本文翻译自http://mxnet.incubator.apache.org/architecture/note_engine.html
深度学习的依赖引擎
我们总是希望深度学习库能够更快地运行并扩展到更大的数据集。一个自然的方法是看看我们是否可以从更多的硬件上解决问题,比如同时使用多个GPU。
依赖调度
虽然大多数用户想要利用并行计算的优势,但是我们中的大多数人更熟悉串行程序。因此,一个自然的问题是:我们如何编写串行程序并建立一个库,以异步方式自动并行化程序?
举个例子,在下面的运算中,我们可以以任意顺序运行B=A+1和C=A+2,或者并行运行:
A = 2 B = A + 1 C = A + 2 D = B * C
但是手动编码顺序比较困难,因为最后一步操作需要等待前两个操作完成才能开始。下面的依赖图/数据流图说明了这一点:
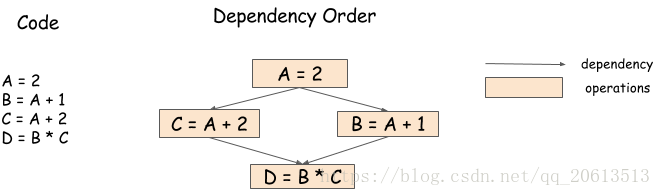
所以诞生了依赖引擎库,该库接受一系列操作并根据依赖模式对它们进行调度,潜在的进行并行运行。因此,在这个示例中,依赖库可以并行的运行B=A+1和C=A+1,在这些操作完成之后,再运行D=B*C;
依赖调度中存在的一些问题
依赖引擎减轻了编写并行程序的负担。然而,随着操作变得并行化,出现了新的依赖跟踪问题。在这一节中,我们将讨论这些问题。
数据流依赖
数据流依赖性描述了一个计算的结果是如何在其他计算中使用的。每个依赖引擎都必须解决数据流依赖性问题。
因为我们在前面的部分讨论了这个问题,我们在这里包含了相同的数字。拥有数据流跟踪引擎的库包括Minerva和Purine2。
内存回收
分配给数组的内存什么时候应该被回收?在串行计算中,这一点非常容易。可以在变量超出范围之后再进行内存回收,但是,正如下图所示,这在并行处理中比较困难。
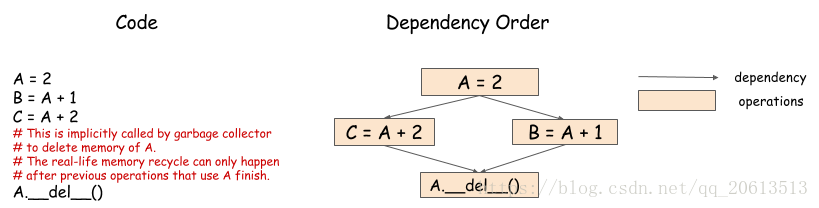
在这个计算中,因为B和C的计算都要使用A的值,所以必须在B和C的计算完成之后才能回收A的内存。引擎必须根据依赖关系才能调度内存回收的操作,并且确保操作是在B和C的计算完成之后进行。
随机数的产生
机器学习中通常会使用随机数生成器,这对依赖引擎提出了有趣的挑战。下面的例子:
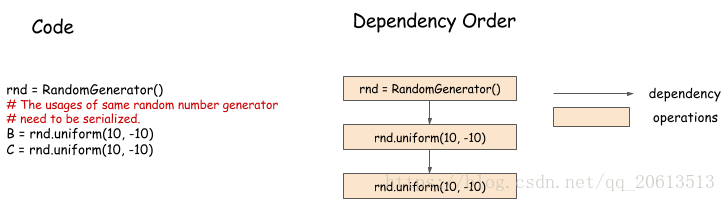
在这个例子中,我们以排队生成的方式生成随机数,虽然这两个随机数的产生貌似可以并行化进行,但是通常情况下不是并行的。伪随机数生成器(PRNG)不是线程安全的,因为他可能导致一些内部状态在生成新的数字时发生突变。即使PRNG是线程安全的,也最好是串行生成随机数,这样我们就可以得到reproducible 的随机数。
