版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/meiqi0538/article/details/82558000
本文测试使用Pandas使用的是Spyder,python3.6版本,已经安装好pandas包。测试数据已放云盘:链接:https://pan.baidu.com/s/1zozpY2BUTIvEJKf238leZg 密码:44zg。如需按照numpy,可以百度搜索如何安装。
1数据标准化
将数据按比例缩放,使之落入到特定区间,一般我们使用0-1标准化。公式如下:
#导包
import pandas;
from pandas import read_csv
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data13.csv")
scale=(df.score-df.score.min())/(df.score.max()-df.score.min())数据计算前后对比
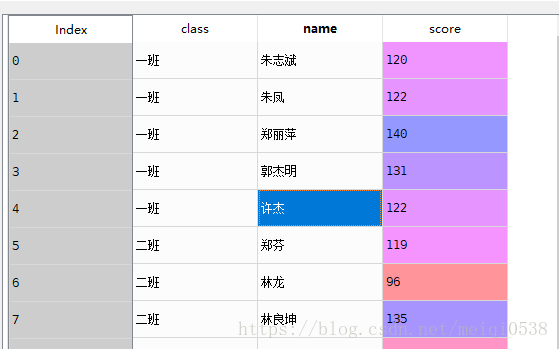
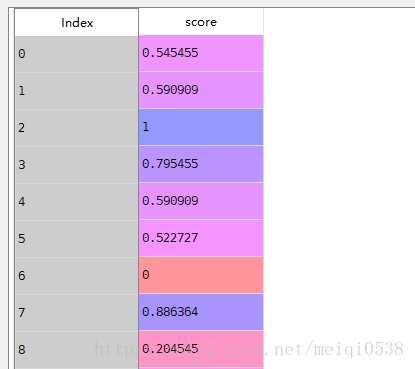
2 数据分组
根据数据分析对象的特征,按照一定数值指标,把数据分析对象划分为不同的区间部分来进行研究,以揭示其内在的联系和规律性。这里我们可以使用cut函数,cut(series,bins,right=True,labels=NULL),其中:
series:需要分组的数据
bins:分组的划分数组
right:分组的时候,右边是否闭合
labels:分组的自定义标签,可以不自定义
#导包
import pandas;
from pandas import read_csv
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data14.csv",sep="|")
bins=[min(df.cost)-1,20,40,60,80,100,max(df.cost)+1]
labels=['20以下','20到40','40到60','60到80','80到100','100以上']
result=pandas.cut(df.cost,bins=bins,right=False,labels=labels)数据处理前后对比:
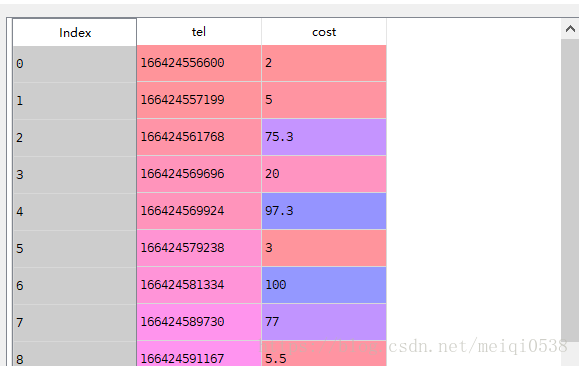
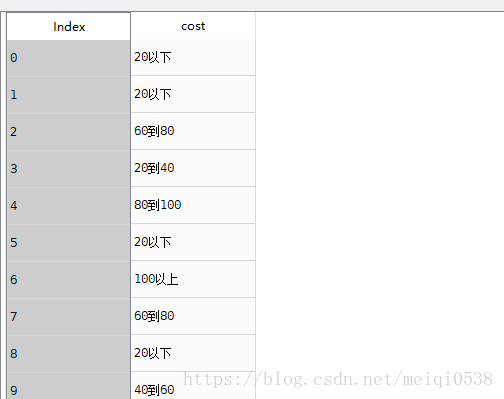
将对应的数据进行了标注。
3 日期转换
将字符型的日期格式的数据,转换成日期型数据的过程,使用date=to_datetime(dateString,format)
| 属性 | 注释 |
|---|---|
| %Y | 代表年份 |
| %m | 代表月份 |
| %d | 代表日期 |
| %H | 代表小时 |
| %M | 代表分钟 |
| %S | 代表秒 |
#导包
