1、冒泡排序及算法实现
什么是冒泡排序呢?冒泡排序是一种简单的排序方法,它的基本思想是:通过相邻两个元素之间的比较和交换,使较大的元素逐渐从前面移向后面(升序),就像水底下的气泡一样逐渐向上冒泡,所以被称为“冒泡”排序。冒泡排序的最坏时间复杂度为O(n2),平均时间复杂度为O(n2)
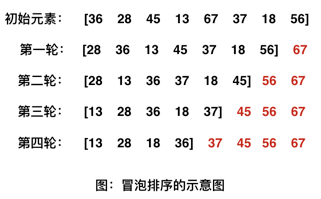
下面以一张图来展示冒泡排序的全过程,其中方括号内为下一轮要排序的元素,方括号后面的第一个元素为本轮排序浮出来的最大元素。
1-1、示意图
1-2、代码
冒泡排序算法的代码实现:
BubbleSort.java
public class BubbleSort {
public static void main(String[] args) {
int[] list = {36, 28, 45, 13, 67, 37, 18, 56};
System.out.println("************冒泡排序************");
System.out.println("排序前:");
display(list);
System.out.println("排序后:");
bubbleSort(list);
display(list);
}
/**
* 遍历打印
*/
public static void display(int[] list) {
System.out.println("********展示开始********");
if (list != null && list.length > 0) {
for (int num :
list) {
System.out.print(num + " ");
}
System.out.println("");
}
System.out.println("********展示结束********");
}
/**
* 冒泡排序算法
*/
public static void bubbleSort(int[] list) {
int temp;
// 做多少轮排序(最多length-1轮)
for (int i = 0; i < list.length - 1; i++) {
// 每一轮比较多少个
for (int j = 0; j < list.length - 1 - i; j++) {
if (list[j] > list[j + 1]) {
// 交换次序
temp = list[j];
list[j] = list[j + 1];
list[j + 1] = temp;
}
}
}
}
}测试结果:
算法分析
冒泡排序算法是所有排序算法中最简单的,在生活中应该也会看到气泡从水里面出来时,越到水面上气泡就会变的越大。在物理上学气压的时候好像也看到过这种现象;其实理解冒泡排序就可以根据这种现象来理解:每一次遍历,都把大的往后面排(当然也可以把小的往后面排),所以每一次都可以把无序中最大的(最小)的元素放到无序的最后面(或者说有序元素的最开始);
基本步骤:
1、外循环是遍历每个元素,每次都放置好一个元素;
2、内循环是比较相邻的两个元素,把大的元素交换到后面;
3、等到第一步中循环好了以后也就说明全部元素排序好了;
时间复杂度
这个时间复杂度还是很好计算的:外循环和内循环以及判断和交换元素的时间开销;
最优的情况也就是开始就已经排序好序了,那么就可以不用交换元素了,则时间花销为:[ n(n-1) ] / 2;所以最优的情况时间复杂度为:O( n^2 );
最差的情况也就是开始的时候元素是逆序的,那么每一次排序都要交换两个元素,则时间花销为:[ 3n(n-1) ] / 2;(其中比上面最优的情况所花的时间就是在于交换元素的三个步骤);所以最差的情况下时间复杂度为:O( n^2 );
综上所述:
最优的时间复杂度为:O( n^2 ) ;有的说 O(n),下面会分析这种情况;
最差的时间复杂度为:O( n^2 );
平均的时间复杂度为:O( n^2 );
最优时间复杂度 n
有很多人说冒泡排序的最优的时间复杂度为:O(n);其实这是在代码中使用一个标志位来判断是否已经排序好的,修改下上面的排序代码:
/** * 冒泡排序算法 */ public static void bubbleSort(int[] list) { int temp; boolean flag=false; // 做多少轮排序(最多length-1轮) for (int i = 0; i < list.length - 1; i++) { flag=false;// 每一轮比较多少个 for (int j = 0; j < list.length - 1 - i; j++) { if (list[j] > list[j + 1]) { // 交换次序 temp = list[j]; list[j] = list[j + 1]; list[j + 1] = temp; flag=true; } } if(!flag){ break; } } }
根据上面的代码可以看出,如果元素已经排序好,那么循环一次就直接退出。或者说元素开始就已经大概有序了,那么这种方法就可以很好减少排序的次数;其实我感觉这种方法也有弊端,比如 要额外的判断下,以及赋值操作;
空间复杂度
空间复杂度就是在交换元素时那个临时变量所占的内存空间;
最优的空间复杂度就是开始元素顺序已经排好了,则空间复杂度为:0;
最差的空间复杂度就是开始元素逆序排序了,则空间复杂度为:O(n);
平均的空间复杂度为:O(1);
2、快速排序及算法实现
快速排序(Quick Sort) 是对冒泡排序的一种改进方法,在冒泡排序中,进行元素的比较和交换是在相邻元素之间进行的,元素每次交换只能移动一个位置,所以比较次数和移动次数较多,效率相对较低。而在快速排序中,元素的比较和交换是从两端向中间进行的,较大的元素一轮就能够交换到后面的位置,而较小的元素一轮就能交换到前面的位置,元素每次移动的距离较远,所以比较次数和移动次数较少,速度较快,故称为“快速排序”。
快速排序的基本思想是:通过一轮排序将待排序元素分割成独立的两部分, 其中一部分的所有元素均比另一部分的所有元素小,然后分别对这两部分的元素继续进行快速排序,以此达到整个序列变成有序序列。快速排序的最坏时间复杂度为O(n2),平均时间复杂度为O(n*log2n)
2-1、示意图

2-2、代码
快速排序算法的代码实现:
QuickSort.java
public class QuickSort {
public static void main(String[] args) {
int[] list = {6, 1, 2, 7, 9, 3, 4, 5, 10, 8};
System.out.println("************快速排序************");
System.out.println("排序前:");