案例分析:多GPU神经网络的依赖引擎
在最后一节中,我们讨论了在设计依赖引擎时可能会遇到的问题。我们先考虑一个依赖引擎如何帮助神经网络的多GPU训练。下面的伪代码python程序描述了一个两层神经网络训练一个batch:
# Example of one iteration Two GPU neural Net data = next_batch() data[gpu0].copyfrom(data[0:50]) data[gpu1].copyfrom(data[50:100]) # forward, backprop on GPU 0 fc1[gpu0] = FullcForward(data[gpu0], fc1_weight[gpu0]) fc2[gpu0] = FullcForward(fc1[gpu0], fc2_weight[gpu0]) fc2_ograd[gpu0] = LossGrad(fc2[gpu0], label[0:50]) fc1_ograd[gpu0], fc2_wgrad[gpu0] = FullcBackward(fc2_ograd[gpu0] , fc2_weight[gpu0]) _, fc1_wgrad[gpu0] = FullcBackward(fc1_ograd[gpu0] , fc1_weight[gpu0]) # forward, backprop on GPU 1 fc1[gpu1] = FullcForward(data[gpu1], fc1_weight[gpu1]) fc2[gpu1] = FullcForward(fc1[gpu1], fc2_weight[gpu1]) fc2_ograd[gpu1] = LossGrad(fc2[gpu1], label[50:100]) fc1_ograd[gpu1], fc2_wgrad[gpu1] = FullcBackward(fc2_ograd[gpu1] , fc2_weight[gpu1]) _, fc1_wgrad[gpu1] = FullcBackward(fc1_ograd[gpu1] , fc1_weight[gpu1]) # aggregate gradient and update fc1_wgrad[cpu] = fc1_wgrad[gpu0] + fc1_wgrad[gpu1] fc2_wgrad[cpu] = fc2_wgrad[gpu0] + fc2_wgrad[gpu1] fc1_weight[cpu] -= lr * fc1_wgrad[cpu] fc2_weight[cpu] -= lr * fc2_wgrad[cpu] fc1_weight[cpu].copyto(fc1_weight[gpu0] , fc1_weight[gpu1]) fc2_weight[cpu].copyto(fc2_weight[gpu0] , fc2_weight[gpu1])
在这个程序中:
数字0~50被复制到GPU0,50~100被复制到GPU1。计算之后,梯度聚集在CPU上,然后执行简单的SGD更新,并将更新后的权重复制回每个GPU。这里使用的是串行的方式,下面的依赖图显示了它可以如何并行化:
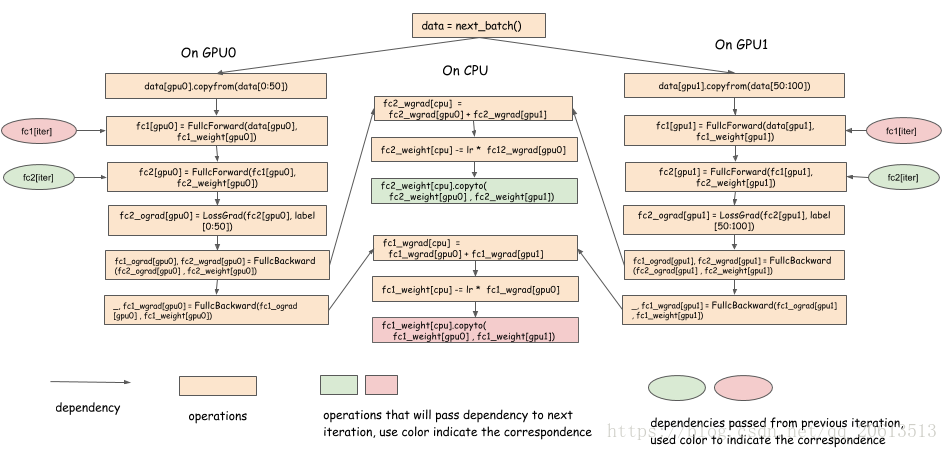
注意:
- 当某一layer上的梯度被计算出来时,就可以立刻被复制到CPU上;
- 当权重被计算出来时,可以立马复制回GPU上;
- 在前向过程中,在前次的迭代中的计算:fc1_weight[cpu].copyto(fc1_weight[gpu0] , fc1_weight[gpu1]),是前向过程的依赖项
- 在反向传播到层k,以及下一次前向过程到层k之间,存在一个延迟,我们可以在延迟期间,并行的将层k的权重和其他计算同步。
这种优化方法被很多深度学习库使用,如CXXNET。重点是将权重同步(通信)与计算重叠。然而,这样做并不容易,因为copy操作要在该层的反向传播完成后就触发,然后触发reduction和update等工作。
依赖引擎可以调度这些操作并执行多线程和依赖跟踪。
设计一个泛型依赖引擎
依赖引擎对于多设备的分布式深度学习是非常实用的。现在介绍如何实现依赖引擎的通用接口。这个方法不是只针对某一个问题的解决方案,而是大多数情况下都会有效的解决方案。
我们的目标是常见一个通用的、轻量级的依赖引擎。理想情况下,我们希望依赖引擎可以很容易的运用到现有的深度学习代码中去,并且可以很容易的扩展到多台机器(少量修改)。我们需要关注依赖跟踪,而不是取决于用户的操作。
下面是引擎的目标:
- 引擎不应该受他正在执行的操作的影响,这样用户就可以执行它们定义的任何操作
- 它不可以被它所执行的对象类型所限制
- 我们应该可以安排GPU和CPU内存的依赖关系
- 我们应该能够跟踪随机数生成器等的依赖关系
- 引擎不应该分配资源,他应该只跟踪相关性。用户可以分配自己的内存、PRNG等。
下面的Python代码提供了一个引擎接口,可以帮助我们达到我们的目标。真正的实现情况一般在C++中。
