第七天 - HDFS概述、命令操作 - JAVA操作HDFS - 集群间时间同步、手动修复
一、HDFS概述
HDFS概述
hdfs源于Google的GFS论文,是GFS的克隆版译为易于扩展的分布式文件系统,可以运行在大量的普通廉价机器上。hadoop,离线计算框架,数据很少会发生变化。当数据发生变化时,通过操作hdfs的方式进行数据同步,在hadoop中提供数据存储服务,具备数据管理功能/数据不丢失(冗余存储)。
hadoop进行数据运算时是以分布式的方式进行:任务分发 -> 资源调配 -> 结果同步,所以在对小数据量的处理时,从主观来看会感觉使用分布式计算反而比单机计算更慢,这是因为时间花费在了任务分发、结果同步上,;然而,当数据量足够大时,就能体现出分布式计算的优势了。
hdfs可以使得在数据计算时,数据的读取变得高效,提高计算的效率,同时可以作为多个数据计算框架数据存储支持,例如hive、hbase等。
HDFS优缺点
- 优点
- 高可靠性:存储和处理数据的能力
- 高扩展性:可以在可用的计算机集群间分配数据来完成计算任务,并可以扩展到数以千计的节点中
- 高效性:能够在各个节点之间动态移动数据,保证各个节点的动态平衡以提升速度
- 高容错性:能够自动保存数据的多个副本,并能够将失败的任务重新分配
- 缺点
- 不适合低延迟的数据访问
- 无法高效存储大量的小文件
- 不支持多用户写入及修改文件
HDFS核心思想及作用
- 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,可以快速高效的对海量数据进行运算分析
- 可以为各类的分布式运算框架(MapReduce,Spark等)提供数据存储服务
- 本质上是一个分布式文件系统,用于存储和管理文件,由多台服务器联合起来实现分布式的功能,在每个服务器上可以负责不同的工作内容
如果一个集群中有100台节点:40台做数据存储,60台做数据运算
40台用于数据存储提升数据稳定性,例如使用商用固态硬盘/弹性块存储等高性能存储设备
60台应用于数据运算,需要提升提升CPU、内存性能
这100台节点都需要保证足够的带宽,否则带宽将会是这个集群分布式计算的瓶颈
重要特性
- HDFS在物理上是分块存储,块的大小可以通过配置文件来指定,在2.x版本中是128M
- HDFS文件系统会给客户端提供一个统一的抽象目录树,通过hdfs协议的路径来访问文件或文件夹
- 由namenode节点来管理目录结构及文件分块信息(元数据),也是集群的主节点,负责维护整个文件系统的目录树以及每一个路径所对应的block信息
- 由datanode节点来管理文件的block存储,也是集群的从(子)节点,每一个block都可以在多个datanode上存储多个副本
二、HDFS工作原理
概述
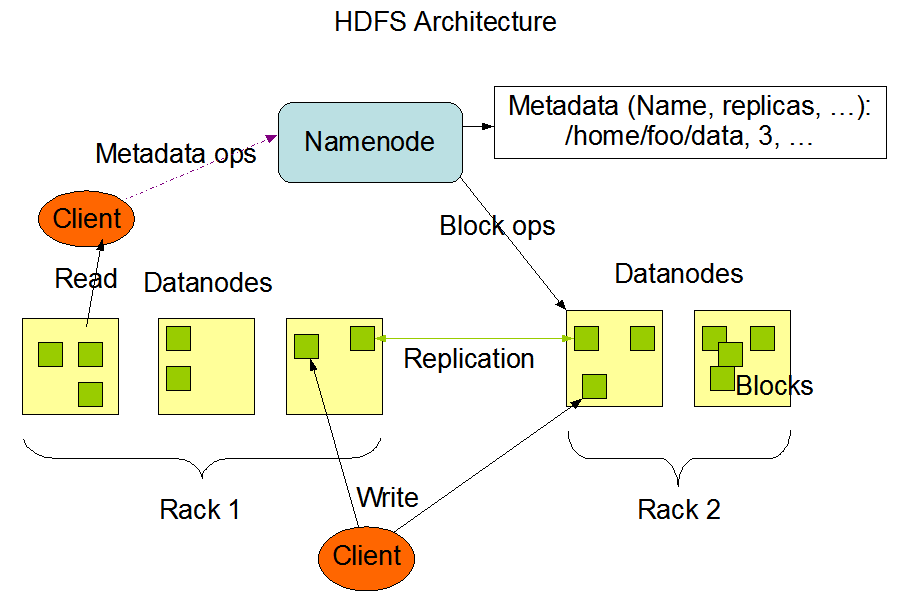
- NameNode负责管理整个文件系统的元数据
- DataNode负责管理用户存储文件的数据块