display(list);
System.out.println("排序后:");
quickSort(list, 0, list.length - 1);
display(list);
}
/**
* 快速排序算法
*/
public static void quickSort(int[] list, int left, int right) {
if (left < right) {
// 分割数组,找到分割点
int point = partition(list, left, right);
// 递归调用,对左子数组进行快速排序
quickSort(list, left, point - 1);
// 递归调用,对右子数组进行快速排序
quickSort(list, point + 1, right);
}
}
/**
* 分割数组,找到分割点
*/
public static int partition(int[] list, int left, int right) {
// 用数组的第一个元素作为基准数
int first = list[left];
while (left < right) {
while (left < right && list[right] >= first) {
right--;
}
list[left] = list[right]; //比基准小的记录移到低端
while (left < right && list[left] <= first) {
left++;
}
list[right] = list[left]; //比基准大的记录移到高端
}
list[left] = first; //基准记录
// 返回分割点所在的位置
return left;
}
/**
* 遍历打印
*/
public static void display(int[] list) {
System.out.println("********展示开始********");
if (list != null && list.length > 0) {
for (int num :
list) {
System.out.print(num + " ");
}
System.out.println("");
}
System.out.println("********展示结束********");
}
}测试结果:

算法分析
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
我看了下网上有些bolg写排序算法,有的是理解错误了;有的呢是太过于复杂;还有的呢就干脆是用临时数组,而不是就地排序。当然我的也并没有多好,只是提够一种思路;
说说我的基本思路:每次都取数组的第一个元素作为比较标准(哨兵元素),凡是大于这个哨兵元素的都放在它的右边,凡是小于这个哨兵元素的都放在它的左边;
大概的步骤:
1、判断参数条件,其实这是递归的出口;
2、以数组的第一个元素为哨兵元素,让其他元素和它比较大小;(记住这时候第一个元素位置是口的,因为里面的值被作为哨兵元素保存起来了)
3、开始从数组尾部往前循环得到一个小于哨兵元素的 元素A ,把该 元素A 放到第一个元素位置(也就是哨兵元素位置上,因为哨兵元素位置是空的);(这时候要记住 元素A 的位置是空的了)
4、开始从数组头部往后循环得到一个大于哨兵元素的 元素B ,把该 元素B 放在上一步中移出的 元素A 的位置上;
5、依次循环上面3、4步,直到最后一个元素为止,那么最后一个元素就存放哨兵元素了。
6、把小于哨兵元素的那一部分和大于哨兵元素的那一部分分别递归调用本函数,依次递归排序好所有元素;
时间复杂度
快速排序涉及到递归调用,所以该算法的时间复杂度还需要从递归算法的复杂度开始说起;
递归算法的时间复杂度公式:T[n] = aT[n/b] + f(n) ;对于递归算法的时间复杂度这里就不展开来说了;
最优情况下时间复杂度
快速排序最优的情况就是每一次取到的元素都刚好平分整个数组(很显然我上面的不是);
此时的时间复杂度公式则为:T[n] = 2T[n/2] + f(n);T[n/2]为平分后的子数组的时间复杂度,f[n] 为平分这个数组时所花的时间;
下面来推算下,在最优的情况下快速排序时间复杂度的计算(用迭代法):
T[n] = 2T[n/2] + n ----------------第一次递归
令:n = n/2 = 2 { 2 T[n/4] + (n/2) } + n ----------------第二次递归
= 2^2 T[ n/ (2^2) ] + 2n
令:n = n/(2^2) = 2^2 { 2 T[n/ (2^3) ] + n/(2^2)} + 2n ----------------第三次递归
= 2^3 T[ n/ (2^3) ] + 3n
......................................................................................
令:n = n/( 2^(m-1) ) = 2^m T[1] + mn ----------------第m次递归(m次后结束)
当最后平分的不能再平分时,也就是说把公式一直往下跌倒,到最后得到T[1]时,说明这个公式已经迭代完了(T[1]是常量了)。
得到:T[n/ (2^m) ] = T[1] ===>> n = 2^m ====>> m = logn;
T[n] = 2^m T[1] + mn ;其中m = logn;
T[n] = 2^(logn) T[1] + nlogn = n T[1] + nlogn = n + nlogn ;其中n为元素个数
又因为当n >= 2时:nlogn >= n (也就是logn > 1),所以取后面的 nlogn;
综上所述:快速排序最优的情况下时间复杂度为:O( nlogn )
最差情况下时间复杂度
最差的情况就是每一次取到的元素就是数组中最小/最大的,这种情况其实就是冒泡排序了(每一次都排好一个元素的顺序)
这种情况时间复杂度就好计算了,就是冒泡排序的时间复杂度:T[n] = n * (n-1) = n^2 + n;
综上所述:快速排序最差的情况下时间复杂度为:O( n^2 )
平均时间复杂度
快速排序的平均时间复杂度也是:O(nlogn)
空间复杂度
其实这个空间复杂度不太好计算,因为有的人使用的是非就地排序,那样就不好计算了(因为有的人用到了辅助数组,所以这就要计算到你的元素个数了);我就分析下就地快速排序的空间复杂度吧;
首先就地快速排序使用的空间是O(1)的,也就是个常数级;而真正消耗空间的就是递归调用了,因为每次递归就要保持一些数据;
最优的情况下空间复杂度为:O(logn) ;每一次都平分数组的情况
最差的情况下空间复杂度为:O( n ) ;退化为冒泡排序的情况