from pandas import read_csv
from pandas import to_datetime
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data15.csv",encoding='utf8')
df_dt=to_datetime(df.注册时间,format="%Y/%m/%d")数据处理前后对照
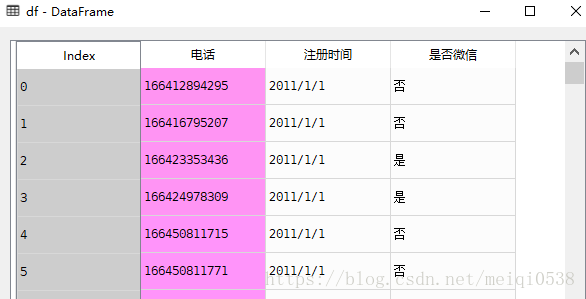
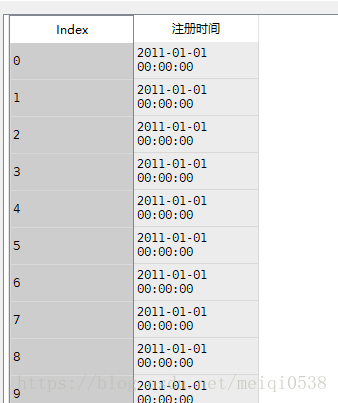
4日期格式化
将日期型的数据,按照给定的格式,转为字符型的数据。日期格式化函数:apply(lambda x:处理逻辑),datetime.strftime(x,format) ,这里的format与时间转化相同。
#导包
from pandas import read_csv
from pandas import to_datetime
from datetime import datetime
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data16.csv",encoding='utf8')
df_dt=to_datetime(df.注册时间,format="%Y/%m/%d")
df_dt_str=df_dt.apply(lambda x: datetime.strftime(x,"%d-%m-%Y"))时间转换前后对比
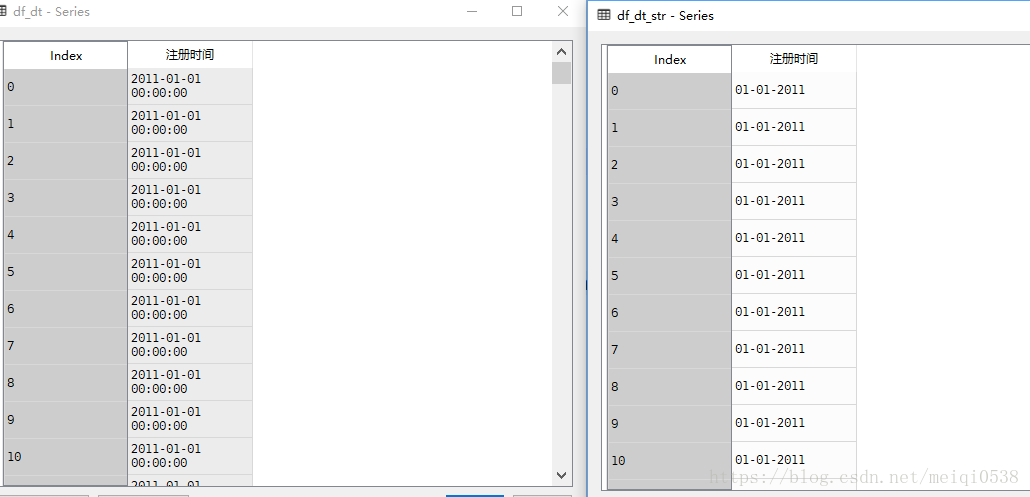
5日期抽取
从日期格式里,抽取出需要的部分属性。使用的发函数:datetime列.dt.property
| 属性 | 注释 |
|---|---|
| second | 1-60:秒,从1开始,到60 |
| minute | 1-60:分钟,从1开始,到60 |
| hour | 1-24:小时,从1开始,到24 |
| day | 1-31:一个月中的第几天,从1开始,最大31 |
| month | 1-12:月份,从1开始,到12 |
| year | 年份 |
| weekday | 1-7:一周中的第几天,从1开始,最大为7 |
#导包
from pandas import read_csv
from pandas import to_datetime
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data17.csv",encoding='utf8')
df_dt=to_datetime(df.注册时间,format="%Y/%m/%d")
s_y=df_dt.dt.year
s_s=df_dt.dt.second
s_m=df_dt.dt.minute
s_h=df_dt.dt.hour
s_d=df_dt.dt.day
s_M=df_dt.dt.month
s_w=df_dt.dt.weekday原始数据,转换数据对比