- 文件会按照预先指定的块大小被切成若干块后分布式存储在若干台DataNode上
- 每一个文件快可以有多个副本,并存放在不同的DataNode上
- DataNode会定期向NameNode汇报自身保存的文件block信息,NameNode负责保持文件的副本数量
- 在用户使用时不需要关心HDFS的内部工作步骤,直接通过一个地址进行操作
使用流修改文件内容时,首先打开一个流,不断的读取文件信息,定位修改,通常不会直接修改
通常是以文件导入的方式将数据导入HDFS,将计算得到的数据(小数据量)进行读取,结果的展示
数据读取过程
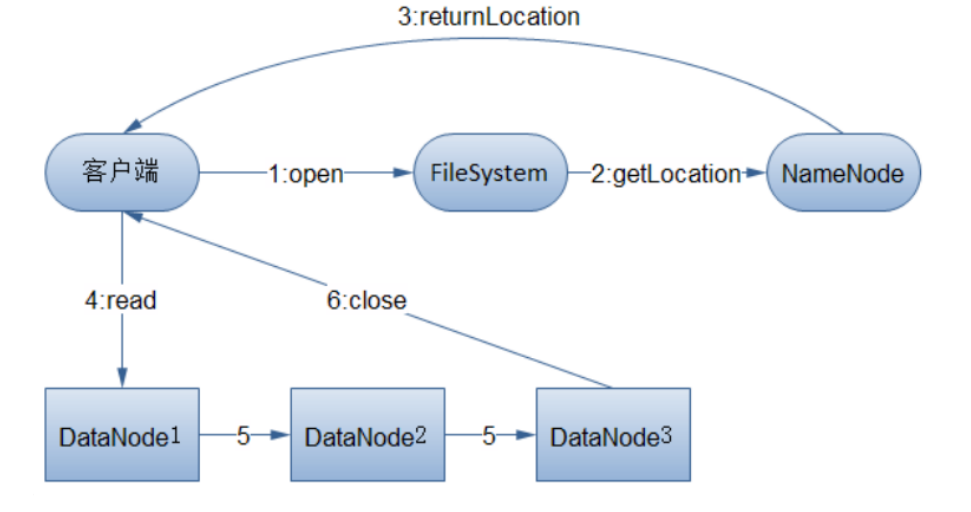
- 客户端通过命令或调用FileSystem对象的open方法打开需要读取的文件
- NameNode接收指令后,确定文件的block的基本信息
- DataNode进行排序,如果客户端就是在一台DataNode上执行则直接从本地读取数据。
- 确定数据节点后会返回一个FSDataInputStream对象,从中读取数据
- 使用read方法以流的方式从文件中读取数据
- 当达到block文件末尾时,FSDataInputStream会关闭当前连接,继续读取下一个block文件
- 循环读取过程,直至读取整个文件,关闭FSDataInputStream
数据写入过程
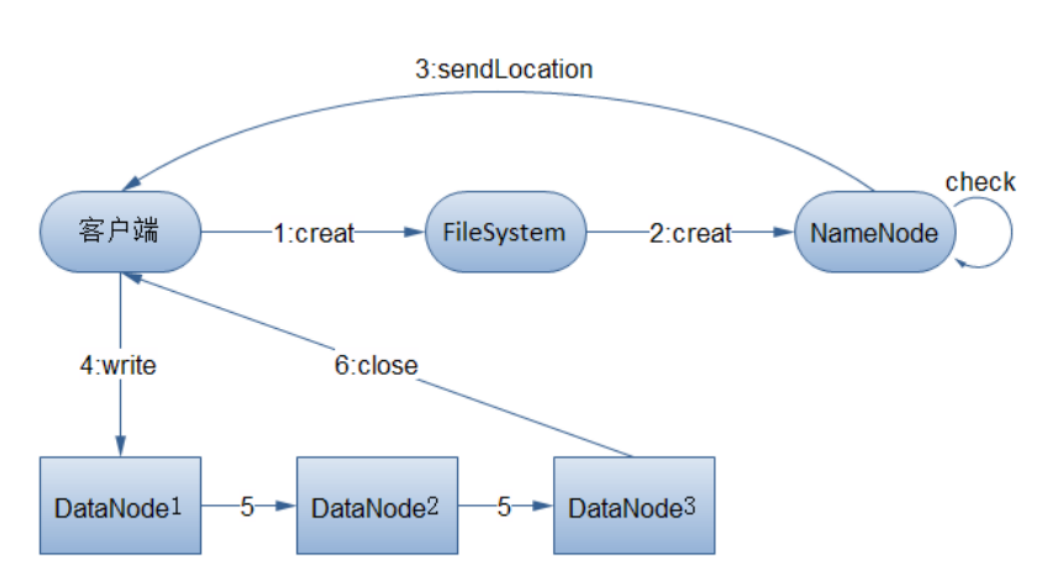
- 客户端通过调用create()方法来请求创建文件
- NameNode会对该操作进行校验,包括文件系统中是否已经存在该文件,以及是否有相应的权限进行创建
- 如果校验通过,NameNode会记录该文件信息,返回一个FSDataOutputStream对象,用于数据写入
- FSDataOutputStream会把要写入的数据分成包的形式,写入到中间队列
- DataStreamer用于将数据包中的数据分别写入到各个DataNode中
- 在FSDataOutputStream中维护了一个packets队列,其中存放了等待被每个DataNode确认的packets信息
- 一个packets信息被移出本队列当且仅当所有的DataNode都确认无误
- 当数据完成后会调用close方法,会flush残留的packets,通知NameNode等待确认信息
Hadoop增删节点
静态添加
停止集群,修改节点配置文件(slaves),启动集群
- 优点:操作简单,改动较少
- 缺点:去要重启集群
- 应用场景:每天有固定的重启时间
动态添加
在集群运行过程中进行变更,在新机器上配置好环境,同步各集群的hosts文件和slaves文件
在新节点中使用如下命令进行启动
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
- 优点:不需要重启集群
- 缺点:改动量较大时比较繁琐
- 应用场景:需要持续不断的提供服务
NameNode详解
负责处理客户端的请求,元数据的查询和修改
启动过程
