DATA: BEGIN OF wa_pa0001,
pernr LIKE pa0001-pernr,
uname LIKE pa0001-uname,
bukrs LIKE pa0001-bukrs,
plans LIKE pa0001-plans,
END OF wa_pa0001.
DATA: itab_pa0001 LIKE TABLE OF wa_pa0001 WITH HEADER LINE.
SORT itab_pa0001 BY pernr.
DELETE ADJACENT DUPLICATES FROM itab_pa0001.
2,在ABAP开发中,有时要进行一个耗费时间的处理,这时不想让客户感到处理出现问题或者以为是电脑死机,给出一个提示,“请等待的...”,可以使用下面语句:
CALL FUNCATION SAPGUI_PROGRESS_INDICATOR
EXPORTING
text = 数据处理中,请等待....
进行耗费时间处理
3, 在ABAP开发中,有时我们做的程序界面是不需要全部必选的,例如:
SELECTION-SCREEN BEGIN OF BLOCK blk WITH FRAME TITLETEXT-001.
METERS: p_werks LIKE mseg-werks. 物料凭证-工厂
METERS: p_lgort LIKE mseg-lgort OBLIGATORY. 物料凭证-库存地点
SELECT-OPTION: s_mblnr FOR mseg-mblnr. 物料凭证-编号
SELECTION-SCREEN END OF blk.
在选在屏幕中p_lgort 是必选;s_mblnr 是一个范围,在OPEN-SQL中可以使用IN查询范围,若s_mblnr没有数据时,取全部,有数据时取符合条件的数据;p_werks为一个数据值,在写SQL语句时,我们要根据条件进行SQL拼加。在这我们可以通过SELECT-OPTION做一个操作,通过如下语句SELECT-OPTION: s_werks FOR mseg-werks NO-EXTENSION NOINTERVALS.可以去掉SELECT-OPTION的区间选项、后缀选项,但有个问题是不能去掉=、<=、<、>、>=选择。
|
要求:结构zstructure还有两个字段,分别为结构名称NAME、是否处理字段FLAG(0,代表处理;1,代表没有处理)。这个结构的内表可能含有同一名称NAME的多条信息,要求只保留一条信息,即某名称的处理信息全部为0,就只保留一条;若某名称的处理信息有为“未处理”的,只保留一条未处理信息。 如: Name Flag a 0 a 0 b 0 b 1 需要的结果为: Name Flag a 0 b 1 处理如下: sort l_it_structure by name ascending flag descending. delete adjacent duplicates from l_it_sturcture comparing name.
解释: (1) sort <table> by <field> 功能:按照给定字段对内表排序 (2) delete adjacent duplicates from <table> comparing <field> 功能:删除数据后面,与他临近的指定相同自动的数据记录。
|
本次介绍SORT的一些知识点和容易出错的地方。
正文:
1、SORT中ASCENDING|DESCENDING的位置
如下例:
SORT itab_cdpos DESCENDING BY objectid udate utime .
和
SORT itab_cdpos BY objectid udate utime DESCENDING .
是不同的,升降序指示在BY在前面,表示后面的字段都用这个升降序,作用范围是后面BY所有的字段;如果指示符是在BY的后面,则只是对这个指示符前面的字段起作用,其他的字段还是默认的方式排序。
2、在二分法搜索之前要先排序
READ TABLE itab WITH KEY name = it_source BINARY SEARCH.
像这样的语句,如果在执行前没有对itab进行排序,出来的结果可能就会说错误的。
正确的写法应该是先排序再READ:
SORT itab BY name .
READ TABLE itab WITH KEY name = it_source BINARY SEARCH.
注:二分法搜出来的数据是第一条符合条件的数据。
3、内表的删重语句执行前要排序
DELETE ADJACENT DUPLICATES 。。。
这个是根据指定字段删除重复的内表数据的,在使用前也要先针对指定的字段进行排序,否则结果也是错误的。
注:删除重复数据,保留第一条。
4、如果内表列多行也多,排序会使用大量内存空间
有可能会导致内存不够用,是一个风险点。
5、根据指定的序列对内表排序
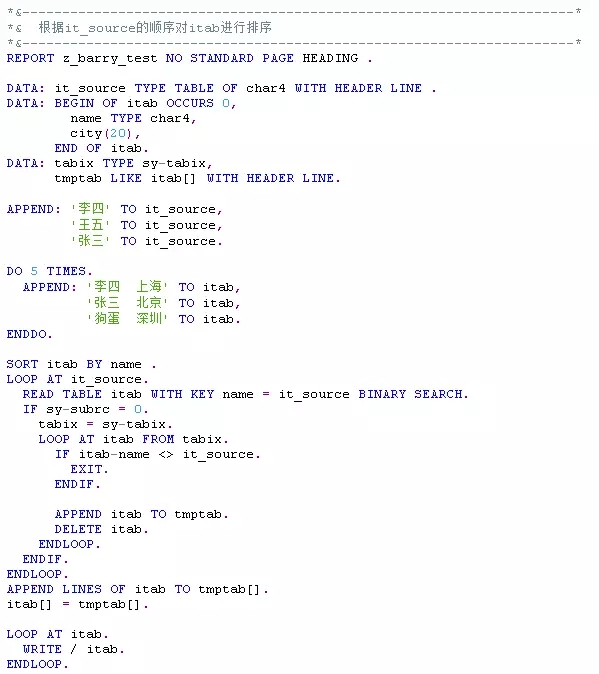
6、稳定排序
按照指定序列对内表排序后,如果还要按照更高级别的字段排序,请使用稳定排序法,语法为:SORT itabSTABLE BY...
7、动态指定字段排序
SORT itab BY (comp1)...(compn) .
或者:
SORT itab BY (otab).
otab是一个内表,结构是ABAP_SORTORDER。