test表中的原始数据:
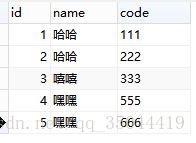
test表中name字段信息有重复,想进行过滤删除重复数据
删除重复数据之后的预期结果(不考虑id):
方法一:
用 create ......select......group by ......
先创建临时表tab,新表tab中的数据时从test表中分组查询出来的
create table tab select name ,code from test group by name
拷贝原test的表结构为新表test1。然后删除原表test。
drop table test
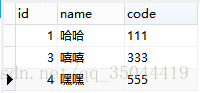
然后查看tab表:
此时tab表中的信息已经删除了重复信息(只考虑name字段的重复性)
但是你会发现tab表中没有id,我们需要加上id,所以就将tab表中的数据插入test1中。
用 insert into ......select ......的方法
执行:insert into test1 select null,name,code from tab;
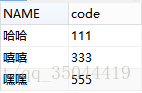
执行后查看test1表中的信息:

达到去删除重复数据的效果。
最后将表test1改名为test就可以了
alter table test1 rename to test
备注:insert into test1 select null,name,code from tab;
利用mysql主键自增的特性,所以后面的select语句给id赋值为null即可。
方法二:
删除重复数据,保留重复数据中最小id所在行的数据
delete from test
where
name in (select pname from (select name as pname from test group by name having count(name) > 1) a)
and
id not in (select pid from (select min(id) as pid from test group by name having count(name) > 1 ) b)
注意where 后面的两个条件:
前者是查询name字段有重复值 且count >1的name值,后者是name字段有重复且count>1数据的最小id
执行上面语句后结果:
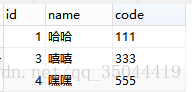
达到去重的目的,只是id不是连续的。
此方法有一误区,错误sql语句展示如下:
delete from test
where
name in (select name as pname from test group by name having count(name) > 1)
and
id not in (select min(id) as pid from test group by name having count(name) > 1 )
以上sql语句看似正确,执行后报错。
错误信息:[Err] 1093 - You can't specify target table 'test' for update in FROM clause