- 首先将fsimage(镜像载入内存),并执行和editlog相关的各项操作
- 在内存中建立元数据映射,则创建一个新的fsimage文件和一个空的editlog
- 在安全模式下,DataNode会向NameNode发送块列表的最新情况
- 在安全模式中,文件系统对于客户端是只读的
- 完成以上操作后开启监听RPC和HTTP请求,并退出安全模式
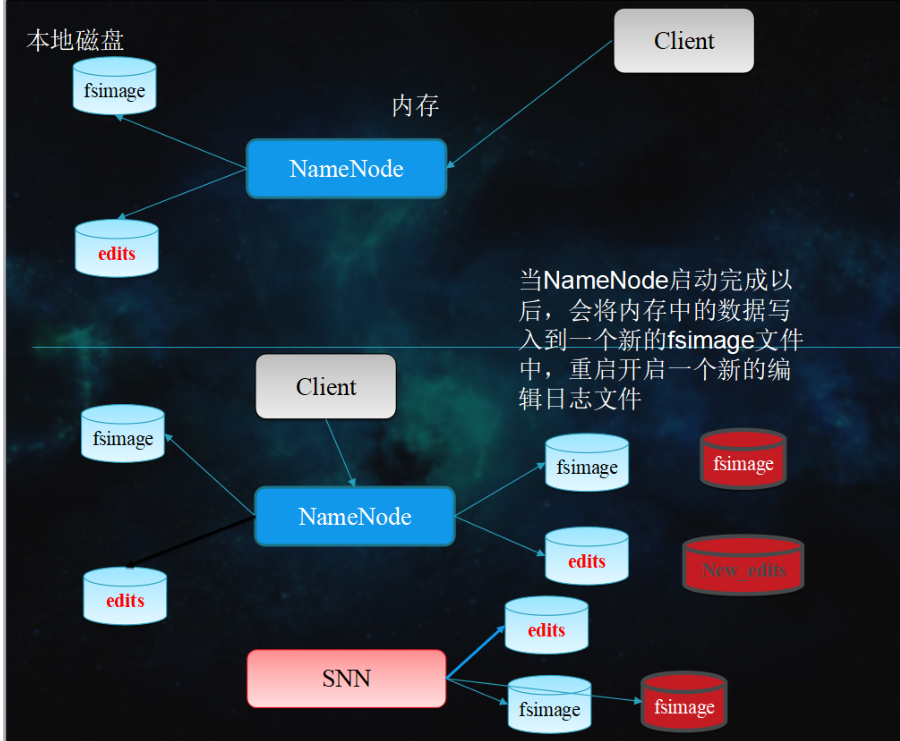
元数据管理
- NameNode的两个重要文件:fsimage-元数据镜像文件,edits-元数据操作日志
- 元数据镜像:内存中为最新的=fsimage+edits
- 定期合并fsimage和edits:由SecondaryNameNode,保证稳定运行以及NameNode重启速度
安全模式
一个新创建的集群不会进入安全模式,重新启动一个已有的集群,通常会有短暂的安全模式时间,用于完成合并和初始化的操作
- 查询当前是否处于安全模式
hadoop dfsadmin -safemode get
- 等待安全模式关闭
hadoop dfsadmin -safemode wait
- 退出安全模式
hadoop dfsadmin -safemode leave
- 启用安全模式
hadoop dfsadmin -safemode enter
三、HDFS命令操作
Web监控
浏览器中输入地址SZ01:50070
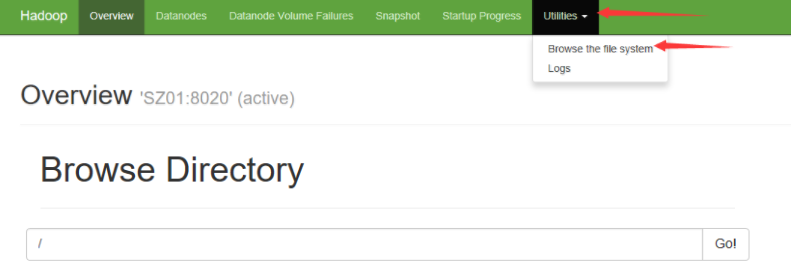
可以在这个网页中查看集群信息等,也可以在上图的位置找到查看hdfs文件系统的页面,可以将hdfs中的文件下载至Windows本地;
在浏览器中直接下载文件时,传输数据的datanode是随机的,通常需要对每一台每一台机器配置hosts映射(Windows下),当机器数量较多时,可以手动修改主机名为IP,再重新发送请求。
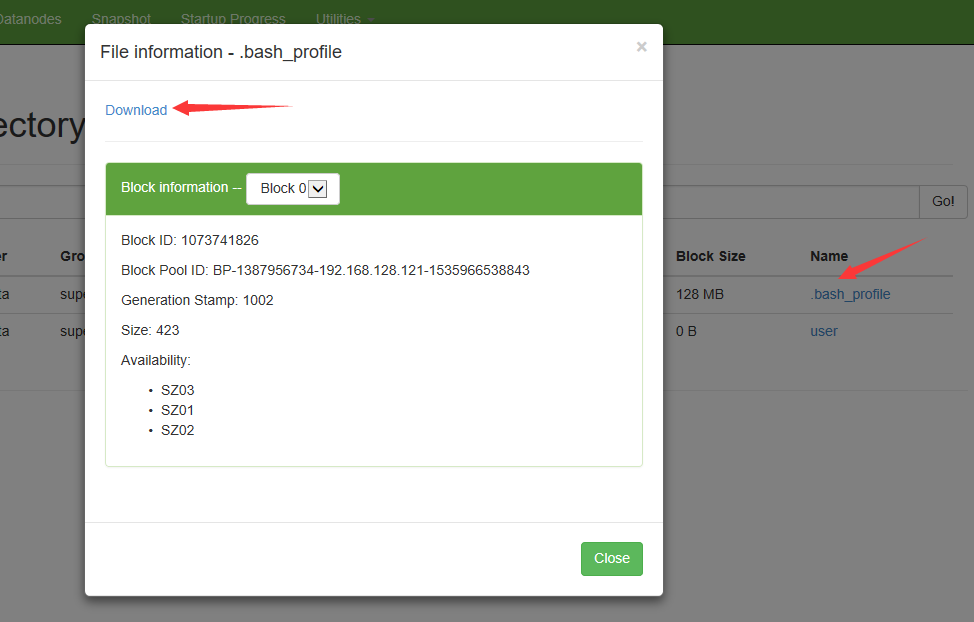
使用命令操作HDFS
两种命令格式:
hadoop fs -command path
hdfs dfs -command path
command为操作命令,上传、下载、删除、查看、移动、复制文件等,命令与Linux下的命令几乎相同
path为操作路径,hdfs根路径为hdfs://host:8020/,使用时可直接简写为/
hdfs也有绝对路径和相对路径,但一般使用时使用绝对路径,即从/开始
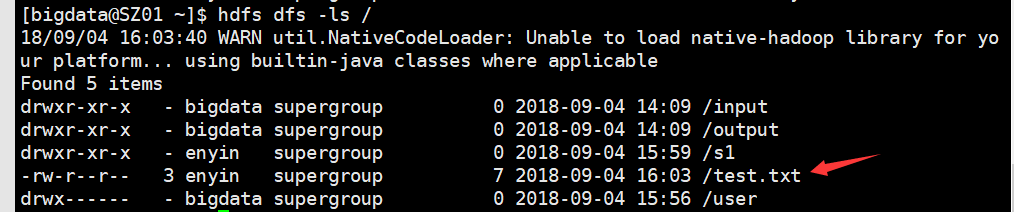
查看hdfs系统中存在的文件的命令:ls
hdfs dfs -ls path:查看path路径下的文件
hdfs dfs -lsr path = hdfs dfs -ls -R path:递归查看path路径下的文件
上传文件至hdfs命令:put(copyFromLocal)
hdfs dfs -put src(Linux文件系统) dest(HDFS文件系统)
hdfs dfs -put .bash_profile /