class DepEngine(object): def new_variable(): """Return a new variable tag Returns ------- vtag : Variable Tag The token of the engine to represent dependencies. """ pass def push(exec_func, read_vars, mutate_vars): """Push the operation to the engine. Parameters ---------- exec_func : callable The real operation to be performed. read_vars : list of Variable Tags The list of variables this operation will read from. mutate_vars : list of Variable Tags The list of variables this operation will mutate. """ pass
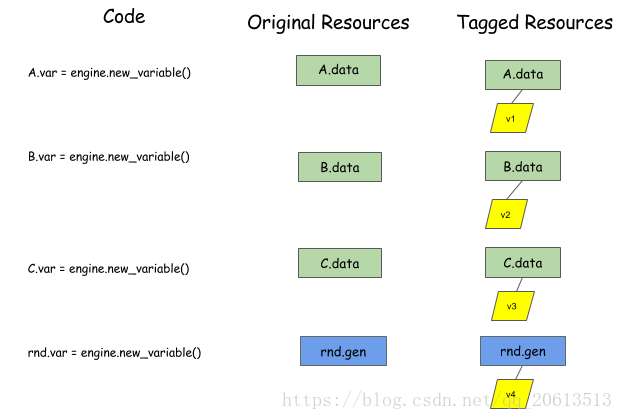
然后用户调用push来告诉引擎有关要执行的功能。用户还需要使用read_vars和write_vars指定操作的依赖关系:
- read_vars是操作将会读取的对象参数标签,读取时不会改变其内部状态
- write_vars是操作将会改变其内部状态的对象的参数标签
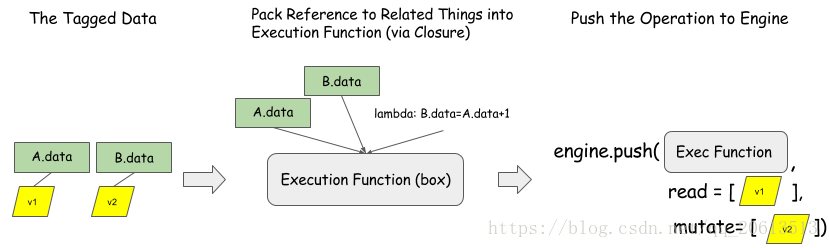
前面的图显示了如何将操作 B = A + 1 推到依赖引擎。 B.data 和 A.data 是分配的空间。注意,引擎只知道变量标签。任何处理函数都可以被处理。这个接口对于我们要调度的操作和资源来说是通用的。
有趣的是,让我们看看引擎内部如何通过标签来考虑以下代码片段:
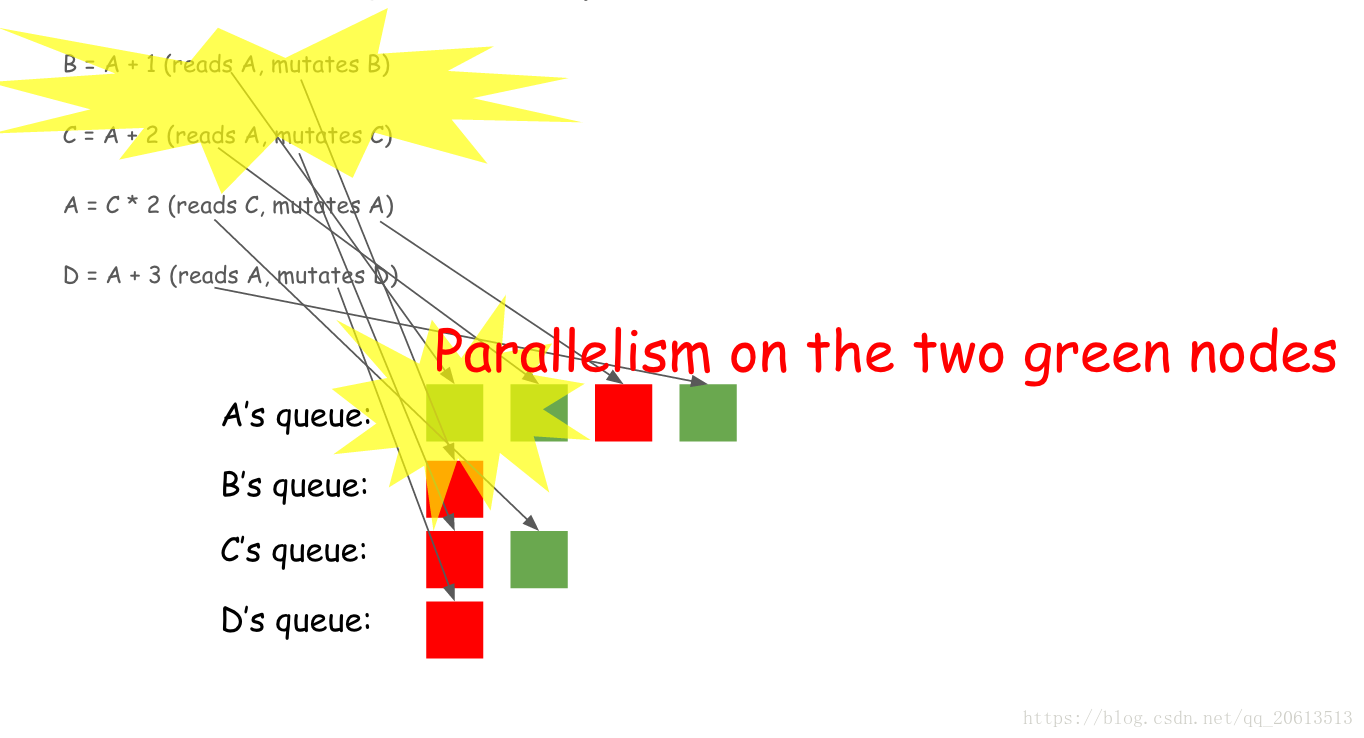
B = A + 1 C = A + 2 A = C * 2 D = A + 3
引擎为每个变量维护一个队列,下面的动画显示了四行中的每一行。绿色块表示读取动作,而红色块表示改变。

在构建这个队列时,引擎会看到队列的前两个绿色块实际上可以并行运行,因为它们都是读取动作,不会相互冲突。下面的图表说明了这一点。

将现有代码移植到依赖引擎
因为泛型接口不能控制内存分配和执行哪些操作,所以大多数现有代码可以由依赖性引擎分两步进行调度:
- 分配与资源相关联的变量标签,如内存BLB、PRNGs。
- 在原始代码被执行时,调用push()函数来执行原始代码的执行代码,并将相应资源的参数标记正确放置在
