1. Kafka概述
1.1. 什么是Kafka
Apache Kafka是分布式发布-订阅消息系统(消息中间件)。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
简单说明什么是Kafka:
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”Kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是Kafka的扩容。Kafka就是例子中的"篮子"。
传统消息中间件服务RabbitMQ、Apache ActiveMQ等。
Apache Kafka与传统消息系统相比,有以下不同:
l 它是分布式系统,易于向外扩展;
l 它同时为发布和订阅提供高吞吐量;
l 它支持多订阅者,当失败时能自动平衡消费者;
l 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
1.2. Kafka术语
术语 |
解释 |
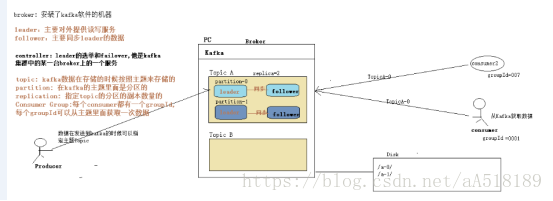
Broker |
Kafka集群包含一个或多个服务器,这种服务器被称为broker |
Topic
|
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) |
Partition |
Partition是物理上的概念,每个Topic包含一个或多个Partition. |
Producer |
负责发布消息到Kafka broker |
Consumer |
消息消费者,向Kafka broker读取消息的客户端 |
Consumer Group |
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group) |
replica |
partition 的副本,保障 partition 的高可用 |
leader |
replica 中的一个角色, producer 和 consumer 只跟 leader 交互 |
follower |
replica 中的一个角色,从 leader 中复制数据 |
controller |
Kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover |
小白理解:
Ø producer:生产者,就是它来生产“鸡蛋”的。
Ø consumer:消费者,生出的“鸡蛋”它来消费。
Ø topic:把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的“鸡蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃”了。
Ø broker:就是篮子了。
如果从技术角度,topic标签实际就是队列,生产者把所有“鸡蛋(消息)”都放到对应的队列里了,消费者到指定的队列里取。
副本一般不会和leader在同一个机器上
不同的leader的一般不再同一台机器上,这样同一台太忙,效率低
1.3. Kafka集群结构图
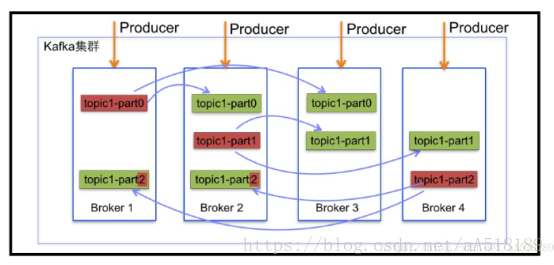
1.4 Kafka细节说明
Ø 细节一:kafka的主体分区中,数据是从后向前追加的。
Ø 细节二: 每一个Consumer都有一个group id 一个group id 只能从主体中消费一次数据,仅仅一次。就是consumers是消息系统的流出接口,多个consumers逻辑上组成consumer Group。CG的目标是实现同一需求的消费吞吐量。同一个topic的message,只能被同一CG的一个Consumer消费;但可以被不同多个CG消费;
Ø 细节三:未来负载均衡,一般不同的leader不在同一台机器上。不然同一台机器压力太大。
Ø 细节四:副本一般不会和leader在一台机器上,方式宕机带来的数据丢失。
Kafka功能概述
1.1.1. 首先有几个概念:
· Kafka作为一个集群运行在一台或多台可以跨越多个数据中心的服务器上。
· 卡夫卡集群在称为主题的类别中存储记录流。
· 每个记录由一个键,一个值和一个时间戳组成。
1.1.2. 卡夫卡有四个核心API:
· 制片API允许应用程序发布的记录流至一个或多个卡夫卡的话题。
· 消费者API允许应用程序订阅一个或多个主题,并处理所产生的对他们记录的数据流。
· 流API允许应用程序充当流处理器,从一个或多个主题消耗的输入流,并产生一个输出流至一个或多个输出的主题,有效地变换所述输入流,以输出流。
· 连接器API允许构建和运行卡夫卡主题连接到现有的应用程序或数据系统中重用生产者或消费者。例如,连接到关系数据库的连接器可能会捕获对表的每个更改。
1.1.3. 生产者API
Producer API允许应用程序将数据流发送到Kafka集群中的主题。
展示如何使用生产者的示例在javadoc中给出 。
要使用生产者,你可以使用下面的maven依赖关系:
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency>
|
1.1.4. 消费者API
Consumer API允许应用程序从Kafka集群中的主题读取数据流。
展示如何使用消费者的示例在javadoc中给出 。
要使用消费者,您可以使用以下maven依赖项:
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency>
|
1.1.5. Streams API
该流 API允许将来自输入主题数据流输出的主题。