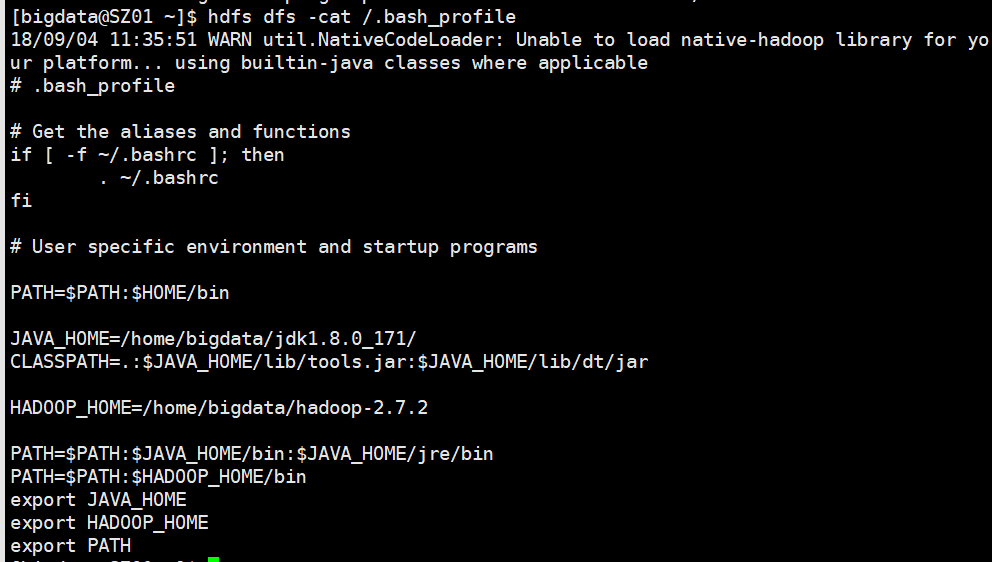
查看hdfs中文件内容:cat
hdfs dfs -cat file
hdfs dfs -cat /.bash_profile
从hdfs下载文件命令:get(copyToLocal)
hdfs dfs -get src(HDFS文件系统) dest(Linux文件系统)
hdfs dfs -get /.bash_profile /tmp


删除hdfs中文件、文件夹命令:rm rmdir
hdfs dfs -rm file:删除文件
hdfs dfs -rmdir emptyDir:删除空文件夹
hdfs dfs -rm -r notEmptyDir:删除非空文件夹
在hdfs-site.xml中配置了删除文件时并不是立即删除,而是现将文件移至某一文件夹,60分钟后彻底删除
hdfs dfs -rm /.bash_profile


创建文件夹:mkdir
hdfs dfs -mkdir dirPathName:指定路径和名字创建文件夹
hdfs dfs -mkdir /input
hdfs dfs -mkdir /output
hdfs dfs -mkdir test

移动文件(夹):mv
hdfs dfs -mv src(源) dest(目标)
hdfs dfs -mv /test.txt /s1/

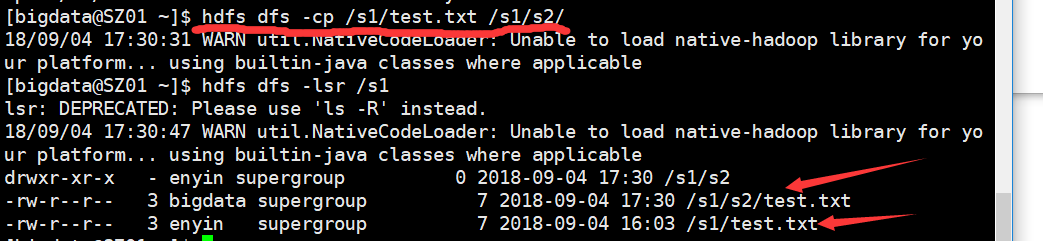
复制文件(夹):cp
hdfs dfs -cp src(源) dest(目标)
hdfs dfs -cp /s1/test.txt /s1/s2/
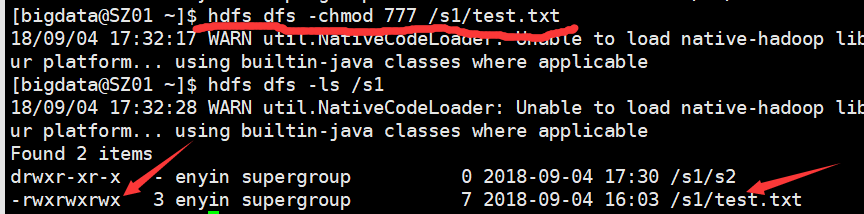
更改文件(夹)权限:chmod
hdfs dfs -chmod [-R] xxx file(dir)
hdfs dfs -chmod 777 /s1/test.txt
四、JAVA操作HDFS
在Windows下通过java操作服务器中的hdfs时,需要进行安装hadoop,配置环境变量,在项目中引入所需jar包,解决环境问题等操作
JUnit单元测试工具
此工具可以直接执行某一个方法:不能有参数,不能有返回值
原理:调用无参的构造方法,再去调用声明测试的方法
使用方法:添加库,在要测试的方法前引入@Test注释,右键运行时选择JUnit Test
通常测试时只会指定一个方法进行测试
使用步骤:右键项目,build Path,configure Build Path,切换至Library,add Library,Junit
- 检验JUnit原理测试代码:

@Test
public void getHomeDir() {
//输出当前家目录
System.out.println(fs.getHomeDirectory());
}
准备
Windows下配置hadoop
将hadoop-2.7.2.tar.gz通过解压缩软件解压至目录(一般解压至软件安装目录)
