上一篇文章讲了kafka的默认的分区器(DefaultPartitioner)源码,这里我们写一个自定义分区器的小例子
生产者代码如下:
/**
* kafka生产者
* 使用自定义的分片器发送消息
*/
public class PartitionerProducer {
public static final String TOPIC_NAME = "producer-0";
private static Properties props = new Properties();
static{
props.put("bootstrap.servers", "192.168.1.3:9092,192.168.1.128:9092,192.168.1.130:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//自定义分区器
props.put("partitioner.class", "com.yang.kafka.partitioner.MyPartitioner");
}
public static void main(String[] args) {
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(TOPIC_NAME, Integer.toString(i),Integer.toString(i+3000)));
producer.close();
}
}分区器代码如下:
/**
* 自定义分区器
*/
public class MyPartitioner implements Partitioner{
@Override
public void configure(Map<String, ?> configs) {}
@Override
public int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {
if(key == null)
return 0;
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if(availablePartitions == null || availablePartitions.size() <= 0)
return 0;
int partitionKey = Integer.parseInt((String)key);
int partitionSize = availablePartitions.size();
return availablePartitions.get(partitionKey % partitionSize).partition();
}
@Override
public void close() {}
}我自定义的分区器很简单,由于我的key为数字,而且是累加的,所以我很轻松的就可以通过取余来实现分区。
消费者代码如下:
public class PartitionerConsumer {
private static Properties props = new Properties();
private static boolean isClose = false;
static{
props.put("bootstrap.servers", "192.168.1.3:9092,192.168.1.128:9092,192.168.1.130:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
}
public static void main(String args[]){
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(PartitionerProducer.TOPIC_NAME));
while (!isClose) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("partition = %d offset = %d, key = %s, value = %s%n",record.partition(), record.offset(), record.key(), record.value());
}
consumer.close();
}
}消费者收到的消息为:
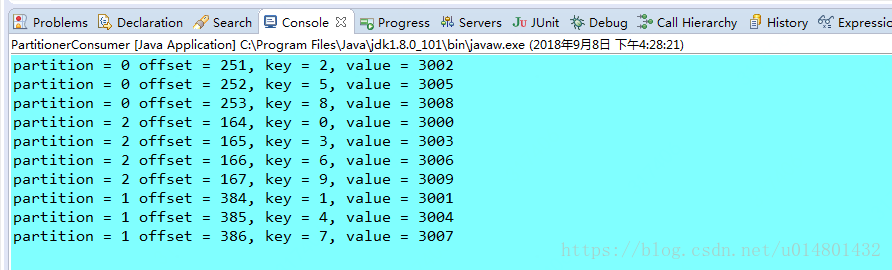
一般情况下我们很少去自定义分区器,因为使用默认分区器可以实现更好的负载均衡,当然特定的场合下除外。