数据处理
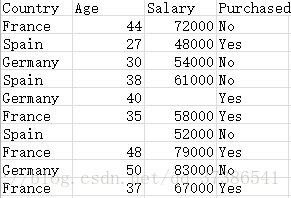
一.导入数据集
import pandas as pd
dataset = pd.read_csv('Data.csv') #数据集通常为csv格式
X = dataset.iloc[ : , :-1].values #自变量矩阵
Y = dataset.iloc[ : , 3].values #因变量向量
first_rows = dataset.head()X:
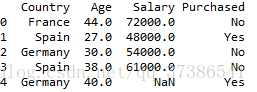
Y:

1. read_csv()函数:读取csv文件,路径为相对路径
2.head( m )函数:读取前m条数据,如果没有参数m,默认读取前五条数据,例如:
3. dataset. iloc[0] —— 获取第一行数据 dataset.iloc[0]['Age']——获取第一行的Age值
dataset.iloc[0:2,0:2]—— 获取前两行前两列数据
Pandas详解:https://blog.csdn.net/qq_34941023/article/details/53317805
二.处理缺失数据
from sklearn.preprocessing import Imputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
imputer = Imputer(missing_values = "NaN",strategy = "mean",axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : ,1:3] = imputer.transform(X[ : ,1:3])1. sklearn.preprocessing 预处理:整体上表现在三个方面:(1):是对数据集上的X进行数据转换处理;(2):是对数据集上Y进行标签处理;(3):对缺失值的处理
preprocessing详解:https://blog.csdn.net/axing6502724/article/details/57406186
2. Imputer类提供了一些基本的方法来处理缺失值,如使用均值、中位值或者缺失值所在列中频繁出现的值来替换。
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
参数说明:
missing_values —— 缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
strategy—— 替换策略,字符串,默认用均值‘mean’替换
①若为mean时,用特征列的均值替换
②若为median时,用特征列的中位数替换
③若为most_frequent时,用特征列的众数替换
axis:指定轴数,默认axis=0代表列,axis=1代表行
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,默认为True
用Imputer填充数字方法有两种,先fit,然后transform,或者直接fit_transform
参考:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Imputer.html
http://www.xue63.com/toutiaojy/20180116G0YZNW00.html
三.编码分类数据
分类数据 (Categorical Data) 里的变量,不包含数值,只包含分类标签。比如,是/否(本文数据的分类标签),性别,婚姻状态。这样的变量,是没办法当成数值直接运算的。所以,才需要把它们编码成能够运算的数值。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
#创建虚拟变量
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)fit_transform() onehotencoder.fit_transform(X),只对第一个特征onehot编码

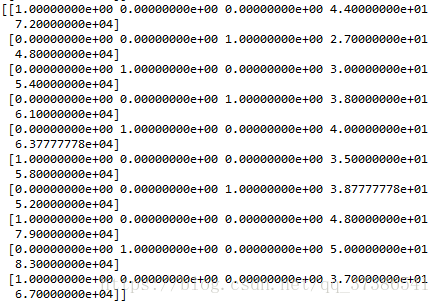

1. LableEncoder: 可以将各种标签分配一个可数的连续编号 le = LableEncoder()
le.fit() —— 得到标签种类 ,给定顺序 le.classes_ —— 查看标签种类
le.transform() —— 返回每个数据对应的序号 inverse_transform —— 反向编码
fit_transform是fit和transform的组合
参考:https://blog.csdn.net/kancy110/article/details/75043202
2. OneHotEncoder :将表示分类的数据扩维
格式:OneHotEncoder(n_values=’auto’,categorical_features=’all’,dtype=<class‘numpy.float64’>,sparse=True, handle_unknown=’error’)
参数说明:n_values=’auto’ —— 表示每个特征使用几维的数值由数据集自动推断,即几种类别就使用几位来表示
categorical_features = 'all',这个参数指定了对哪些特征进行编码,默认对所有类别都进行编码。也可以自己指定选择哪些特征,通过索引或者 bool 值来指定
dtype=<class ‘numpy.float64’> 表示编码数值格式,默认是浮点型。
sparse=True 表示编码的格式,默认为 True,即为稀疏的格式,指定 False 则就不用 toarray() 了
handle_unknown=’error’,其值可以指定为 "error" 或者 "ignore",即如果碰到未知的类别,是返回一个错误还是忽略它
3. 方法 transform(X) 就是对 X 进行编码
参考:https://www.cnblogs.com/zhoukui/p/9159909.html
https://blog.csdn.net/lanchunhui/article/details/72794317
四.分开训练集和测试集
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)


train_test_split()格式:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
参数说明: train_data:所要划分的样本特征集 train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量 random_state:是随机数的种子(不太懂)
五.特征缩放
大部分机器学习算法,都会拿两个数据点之间的欧几里得距离 (Euclidean Distance) 做计算。这样一来,如果一个特征比其他特征的范围值更大,这个特征值就会成为主导。而我们希望其他特征,也得到同等的重视,所以用特征标准化 (Feature Standardization) 来解决这个问题。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
StandardScaler