右键此电脑 -> 高级系统设置 -> 环境变量,在系统变量一栏选择新建
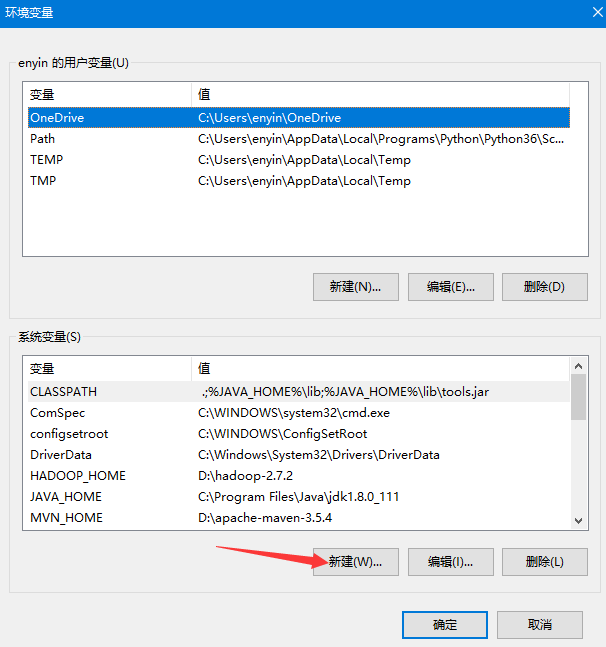
变量名为HADOOP_HOME,变量值为第1步中解压的路径
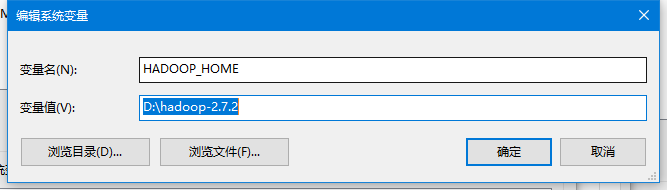
解决运行MapReduce时因环境而报错(为之后编写MapReduce代码做准备)
新建包org.apache.hadoop.io.nativeio
将修改后的NativeIO.java粘贴到包内
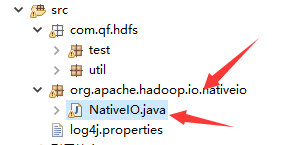
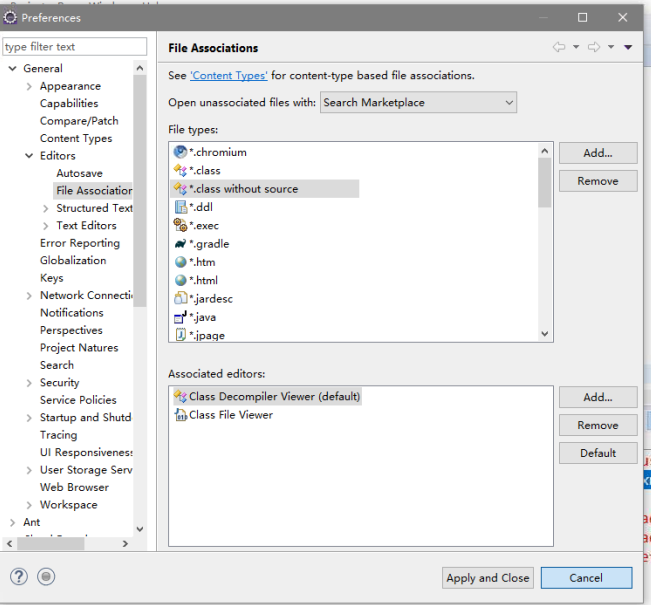
此时import有报错,原因是eclipse默认设置将禁止的引用进行报错,需要进行处理
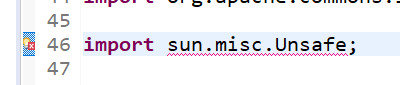
将禁止的引用改成警告,如下图进行设置:
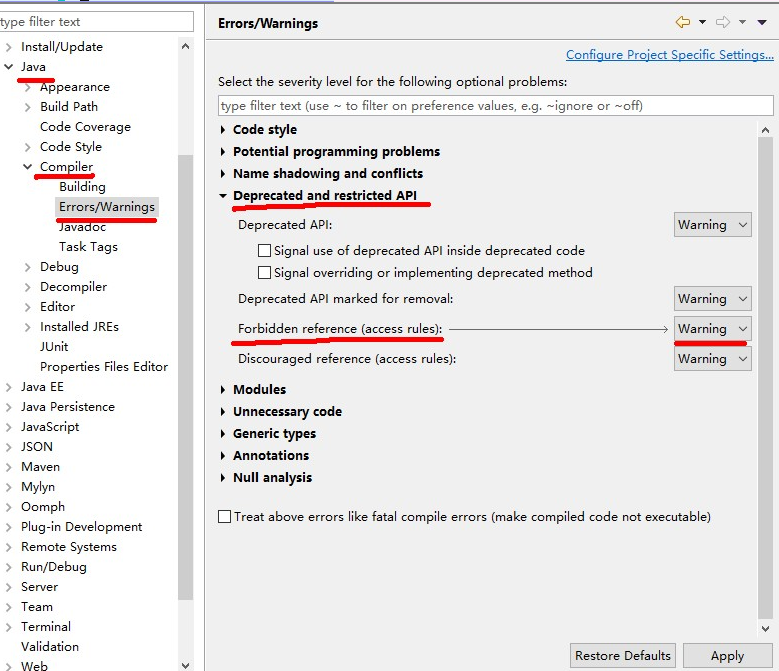
eclipse编写代码
解决环境问题
编写代码前,先将winutil.exe和hadoop.dll等文件拷贝至$HADOOP_HOME/bin目录下,并且将hadoop.dll拷贝至System32及SysWOW64目录下。双击运行winutil.exe,如果没报错即成功,如果报错,则需使用类库修复工具修复(具体可百度方法),完成后重启电脑
压缩包可从点击此处下载
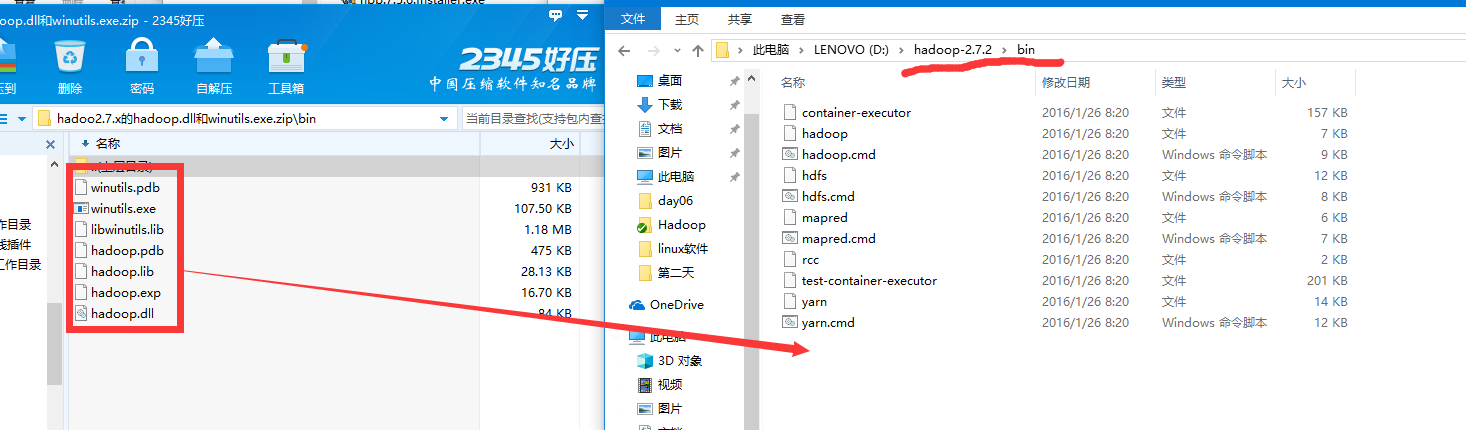
编写代码前的准备
新建java项目,在项目下新建文件夹lib
在hadoop解压目录下拷贝以下jar包粘贴至项目的lib文件夹中
$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.2.jar和hadoop-nfs-2.7.2.jar
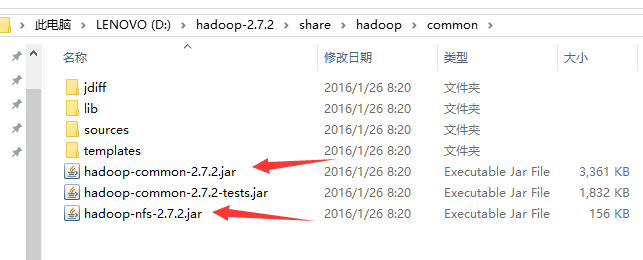
$HADOOP_HOME/share/hadoop/common/lib中全部jar包$HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar和hadoop-hdfs-nfs-2.7.2.jar
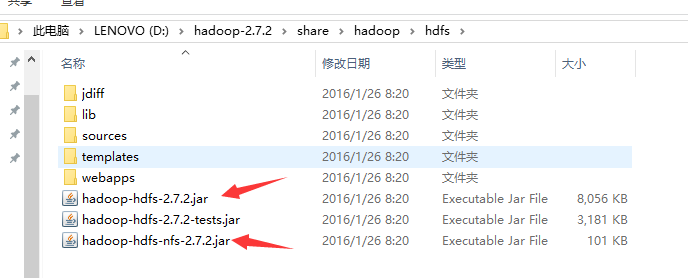 $HADOOP_HOME/share/hadoop/hdfs/lib中全部jar包
$HADOOP_HOME/share/hadoop/hdfs/lib中全部jar包在eclipse中全选lib目录下的jar包,右键选择Build Path -> Add to Build Path(添加至构建路径)
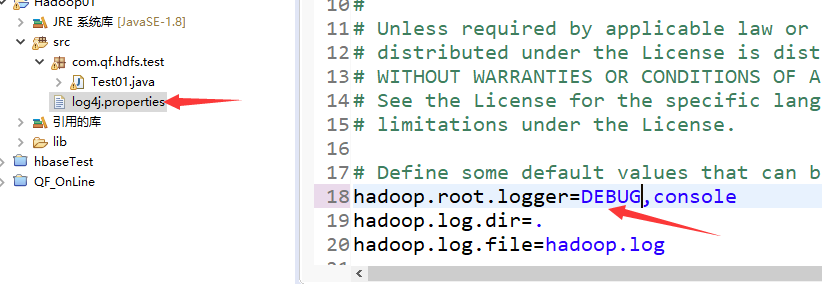
将$HADOOP_HOME/etc/hadoop/log4j.properties拷贝至src根目录下
