流程图
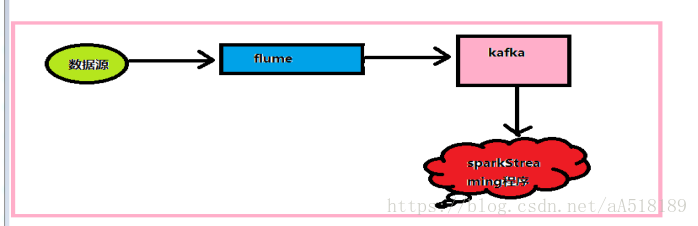
采集方案
#agentsection producer.sources= s1 producer.channels= c1 producer.sinks= k1 #配置数据源 producer.sources.s1.type=exec #配置需要监控的日志输出文件或目录 producer.sources.s1.command=tail -F -n+1 /root/a.log
#配置数据通道 producer.channels.c1.type=memory producer.channels.c1.capacity=10000 producer.channels.c1.transactionCapacity=100
#配置数据源输出 #设置Kafka接收器,此处最坑,注意版本,此处为Flume 1.6.0的输出槽类型 producer.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink #设置Kafka的broker地址和端口号 producer.sinks.k1.brokerList=192.168.204.10:9092 #设置Kafka的Topic producer.sinks.k1.topic=test #设置序列化方式 producer.sinks.k1.serializer.class=kafka.serializer.StringEncoder #将三者级联 producer.sources.s1.channels=c1 |
启动kafka和zk和flume
创建消费者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
启动flume
bin/flume-ng agent -n producer -c conf -f conf/myconf.conf -Dflume.root.logger=INFO,console
向flume采集的目标文件发送数据:
While true;do echo "我爱你" >> a.log ;sleep 0.5 done;
sparkstreaming消费数据:
package spark_kafka import org.apache.spark.streaming._ import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe object Kafka_consumer { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("kafka_wordcount").setMaster("local[*]") val ssc = new StreamingContext(conf,Seconds(2)) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "wangzhihua1:9092,wangzhihua2:9092,wangzhua3:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "use_a_separate_group_id_for_each_stream", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) val messages: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](Array("test"), kafkaParams) ) val rs: DStream[(String, Int)] = messages.map(t => { (t.value(), 1) }) val fianlRs= rs.reduceByKey(_+_) fianlRs.print() ssc.start() ssc.awaitTermination() } }