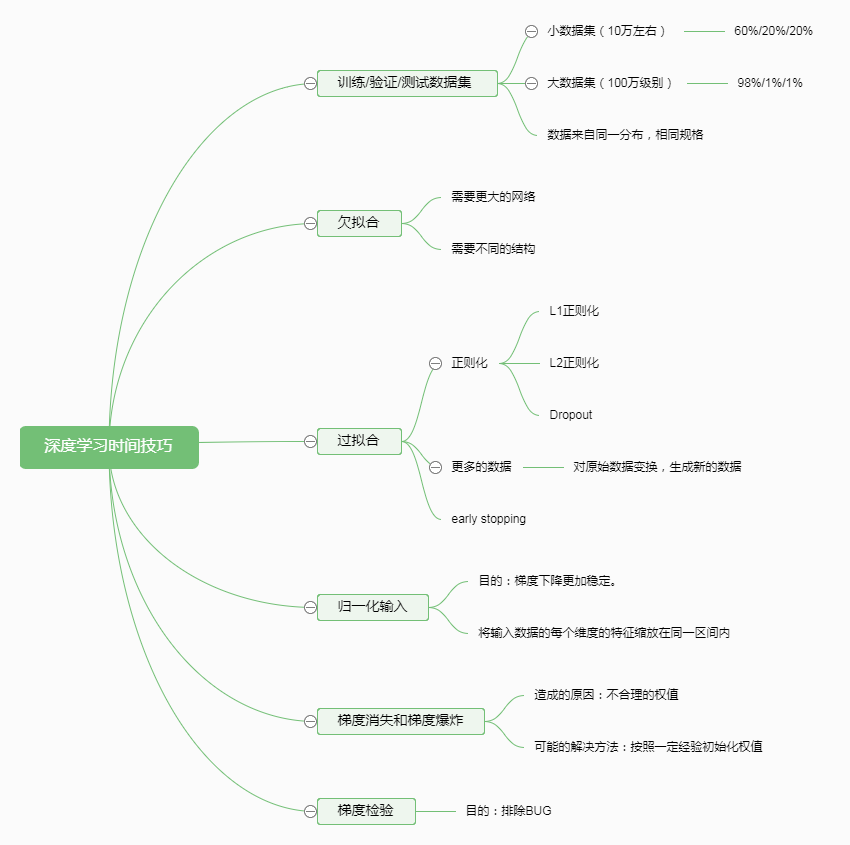
一、思维导图
二、正则化
正则化是一个较好的方法去解决神经网络的过拟合问题。
我的理解是:如果一个神经网络出现过拟合,那么说明这个神经网络既拟合了输入数据中的特征部分,也拟合了输入数据的噪声部分。当神经网络处于过拟合,那么神经网络拟合的函数就非常复杂。那么非常复杂的函数就需要更多的神经元,更深的神经网网络才能表示。那么,现在有两个思路来解决过拟合问题(不要让神经网络太复杂),1是降低每个神经元的输出。使得神经元不要那么活跃,那么实际上就是降低权值,这个思路就是L1,L2正则化。2。直接删除神经元,让网络更加简单。这个思路就是Dropout的思路。
$$\begin{array}{l}Costfunction:J({w^{[l]}},{b^{[l]}}) = \frac{1}{m}\sum\limits_{i = 1}^m {L({{\widehat y}^{(i)}} - {y^{(i)}}) +\frac{\lambda }{{2m}}\sum\limits_{l = 1}^L {\left\| {{w^{[l]}}} \right\|_2^2} } \\L2:\left\| {{w^{[l]}}} \right\|_2^2 = \sum\limits_{j = 1}^{nx} {w_j^2} \\L1:{\left\| {{w^{[l]}}} \right\|_1} = \sum\limits_{j = 1}^{nx} {\left| {{w_j}} \right|} \end{array}$$
从上式中可以看出,是使得权值和尽量小,那么权值的和要小,那么尽量让权值小。其中的lamda也是一个超参数。
Dropout:
给每个隐层设定一个概率,来随机删除一些隐神经元。删除之后,为了保证每个隐层的输出均值不变,每个隐层的隐元输出需要进行适当补偿。
三、权值初始化的经验方法
对于ReLU激活函数,隐层l的权值设定为均值为0,方差为2/n的高斯随机数较好。(其中n为隐层l的输入,也就是隐层l-1的神经元个数).你也可以给方差2/n乘上一个系数,作为一个超参数。