将第18行中hadoop.root.logger=INFO改成DEBUG,这样在运行项目后输出的信息会以debug信息输出,否则有些报错信息未能输出,不利于调试
编写第一个测试代码,测试连接是否成功
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class Test01 {
// 初始化配置对象
private static Configuration conf = new Configuration();
// 声明需要访问的集群地址
private final static String URI = "hdfs://SZ01:8020/";
// 声明操作文件系统的类
private static FileSystem fs;
static {
try {
// 从制定集群中读取配置
FileSystem.setDefaultUri(conf, URI);
// 使用读取到的配置实例化fs
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// TODO 使用Java操作HDFS
// 输出默认的block块大小
System.out.println(fs.getDefaultBlockSize());
}
}运行成功后输出结果为:
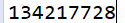
- 下图中的设置为查看源码时使用反编译工具
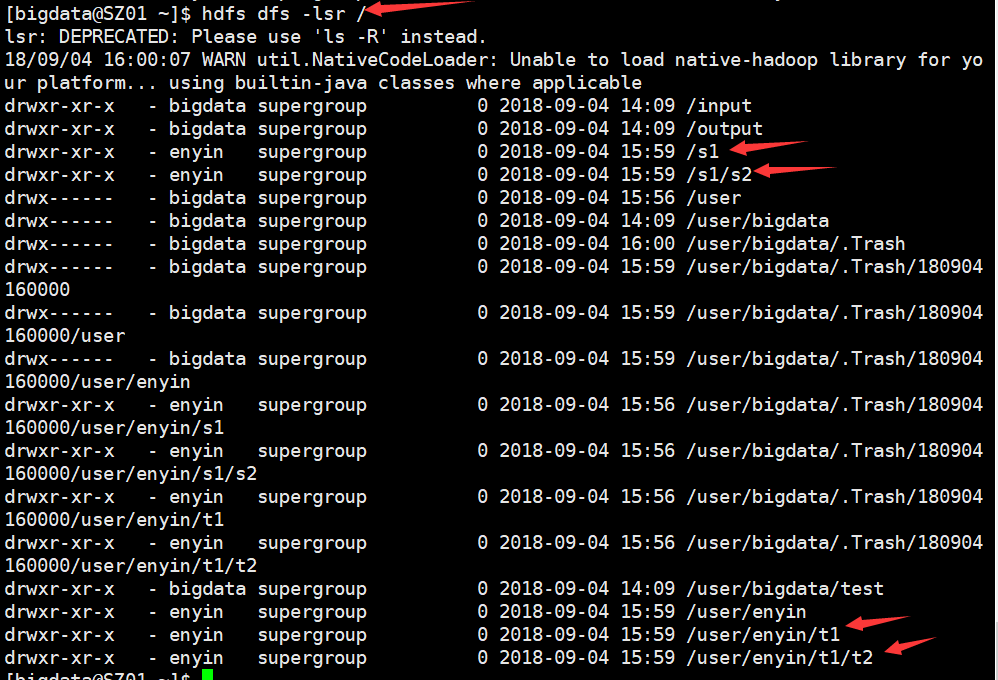
创建多级目录
// 同时创建多级目录
public void mkdirs() {
try {
fs.mkdirs(new Path("t1/t2"));
fs.mkdirs(new Path("/s1/s2"));
} catch (IllegalArgumentException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
上传本地文件至hdfs
上传文件通常是客户端通过web应用进行上传操作,将文件上传到linux本地磁盘,再上传至hdfs(指定删除源文件,指定不覆盖目标文件)
// 上传本地文件至hdfs
public void upLoad() {
try {
// 两个参数:本地文件路径和hdfs目录
fs.copyFromLocalFile(new Path("G://test/test.txt"), new Path("/"));
} catch (IllegalArgumentException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
从hdfs下载文件至本地
// 从hdfs下载文件至本地
public void downLoad() {
try {
fs.copyToLocalFile(false, new Path("/text.txt"), new Path("E://"), true);
