版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013818406/article/details/73658504
1. CTR预估算法现状及进展
之前也看过CTR预估算法,大部分都是LR、FM、FFM、GBDT互相堆叠,在现实中看到还有先利用LR做多维embedding,然后再加上图像CNN特征再做LR。LR主要的难点是特征离散化后特征维度特别高,实习时看到的分布式最多支持1E多特征,实际使用特征维度大概也接近1E。LR缺陷是没有计算特征之间互相影响的部分,FM将特征交互加入了计算中,FFM再将同一特征离散出来的特征带上Field的概念,我之前的博客中也转载过美团的FFM算法,有兴趣的可以看下。GBDT的话就不用多说了,并没有针对CTR的改进就是使用的原版。
2. MLR具体算法
首先直观的根据公式感受一下,公式非常简单,很快就能感受到创造者的思路
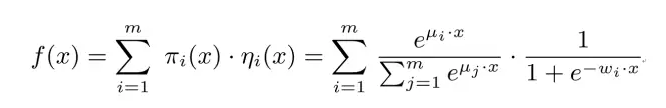
直观来说,左边是一个softmax类似的分类器,右边是一个标准二分的LR分类器,不知道大家直观的感受是什么,我看完后感觉就是这个算法是先对特征做了个主题分析判断,然后再在各个主题中建立LR,这样的模型表达能力也就是VC维肯定是比LR要高的,比较像是级联了两个分类器。
举个栗子,假如我的特征由我购买过的所有商品组成,每个商品拥有不同的主题分类,加入有3种商品,我购买了10次1类商品,20次2类商品,20次3类商品(假设商品不加权,而且这个假设比较极端,每个商品只有一个主题),那么我的特征经过前面这个分类器很可能就训练成(0.2,0.4,0.4),后米这部分计算的是商品具体的吸引力,因为我假设商品主题只有一个的缘故,假设这次计算商品时第2类的,所以后面这部分很可能是(0,0.5,0),最终CTR=0.2*0+0.4*0.5+0.4*0=0.2,CTR跟我对这类商品的需求以及这个具体商品的吸引力成正比。
这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。因此实际应用中m需要根据实际情况进行选择。例如,在我们的场景中,m一般选择为12。下图中MLR模型用4个分片可以完美地拟合出数据中的菱形分类面。
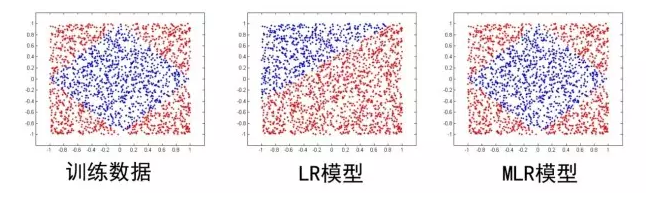
这个样本MLR能够分开的原因也是因为首先做了一个分类,将这个矩阵对折两次,分成左上左下右上右下四个部分,每个部分的数据分布都是可以用简单的线性分类器直接分开的,公式的前半部分做的就是类似对折分开的工作。
综合谈一下MLR的优点,这优点是文章自己总结的,我直接拿过来了:1.结构先验(在之前的栗子中已经比较清楚了);2.线性偏置,这个东西如果看过SVD推荐的就会比较了解,简单来说就是根据矩阵分解到的值预测用户属性和商品属性的均值再加上各自的偏好,能够细化模型更准确的预测,其实就是根据实际情况进行微调
3.模型级联,这个优点其实LR自身就有,加上我觉得MLR在某种程度上也是两个分类器的级联,其实这个优点就可以忽略不计了;4.增量训练,这个就是将已有的模型参数来进行初始化然后再在新的样本上训练,互联网公司都这样首先必须保证不降低当前的精度才能上线,不然上线就算是事故了。。。
3. 大规模分布式实现
原文里感觉说了和没说差不多啊。。。首先分布式的构架区别是每一个分布式节点都构架的server和worker两种角色,这个没有细节说明也不知道具体区别,要是只将server和worker建立在每一个分布式节点上,我去改下configure文件就能做到了,不知道具体指的充分利用每个节点的CPU和内存在哪做到的。
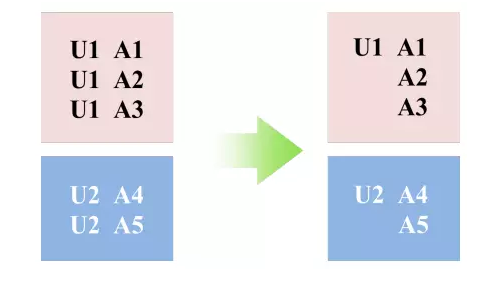
第二部分的tricks,引用原文(此外,针对个性化广告场景中数据的结构化特性,我们提出并实现了common feature的trick,可以大幅度压缩样本存储、加速模型训练。例如下图示意,在展示广告中,一般来说一个用户在一天之内会看到多条广告展现,而一天之内这个用户的大量的静态特征(如年龄、性别、昨天以前的历史行为)是相同的,通过common feature压缩,我们对这些样本只需要存储一次用户的静态特征,其余样本通过索引与其关联;在训练过程中这部分特征也只需要计算一次。在实践中应用common feature trick使得我们用近1/3的资源消耗获得了12倍的加速。)
(看完之后总的来说感觉没有比较有新意的东西比较像是包装了级联分类,也可能是我太菜,不喜勿喷)