展示如何使用这个库的例子在javadoc中给出
有关使用Streams API的其他文档可在此处获得。
要使用Kafka Streams,您可以使用以下maven依赖项:
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>1.1.0</version> </dependency>
|
1.1.6. 连接API
Connect API允许实现连续性连接器,这些连接器可以连续地从某些源数据系统提取到Kafka或从Kafka推送到某些接收器数据系统。
Connect的许多用户不需要直接使用此API,但他们可以使用预建连接器而无需编写任何代码。有关使用Connect的更多信息,请点击这里。
那些想要实现自定义连接器的人可以看到javadoc。
1.1.7. AdminClient API
AdminClient API支持管理和检查主题,代理,acl和其他Kafka对象。
要使用AdminClient API,请添加以下Maven依赖项:
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency>
|
生产者与消费者
学会利用官网学习
相关参数说明:
Spark streaming的参数配置
conf.setMaster("local[*]")
conf.setAppName("spark streaming直连整合kafka")
每秒钟每个分区kafka拉取消息的速率
conf.set("spark.streaming.kafka.maxRatePerPartition", "5")
程序优雅的关闭
conf.set("spark.streaming.stopGracefullyOnShutdown", "true")
Kafka的参数配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "kk-01:9092,kk-02:9092,kk-03:9092",
"key.deserializer" -> classOf[StringDeserializer], // 类.class.getName
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
// 不记录消费的偏移量信息 true 记录
"enable.auto.commit" -> (false: java.lang.Boolean) )
"auto.offset.reset"参数设置
Kafka单独写consumer时
可选参数:
earliest:自动将偏移重置为最早的偏移量
latest:自动将偏移量重置为最新的偏移量(默认)
none:如果consumer group没有发现先前的偏移量,则向consumer抛出异常。
其他的参数:向consumer抛出异常(无效参数)
参考:
http://kafka.apache.org/documentation/
和SparkStreaming整合时:
注意:和SparkStreaming整合时,上面的可选参数是无效的,只有两个可选参数:
smallest:简单理解为从头开始消费,其实等价于上面的 earliest
largest:简单理解为从最新的开始消费,其实等价于上面的 latest
屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
Kafka源码中的Producer Record定义
1. ProducerRecord<K, V> 含义:
发送给Kafka Broker的key/value 值对
原码:
public final class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final K key;
private final V value; }
2.内部数据结构:
-- Topic (名字)
-- PartitionID ( 可选)
-- Key[( 可选 )
-- Value
3.生产者记录(简称PR)的发送逻辑:
<1> 若指定Partition ID,则PR被发送至指定Partition
<2> 若未指定Partition ID,但指定了Key, PR会按照hasy(key)发送至对应Partition
<3> 若既未指定Partition ID也没指定Key,PR会按照round-robin模式发送到每个Partition
<4> 若同时指定了Partition ID和Key, PR只会发送到指定的Partition (Key不起作用,代码逻辑决定)
4.生产者记录(PR)的实现:
针对3,提供三种构造函数形参:
-- ProducerRecord(topic, partition, key, value)
-- ProducerRecord(topic, key, value)
-- ProducerRecord(topic, value)
生产者与消费者实例
生产者
代码核心:
第一步:使用一个map去封装一个kafka生产者 的信息,然后创建一个生产者
val producer = new KafkaProducer[String, String](props)
第二步:根据自己的需求创建一个消息对象,然后由生产者发送到kafka中去
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
package spark_kafka
val producer = new KafkaProducer[String, String](props) |
消费者
import org.apache.spark.streaming._ |