} catch (IllegalArgumentException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
HDFSUtil工具类的封装
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSUtil {
/**
* 初始化工具类,指定需要操作的集群
* @param hostName
*/
public HDFSUtil(String hostName) {
URI = "hdfs://" + hostName + ":8020";
try {
// 将URI信息记录到配置项中
FileSystem.setDefaultUri(conf, URI);
// 使用读取到的配置实例化fs
fs = FileSystem.get(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
// 初始化配置对象
private static Configuration conf = new Configuration();
// 声明需要访问的集群地址
private static String URI = "";
// 声明操作文件系统的类
private static FileSystem fs;
/**
* 返回当前用户的家目录
* @return
*/
public String getHomeDir() {
// 当前用户的家目录
return fs.getHomeDirectory().toString();
}
/**
* 创建文件夹
* @param path 完整路径,不需要添加斜杠
* @param useHomeDir 是否在用户家目录中创建
*/
public void mkdirs(String path, boolean useHomeDir) {
// 同时创建多级目录
try {
if (useHomeDir) {
fs.mkdirs(new Path(path));
} else {
fs.mkdirs(new Path("/" + path));
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件上传
* @param delSrc 是否删除源文件
* @param overwrite 是否覆盖目标文件
* @param srcs 源文件路径,可以指定多个路径
* @param dest 目标路径
*/
public void upLoad(boolean delSrc, boolean overwrite, String[] srcs, String dest) {
try {
// fs.copyFromLocalFile(false, src, dst);
// 四个参数,是否删除源文件,是否覆盖目标文件,源路径,目标路径,声明不覆盖时抛出异常(不会发生覆盖)