read_varsandmutate_vars中
实现泛型依赖引擎
我们已经描述了通用引擎接口,以及它如何被用来调度各种操作。在本节中,我们进一步提供了如何实现这样一个引擎的讨论。
大致做法如下:
- 使用队列跟踪每个变量标签上的所有挂起的依赖项。
- 在每个操作上使用计数器来跟踪有多少依赖性尚未完成。
- 当操作完成时,更新队列和依赖计数器的状态以安排新操作。
下图说明了调度算法,它可以让你更好地了解引擎中正在发生的事情。
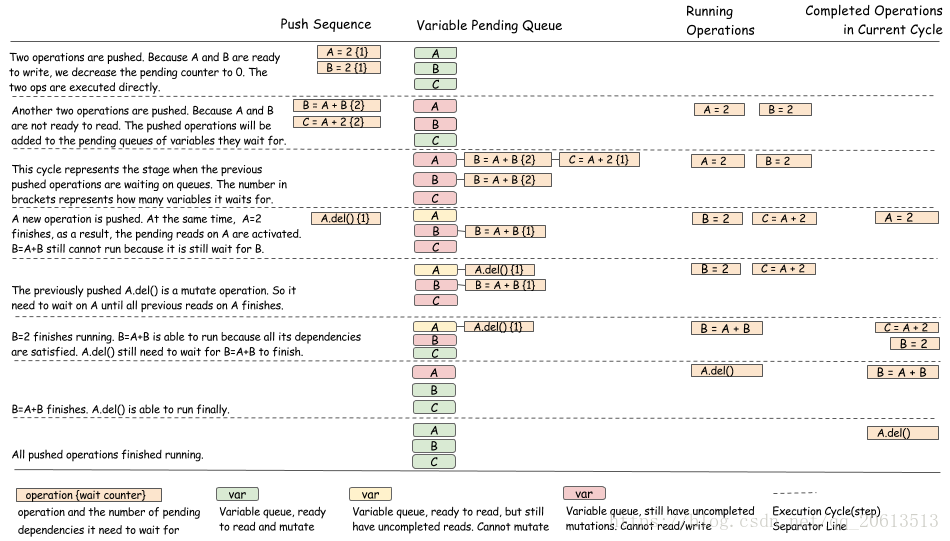
下面,我们展示另一个涉及随机数发生器的例子。
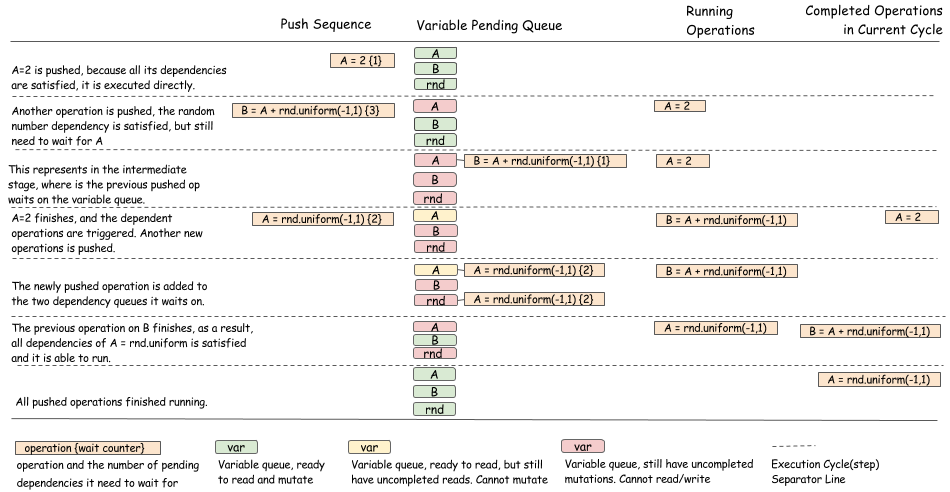
正如你所看到的,算法的目的是更新操作的等待队列,并在操作完成时进行正确的状态转换。必须严谨地确保状态转换是以线程安全(threadsave)的方式完成的。
使用运行策略的独立依赖跟踪
如果您仔细阅读,您可能已经注意到,前面的部分仅显示用于决定何时可以执行操作的算法。我们没有显示如何实际运行一个操作。在实践中,可以有许多不同的方法。例如,我们可以使用全局线程池来运行所有操作,或者使用特定的线程在每个设备上运行操作。
此运行策略通常独立于依赖跟踪,并且可以分离为独立的模块或基础依赖跟踪模块的虚拟接口。开发一个对所有操作和调度公平的简洁的运行时策略本身就是一个有趣的系统问题。
讨论
我们在本文中讨论的设计并不是解决依赖跟踪问题的唯一方案。这只是我们如何解决这一点的一个例子。当然,有些设计选择是有争议的。我们将在本节中讨论其中的一些问题。
动态与静态
本主题中讨论的依赖引擎接口在某种程度上是动态的,用户可以逐个推操作,而不是声明整个依赖图(static)。动态调度可能需要比静态声明更多的开销,就数据结构而言。然而,它也能提供更多的灵活性,比如支持命令式程序的自动并行性,或者强制和符号程序的混合。您还可以向接口添加一些预声明操作,以实现数据结构重用。
可变与不变
本页中呈现的通用引擎接口支持突变的显式调度。在典型的数据流引擎中,数据通常是不可变的。使用不可变的数据有很多好处。例如,不可变数据通常更适合并行化,并且在分布式设置(通过重新计算的方式)中有助于更好的容错性。
然而,不可变性提出了几个挑战:
- 在处理随机数和删除时,很难调度资源争用问题。
- 引擎通常需要管理资源(内存、随机数)以避免冲突。更难插入用户分配的空间等。
- 重新分配预分配的静态内存是不可用的,因为通常的模式是写入预先分配的层空间,如果数据是不可变的,则不支持该层空间。
mutable减轻了这些问题。