// fs.copyFromLocalFile(false, false, new Path("E://test.txt"), new Path("/"));
// 上传单个文件时,直接上传
if (srcs.length == 1) {
fs.copyFromLocalFile(delSrc, overwrite, new Path(srcs[0]), new Path("/"));
} else {
// 上传多个文件时,生成所需的Path数组
Path[] paths = new Path[srcs.length];
for (int i = 0; i < srcs.length; i++) {
paths[i] = new Path(srcs[i]);
}
fs.copyFromLocalFile(delSrc, overwrite, paths, new Path("/"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件下载
* @param delSrc 是否删除源文件
* @param src 源文件路径
* @param dest 目标路径
*/
public void downLoad(boolean delSrc,String src,String dest) {
try {
// 四个参数,是否删除源文件,源路径,目标路径,是否使用原生的系统文件系统
fs.copyToLocalFile(delSrc, new Path(src), new Path(dest), true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
五、还原快照后的处理
在集群中单台机器出现了误操作后导致系统不能正常运行,此时需要还原快照,如果没有快照则需重装系统。
还原快照后需要对三台机器的时间进行同步,否则hadoop集群无法进行正常工作。
同步时间的步骤:
所有机器切换至root用户
su - root
打开Xshell的发送键输入到所有会话的功能,输入以下命令
date -s ‘201x-xx-xx xx:xx:xx’
时间同步完成后,重启hadoop进程,即执行以下两步命令
stop-all.sh
start-all.sh
重启hadoop进程成功后,hadoop会对恢复快照的机器尝试自动检测和修复。
如果hadoop自动修复失败,即恢复快照的机器访问hdfs文件系统时跟其他机器访问hdfs所得到的结果不同,则需进行手动修复。
手动修复步骤:
损坏机器与正常机器都进入配置的datanode文件夹
cd hadoop/data/dfs/dn/current/BP-1387956734-192.168.128.121-1535966538843/current/finalized/subdir0/subdir0/
对比损坏机器与正常机器该目录下的文件情况,将正常机器多出来的文件复制到损坏的机器上,复制方式可以通过scp发送,或者Xftp先下载至本地再上传
手动修复后需要重启hadoop进程,此时修复完成。